 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023



Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Dec 15, 2022Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations
Nov 08, 2022



We present SpeechMatrix, a large-scale multilingual corpus of speech-to-speech translations mined from real speech of European Parliament recordings. It contains speech alignments in 136 language pairs with a total of 418 thousand hours of speech. To evaluate the quality of this parallel speech, we train bilingual speech-to-speech translation models on mined data only and establish extensive baseline results on EuroParl-ST, VoxPopuli and FLEURS test sets. Enabled by the multilinguality of SpeechMatrix, we also explore multilingual speech-to-speech translation, a topic which was addressed by few other works. We also demonstrate that model pre-training and sparse scaling using Mixture-of-Experts bring large gains to translation performance. The mined data and models are freely available.
Bridging Speech and Textual Pre-trained Models with Unsupervised ASR
Nov 06, 2022Spoken language understanding (SLU) is a task aiming to extract high-level semantics from spoken utterances. Previous works have investigated the use of speech self-supervised models and textual pre-trained models, which have shown reasonable improvements to various SLU tasks. However, because of the mismatched modalities between speech signals and text tokens, previous methods usually need complex designs of the frameworks. This work proposes a simple yet efficient unsupervised paradigm that connects speech and textual pre-trained models, resulting in an unsupervised speech-to-semantic pre-trained model for various tasks in SLU. To be specific, we propose to use unsupervised automatic speech recognition (ASR) as a connector that bridges different modalities used in speech and textual pre-trained models. Our experiments show that unsupervised ASR itself can improve the representations from speech self-supervised models. More importantly, it is shown as an efficient connector between speech and textual pre-trained models, improving the performances of five different SLU tasks. Notably, on spoken question answering, we reach the state-of-the-art result over the challenging NMSQA benchmark.
On The Robustness of Self-Supervised Representations for Spoken Language Modeling
Sep 30, 2022
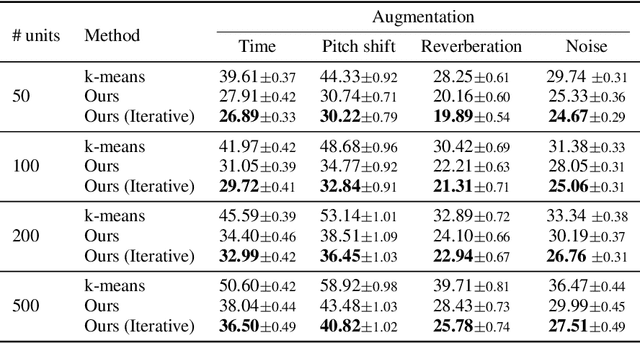
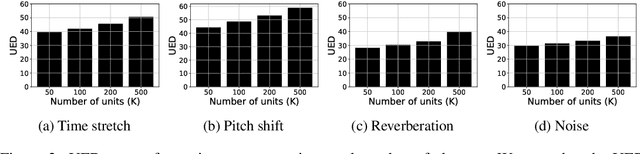
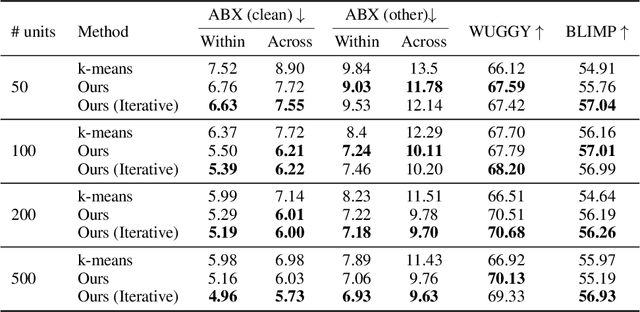
Self-supervised representations have been extensively studied for discriminative and generative tasks. However, their robustness capabilities have not been extensively investigated. This work focuses on self-supervised representations for spoken generative language models. First, we empirically demonstrate how current state-of-the-art speech representation models lack robustness to basic signal variations that do not alter the spoken information. To overcome this, we propose an effective and efficient method to learn robust self-supervised speech representation for generative spoken language modeling. The proposed approach is based on applying a set of signal transformations to the speech signal and optimizing the model using an iterative pseudo-labeling scheme. Our method significantly improves over the evaluated baselines when considering encoding metrics. We additionally evaluate our method on the speech-to-speech translation task. We consider Spanish-English and French-English conversions and empirically demonstrate the benefits of following the proposed approach.
Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation
Apr 06, 2022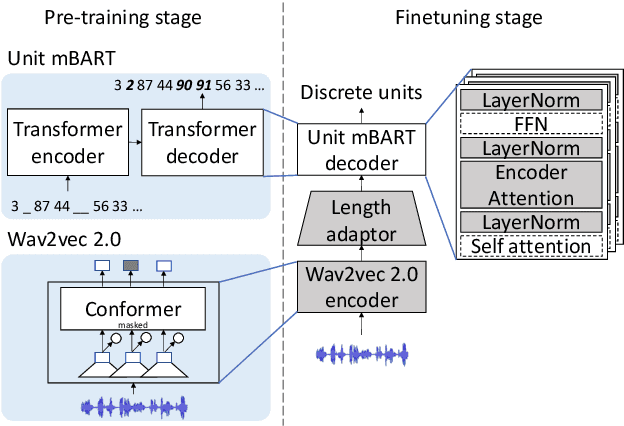
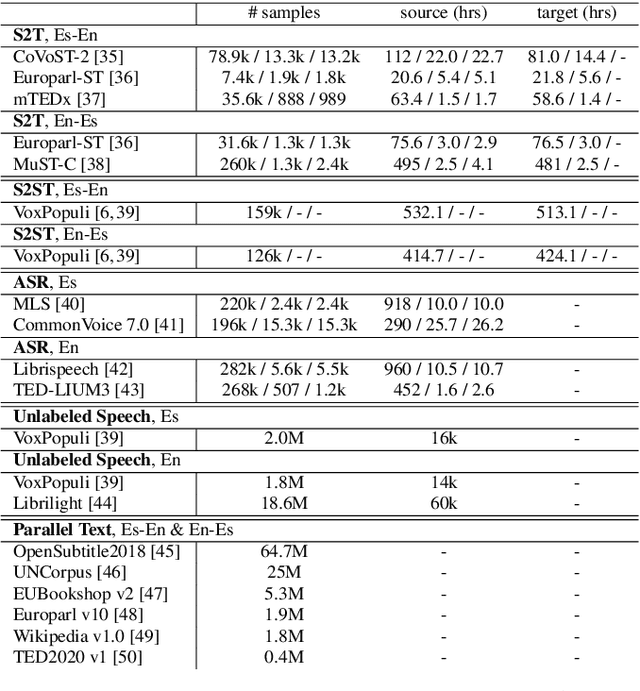
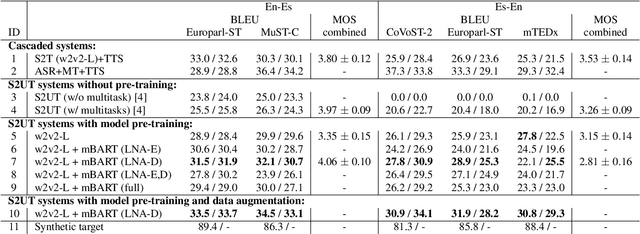

Direct speech-to-speech translation (S2ST) models suffer from data scarcity issues as there exists little parallel S2ST data, compared to the amount of data available for conventional cascaded systems that consist of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS) synthesis. In this work, we explore self-supervised pre-training with unlabeled speech data and data augmentation to tackle this issue. We take advantage of a recently proposed speech-to-unit translation (S2UT) framework that encodes target speech into discrete representations, and transfer pre-training and efficient partial finetuning techniques that work well for speech-to-text translation (S2T) to the S2UT domain by studying both speech encoder and discrete unit decoder pre-training. Our experiments show that self-supervised pre-training consistently improves model performance compared with multitask learning with a BLEU gain of 4.3-12.0 under various data setups, and it can be further combined with data augmentation techniques that apply MT to create weakly supervised training data. Audio samples are available at: https://facebookresearch.github.io/speech_translation/enhanced_direct_s2st_units/index.html .
textless-lib: a Library for Textless Spoken Language Processing
Feb 15, 2022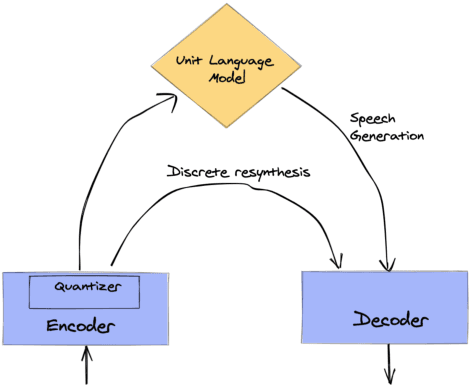
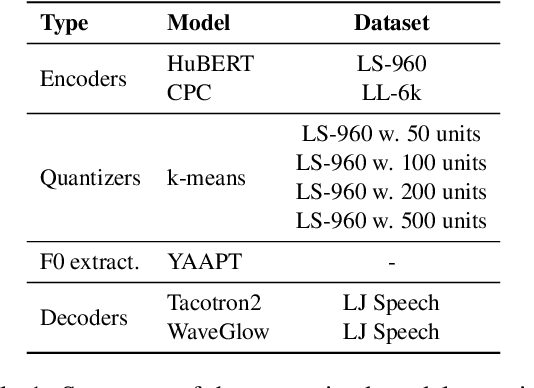
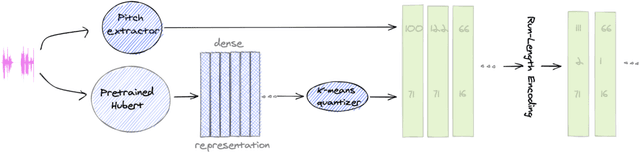
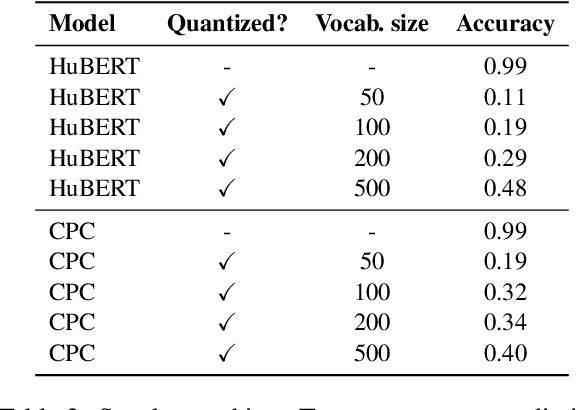
Textless spoken language processing research aims to extend the applicability of standard NLP toolset onto spoken language and languages with few or no textual resources. In this paper, we introduce textless-lib, a PyTorch-based library aimed to facilitate research in this research area. We describe the building blocks that the library provides and demonstrate its usability by discuss three different use-case examples: (i) speaker probing, (ii) speech resynthesis and compression, and (iii) speech continuation. We believe that textless-lib substantially simplifies research the textless setting and will be handful not only for speech researchers but also for the NLP community at large. The code, documentation, and pre-trained models are available at https://github.com/facebookresearch/textlesslib/ .
Flashlight: Enabling Innovation in Tools for Machine Learning
Jan 29, 2022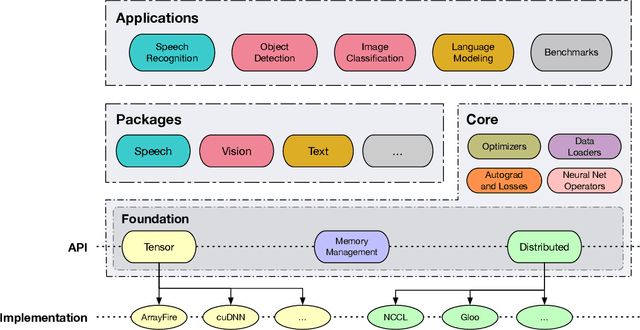
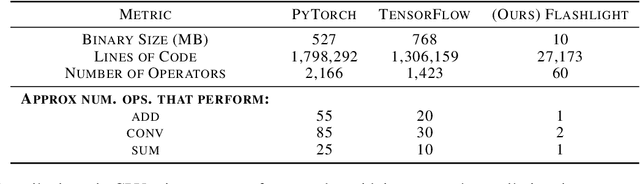
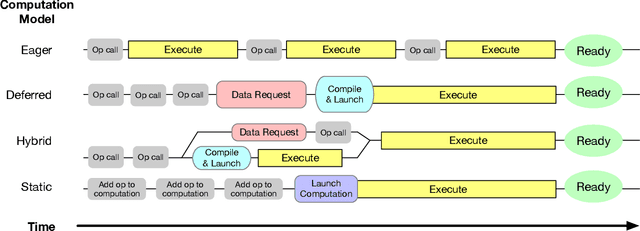
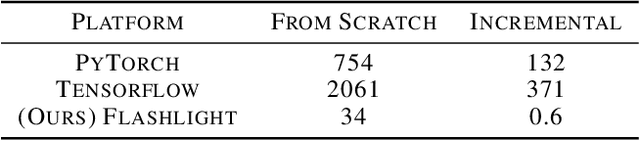
As the computational requirements for machine learning systems and the size and complexity of machine learning frameworks increases, essential framework innovation has become challenging. While computational needs have driven recent compiler, networking, and hardware advancements, utilization of those advancements by machine learning tools is occurring at a slower pace. This is in part due to the difficulties involved in prototyping new computational paradigms with existing frameworks. Large frameworks prioritize machine learning researchers and practitioners as end users and pay comparatively little attention to systems researchers who can push frameworks forward -- we argue that both are equally important stakeholders. We introduce Flashlight, an open-source library built to spur innovation in machine learning tools and systems by prioritizing open, modular, customizable internals and state-of-the-art, research-ready models and training setups across a variety of domains. Flashlight allows systems researchers to rapidly prototype and experiment with novel ideas in machine learning computation and has low overhead, competing with and often outperforming other popular machine learning frameworks. We see Flashlight as a tool enabling research that can benefit widely used libraries downstream and bring machine learning and systems researchers closer together.
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
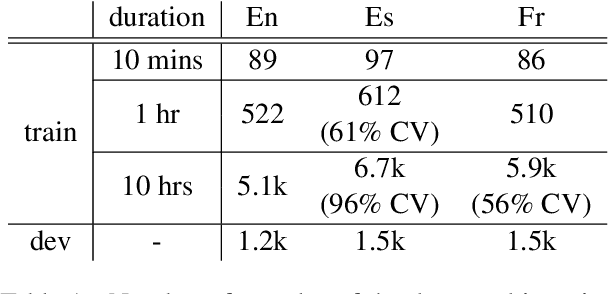
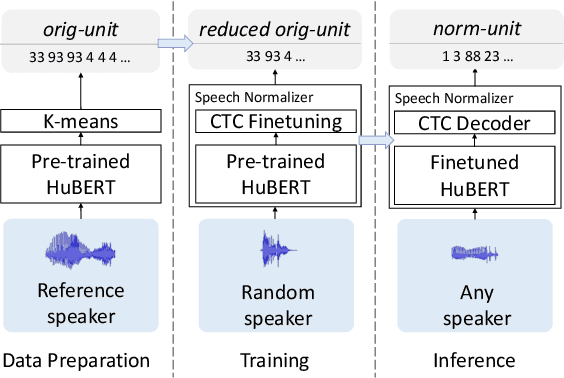
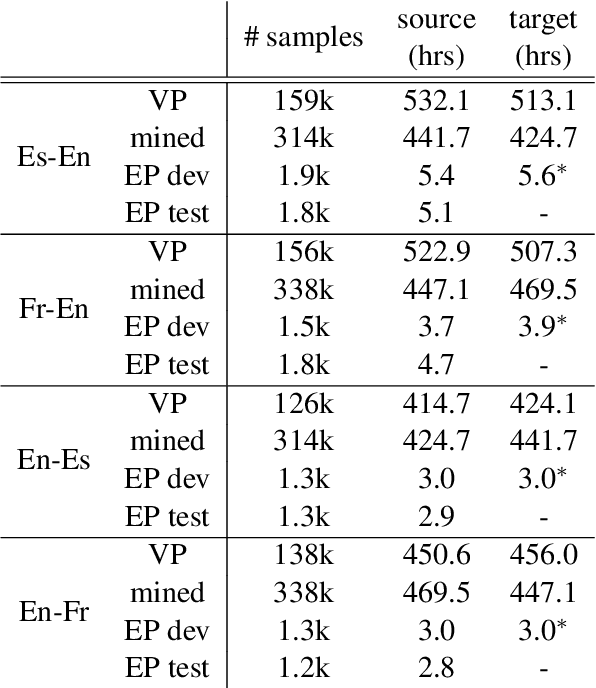
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.