 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Makes a Difference from Counterfactual Examples and Gradient Supervision
Apr 20, 2020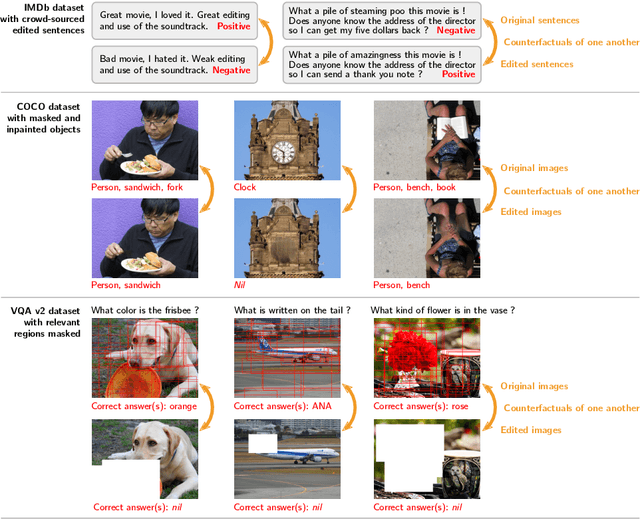
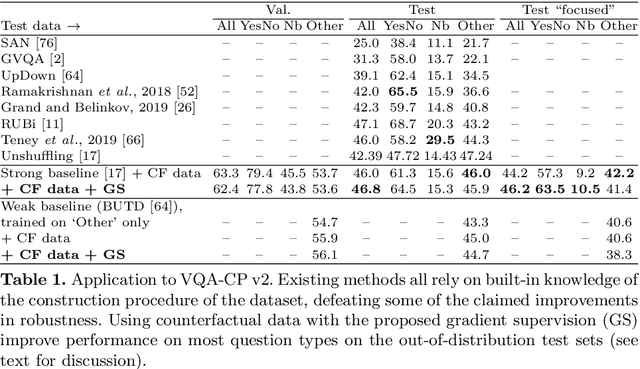
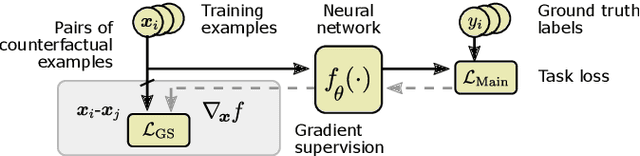
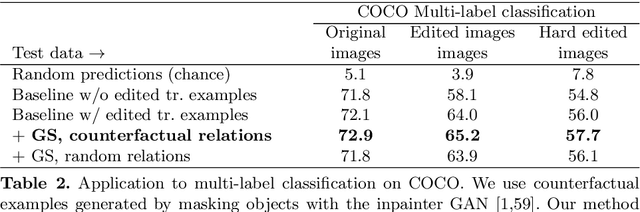
One of the primary challenges limiting the applicability of deep learning is its susceptibility to learning spurious correlations rather than the underlying mechanisms of the task of interest. The resulting failure to generalise cannot be addressed by simply using more data from the same distribution. We propose an auxiliary training objective that improves the generalization capabilities of neural networks by leveraging an overlooked supervisory signal found in existing datasets. We use pairs of minimally-different examples with different labels, a.k.a counterfactual or contrasting examples, which provide a signal indicative of the underlying causal structure of the task. We show that such pairs can be identified in a number of existing datasets in computer vision (visual question answering, multi-label image classification) and natural language processing (sentiment analysis, natural language inference). The new training objective orients the gradient of a model's decision function with pairs of counterfactual examples. Models trained with this technique demonstrate improved performance on out-of-distribution test sets.
Self-trained Deep Ordinal Regression for End-to-End Video Anomaly Detection
Mar 15, 2020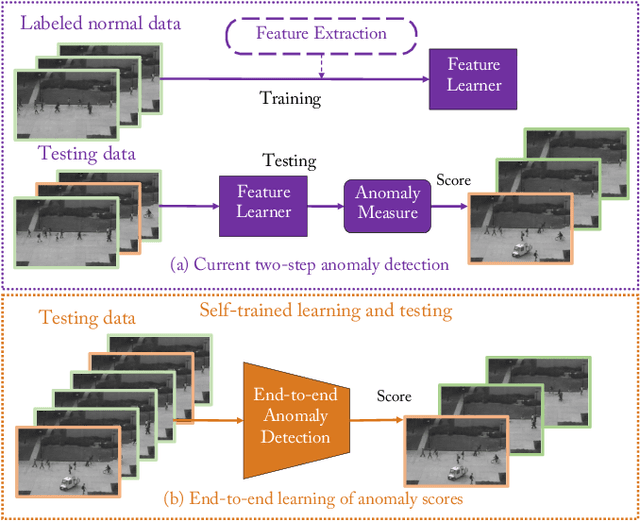
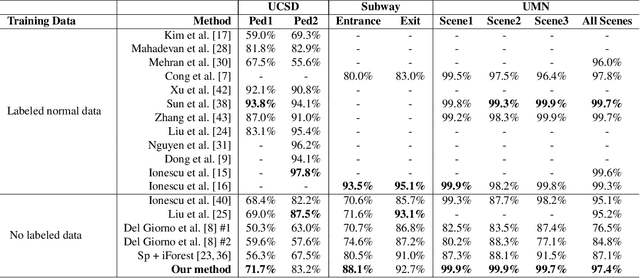
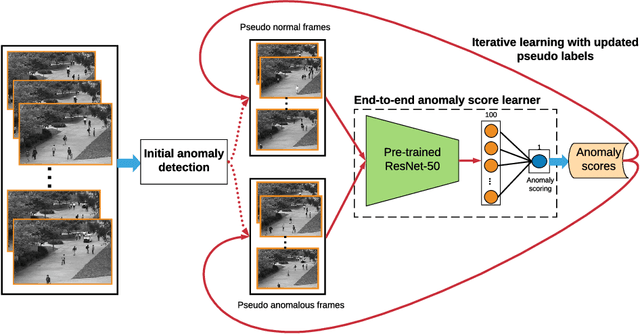
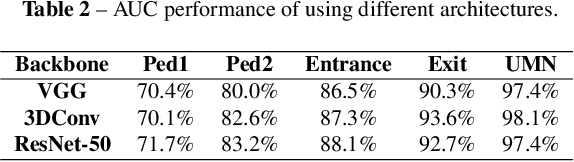
Video anomaly detection is of critical practical importance to a variety of real applications because it allows human attention to be focused on events that are likely to be of interest, in spite of an otherwise overwhelming volume of video. We show that applying self-trained deep ordinal regression to video anomaly detection overcomes two key limitations of existing methods, namely, 1) being highly dependent on manually labeled normal training data; and 2) sub-optimal feature learning. By formulating a surrogate two-class ordinal regression task we devise an end-to-end trainable video anomaly detection approach that enables joint representation learning and anomaly scoring without manually labeled normal/abnormal data. Experiments on eight real-world video scenes show that our proposed method outperforms state-of-the-art methods that require no labeled training data by a substantial margin, and enables easy and accurate localization of the identified anomalies. Furthermore, we demonstrate that our method offers effective human-in-the-loop anomaly detection which can be critical in applications where anomalies are rare and the false-negative cost is high.
Unshuffling Data for Improved Generalization
Mar 01, 2020
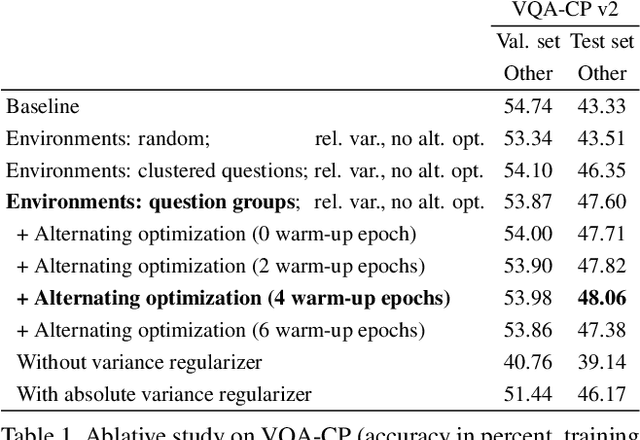
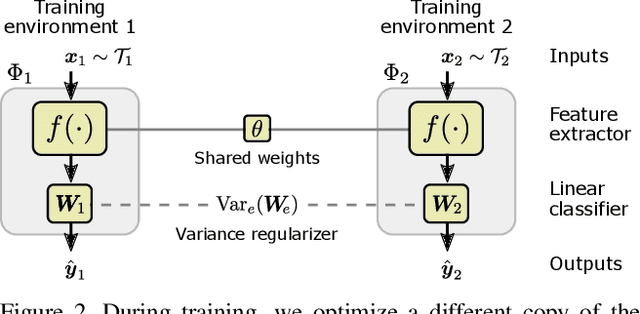
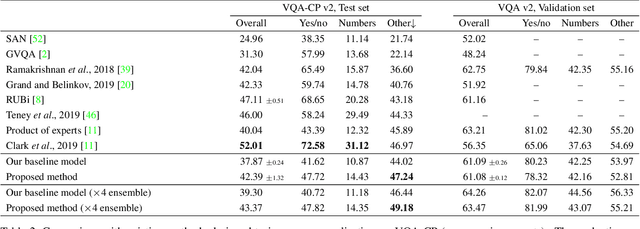
The inability to generalize beyond the distribution of a training set is at the core of practical limits of machine learning. We show that the common practice of mixing and shuffling training examples when training deep neural networks is not optimal. On the opposite, partitioning the training data into non-i.i.d. subsets can serve to guide the model to rely on reliable statistical patterns while ignoring spurious correlations in the training data. We demonstrate multiple use cases where these subsets are built using unsupervised clustering, prior knowledge, or other meta-data from existing datasets. The approach is supported by recent results on a causal view of generalization, it is simple to apply, and it demonstrably improves generalization. Applied to the task of visual question answering, we obtain state-of-the-art performance on VQA-CP. We also show improvements over data augmentation using equivalent questions on GQA. Finally, we show a small improvement when training a model simultaneously on VQA v2 and Visual Genome, treating them as two distinct environments rather than one aggregated training set.
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
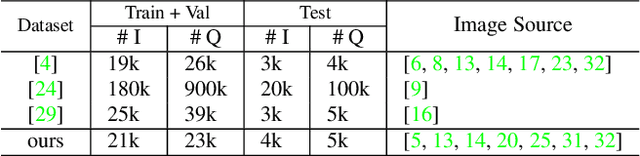

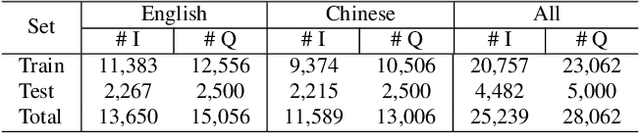
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
Learning to Zoom-in via Learning to Zoom-out: Real-world Super-resolution by Generating and Adapting Degradation
Jan 08, 2020
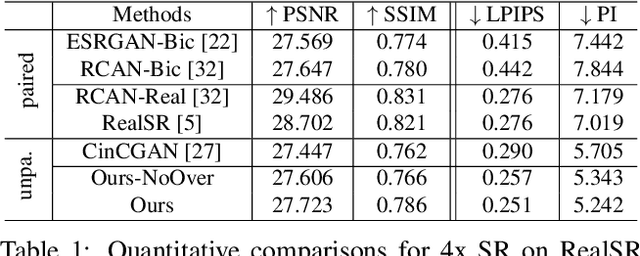

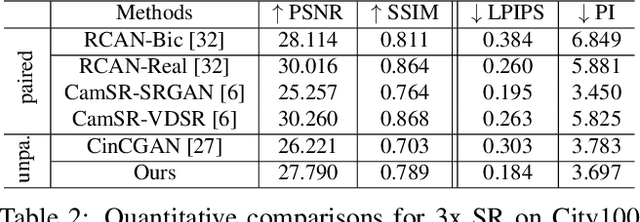
Most learning-based super-resolution (SR) methods aim to recover high-resolution (HR) image from a given low-resolution (LR) image via learning on LR-HR image pairs. The SR methods learned on synthetic data do not perform well in real-world, due to the domain gap between the artificially synthesized and real LR images. Some efforts are thus taken to capture real-world image pairs. The captured LR-HR image pairs usually suffer from unavoidable misalignment, which hampers the performance of end-to-end learning, however. Here, focusing on the real-world SR, we ask a different question: since misalignment is unavoidable, can we propose a method that does not need LR-HR image pairing and alignment at all and utilize real images as they are? Hence we propose a framework to learn SR from an arbitrary set of unpaired LR and HR images and see how far a step can go in such a realistic and "unsupervised" setting. To do so, we firstly train a degradation generation network to generate realistic LR images and, more importantly, to capture their distribution (i.e., learning to zoom out). Instead of assuming the domain gap has been eliminated, we minimize the discrepancy between the generated data and real data while learning a degradation adaptive SR network (i.e., learning to zoom in). The proposed unpaired method achieves state-of-the-art SR results on real-world images, even in the datasets that favor the paired-learning methods more.
Deep Anomaly Detection with Deviation Networks
Nov 19, 2019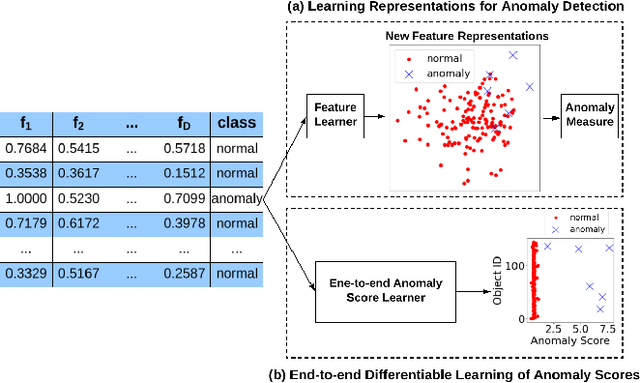
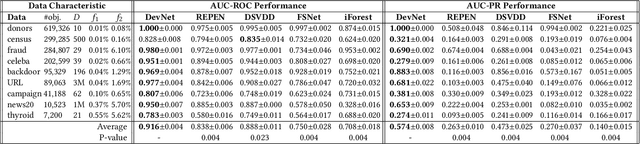
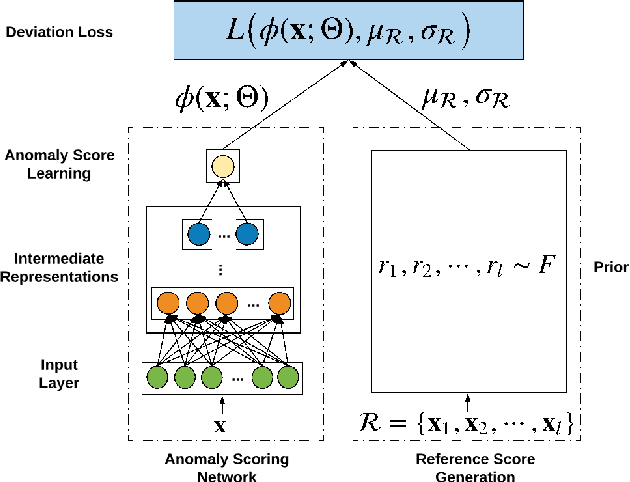
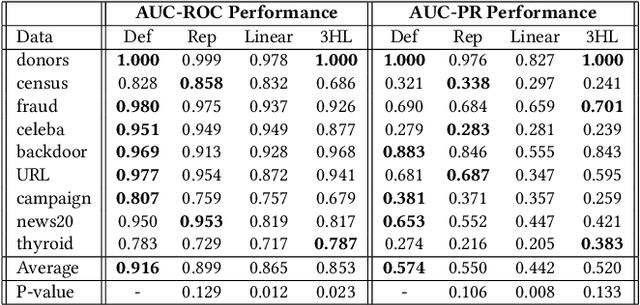
Although deep learning has been applied to successfully address many data mining problems, relatively limited work has been done on deep learning for anomaly detection. Existing deep anomaly detection methods, which focus on learning new feature representations to enable downstream anomaly detection methods, perform indirect optimization of anomaly scores, leading to data-inefficient learning and suboptimal anomaly scoring. Also, they are typically designed as unsupervised learning due to the lack of large-scale labeled anomaly data. As a result, they are difficult to leverage prior knowledge (e.g., a few labeled anomalies) when such information is available as in many real-world anomaly detection applications. This paper introduces a novel anomaly detection framework and its instantiation to address these problems. Instead of representation learning, our method fulfills an end-to-end learning of anomaly scores by a neural deviation learning, in which we leverage a few (e.g., multiple to dozens) labeled anomalies and a prior probability to enforce statistically significant deviations of the anomaly scores of anomalies from that of normal data objects in the upper tail. Extensive results show that our method can be trained substantially more data-efficiently and achieves significantly better anomaly scoring than state-of-the-art competing methods.
Weakly-supervised Deep Anomaly Detection with Pairwise Relation Learning
Oct 30, 2019
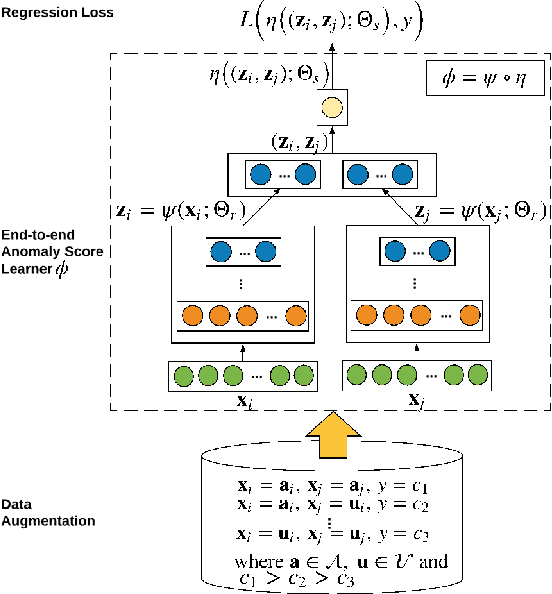
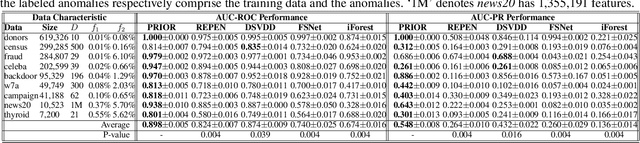
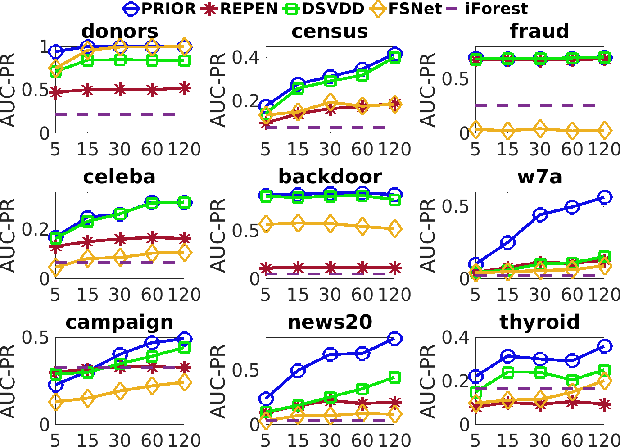
This paper studies a rarely explored but critical anomaly detection problem: weakly-supervised anomaly detection with limited labeled anomalies and a large unlabeled data set. This problem is very important because it (i) enables anomaly-informed modeling which helps identify anomalies of interests and address the notorious high false positives in unsupervised anomaly detection, and (ii) eliminates the reliance on large-scale and complete labeled anomaly data in fully-supervised settings. However, the problem is especially challenging since we have only limited labeled data for a single class, and moreover, the seen anomalies often cannot cover all types of anomalies (i.e., unseen anomalies). We address this problem by formulating the problem as a pairwise relation learning task. Particularly, our approach defines a two-stream ordinal regression network to learn the relation of randomly selected instance pairs, i.e., whether the instance pair contains labeled anomalies or just unlabeled data instances. The resulting model leverages both the labeled and unlabeled data to effectively augment the data and learn generalized representations of both normality and abnormality. Extensive empirical results show that our approach (i) significantly outperforms state-of-the-art competing methods in detecting both seen and unseen anomalies and (ii) is substantially more data-efficient.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019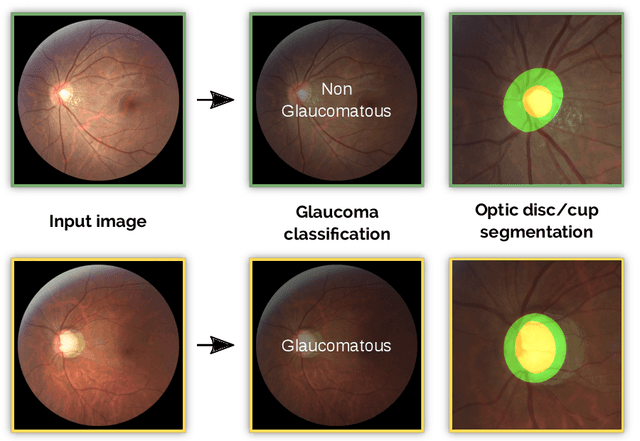
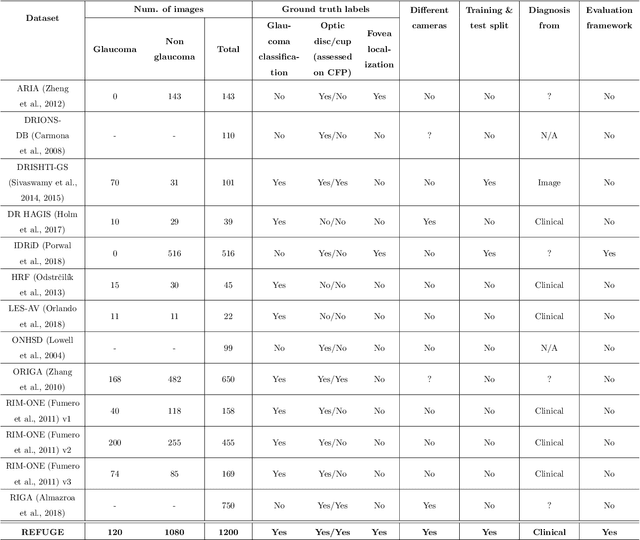

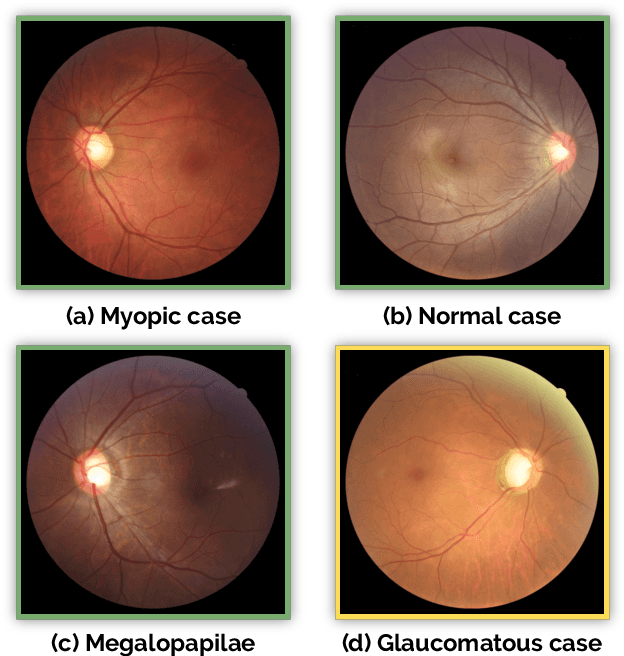
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.
On Incorporating Semantic Prior Knowlegde in Deep Learning Through Embedding-Space Constraints
Sep 30, 2019
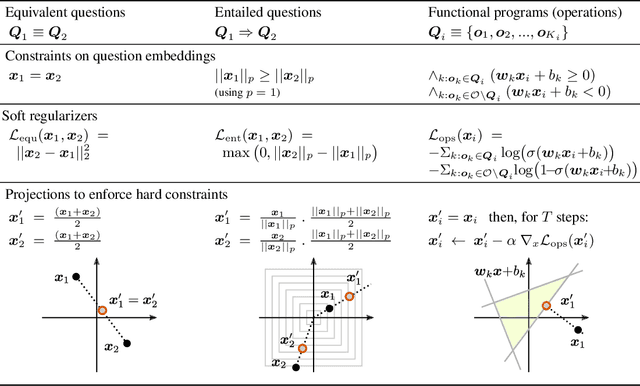
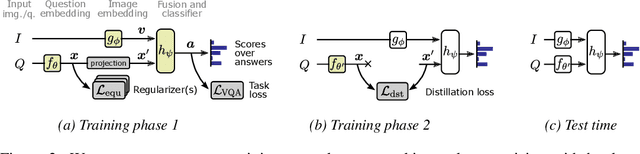
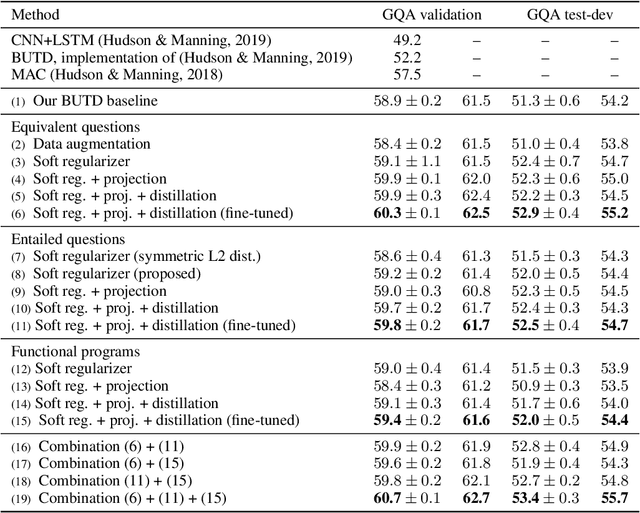
The knowledge that humans hold about a problem often extends far beyond a set of training data and output labels. While the success of deep learning mostly relies on supervised training, important properties cannot be inferred efficiently from end-to-end annotations alone, for example causal relations or domain-specific invariances. We present a general technique to supplement supervised training with prior knowledge expressed as relations between training instances. We illustrate the method on the task of visual question answering to exploit various auxiliary annotations, including relations of equivalence and of logical entailment between questions. Existing methods to use these annotations, including auxiliary losses and data augmentation, cannot guarantee the strict inclusion of these relations into the model since they require a careful balancing against the end-to-end objective. Our method uses these relations to shape the embedding space of the model, and treats them as strict constraints on its learned representations. In the context of VQA, this approach brings significant improvements in accuracy and robustness, in particular over the common practice of incorporating the constraints as a soft regularizer. We also show that incorporating this type of prior knowledge with our method brings consistent improvements, independently from the amount of supervised data used. It demonstrates the value of an additional training signal that is otherwise difficult to extract from end-to-end annotations alone.
V-PROM: A Benchmark for Visual Reasoning Using Visual Progressive Matrices
Jul 29, 2019
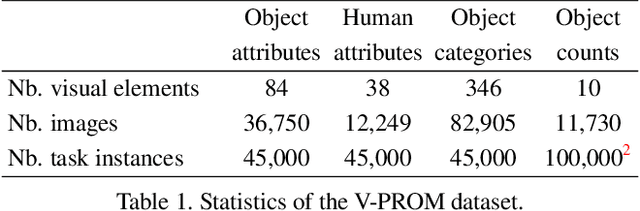

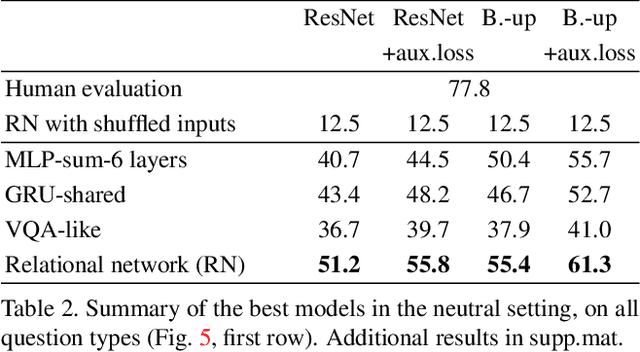
One of the primary challenges faced by deep learning is the degree to which current methods exploit superficial statistics and dataset bias, rather than learning to generalise over the specific representations they have experienced. This is a critical concern because generalisation enables robust reasoning over unseen data, whereas leveraging superficial statistics is fragile to even small changes in data distribution. To illuminate the issue and drive progress towards a solution, we propose a test that explicitly evaluates abstract reasoning over visual data. We introduce a large-scale benchmark of visual questions that involve operations fundamental to many high-level vision tasks, such as comparisons of counts and logical operations on complex visual properties. The benchmark directly measures a method's ability to infer high-level relationships and to generalise them over image-based concepts. It includes multiple training/test splits that require controlled levels of generalization. We evaluate a range of deep learning architectures, and find that existing models, including those popular for vision-and-language tasks, are unable to solve seemingly-simple instances. Models using relational networks fare better but leave substantial room for improvement.