 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnshuffling Data for Improved Generalization
Paper and Code

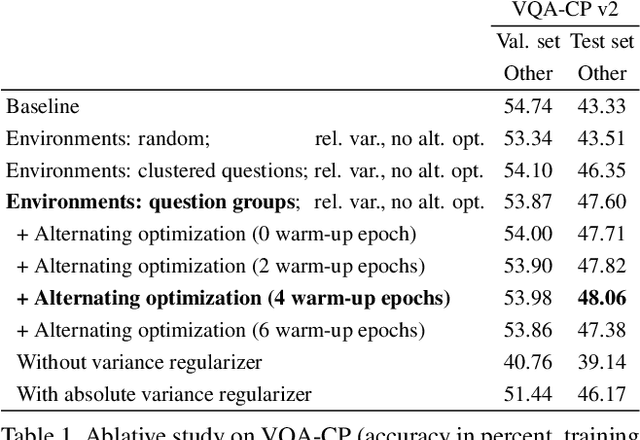
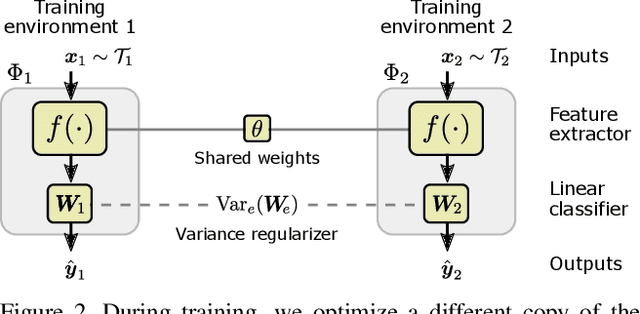
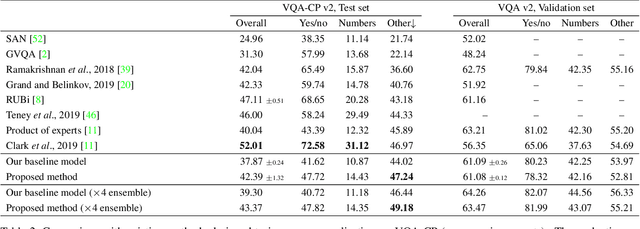
The inability to generalize beyond the distribution of a training set is at the core of practical limits of machine learning. We show that the common practice of mixing and shuffling training examples when training deep neural networks is not optimal. On the opposite, partitioning the training data into non-i.i.d. subsets can serve to guide the model to rely on reliable statistical patterns while ignoring spurious correlations in the training data. We demonstrate multiple use cases where these subsets are built using unsupervised clustering, prior knowledge, or other meta-data from existing datasets. The approach is supported by recent results on a causal view of generalization, it is simple to apply, and it demonstrably improves generalization. Applied to the task of visual question answering, we obtain state-of-the-art performance on VQA-CP. We also show improvements over data augmentation using equivalent questions on GQA. Finally, we show a small improvement when training a model simultaneously on VQA v2 and Visual Genome, treating them as two distinct environments rather than one aggregated training set.