 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Domain-Specific Enhancements for a Neural Foley Synthesizer
Sep 08, 2023



Foley sound synthesis refers to the creation of authentic, diegetic sound effects for media, such as film or radio. In this study, we construct a neural Foley synthesizer capable of generating mono-audio clips across seven predefined categories. Our approach introduces multiple enhancements to existing models in the text-to-audio domain, with the goal of enriching the diversity and acoustic characteristics of the generated foleys. Notably, we utilize a pre-trained encoder that retains acoustical and musical attributes in intermediate embeddings, implement class-conditioning to enhance differentiability among foley classes in their intermediate representations, and devise an innovative transformer-based architecture for optimizing self-attention computations on very large inputs without compromising valuable information. Subsequent to implementation, we present intermediate outcomes that surpass the baseline, discuss practical challenges encountered in achieving optimal results, and outline potential pathways for further research.
Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations
May 23, 2023In this paper, we introduce the imprecise label learning (ILL) framework, a unified approach to handle various imprecise label configurations, which are commonplace challenges in machine learning tasks. ILL leverages an expectation-maximization (EM) algorithm for the maximum likelihood estimation (MLE) of the imprecise label information, treating the precise labels as latent variables. Compared to previous versatile methods attempting to infer correct labels from the imprecise label information, our ILL framework considers all possible labeling imposed by the imprecise label information, allowing a unified solution to deal with any imprecise labels. With comprehensive experimental results, we demonstrate that ILL can seamlessly adapt to various situations, including partial label learning, semi-supervised learning, noisy label learning, and a mixture of these settings. Notably, our simple method surpasses the existing techniques for handling imprecise labels, marking the first unified framework with robust and effective performance across various imprecise labels. We believe that our approach has the potential to significantly enhance the performance of machine learning models on tasks where obtaining precise labels is expensive and complicated. We hope our work will inspire further research on this topic with an open-source codebase release.
Deep PackGen: A Deep Reinforcement Learning Framework for Adversarial Network Packet Generation
May 18, 2023



Recent advancements in artificial intelligence (AI) and machine learning (ML) algorithms, coupled with the availability of faster computing infrastructure, have enhanced the security posture of cybersecurity operations centers (defenders) through the development of ML-aided network intrusion detection systems (NIDS). Concurrently, the abilities of adversaries to evade security have also increased with the support of AI/ML models. Therefore, defenders need to proactively prepare for evasion attacks that exploit the detection mechanisms of NIDS. Recent studies have found that the perturbation of flow-based and packet-based features can deceive ML models, but these approaches have limitations. Perturbations made to the flow-based features are difficult to reverse-engineer, while samples generated with perturbations to the packet-based features are not playable. Our methodological framework, Deep PackGen, employs deep reinforcement learning to generate adversarial packets and aims to overcome the limitations of approaches in the literature. By taking raw malicious network packets as inputs and systematically making perturbations on them, Deep PackGen camouflages them as benign packets while still maintaining their functionality. In our experiments, using publicly available data, Deep PackGen achieved an average adversarial success rate of 66.4\% against various ML models and across different attack types. Our investigation also revealed that more than 45\% of the successful adversarial samples were out-of-distribution packets that evaded the decision boundaries of the classifiers. The knowledge gained from our study on the adversary's ability to make specific evasive perturbations to different types of malicious packets can help defenders enhance the robustness of their NIDS against evolving adversarial attacks.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Exploiting Contextual Structure to Generate Useful Auxiliary Tasks
Mar 09, 2023Reinforcement learning requires interaction with an environment, which is expensive for robots. This constraint necessitates approaches that work with limited environmental interaction by maximizing the reuse of previous experiences. We propose an approach that maximizes experience reuse while learning to solve a given task by generating and simultaneously learning useful auxiliary tasks. To generate these tasks, we construct an abstract temporal logic representation of the given task and leverage large language models to generate context-aware object embeddings that facilitate object replacements. Counterfactual reasoning and off-policy methods allow us to simultaneously learn these auxiliary tasks while solving the given target task. We combine these insights into a novel framework for multitask reinforcement learning and experimentally show that our generated auxiliary tasks share similar underlying exploration requirements as the given task, thereby maximizing the utility of directed exploration. Our approach allows agents to automatically learn additional useful policies without extra environment interaction.
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021
Lang2LTL: Translating Natural Language Commands to Temporal Robot Task Specification
Feb 22, 2023



Natural language provides a powerful modality to program robots to perform temporal tasks. Linear temporal logic (LTL) provides unambiguous semantics for formal descriptions of temporal tasks. However, existing approaches cannot accurately and robustly translate English sentences to their equivalent LTL formulas in unseen environments. To address this problem, we propose Lang2LTL, a novel modular system that leverages pretrained large language models to first extract referring expressions from a natural language command, then ground the expressions to real-world landmarks and objects, and finally translate the command into an LTL task specification for the robot. It enables any robotic system to interpret natural language navigation commands without additional training, provided that it tracks its position and has a semantic map with landmarks labeled with free-form text. We demonstrate the state-of-the-art ability to generalize to multi-scale navigation domains such as OpenStreetMap (OSM) and CleanUp World (a simulated household environment). Lang2LTL achieves an average accuracy of 88.4% in translating challenging LTL formulas in 22 unseen OSM environments as evaluated on a new corpus of over 10,000 commands, 22 times better than the previous SoTA. Without modification, the best performing Lang2LTL model on the OSM dataset can translate commands in CleanUp World with 82.8% accuracy. As a part of our proposed comprehensive evaluation procedures, we collected a new labeled dataset of English commands representing 2,125 unique LTL formulas, the largest ever dataset of natural language commands to LTL specifications for robotic tasks with the most diverse LTL formulas, 40 times more than previous largest dataset. Finally, we integrated Lang2LTL with a planner to command a quadruped mobile robot to perform multi-step navigational tasks in an analog real-world environment created in the lab.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023



Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
Deep VULMAN: A Deep Reinforcement Learning-Enabled Cyber Vulnerability Management Framework
Aug 03, 2022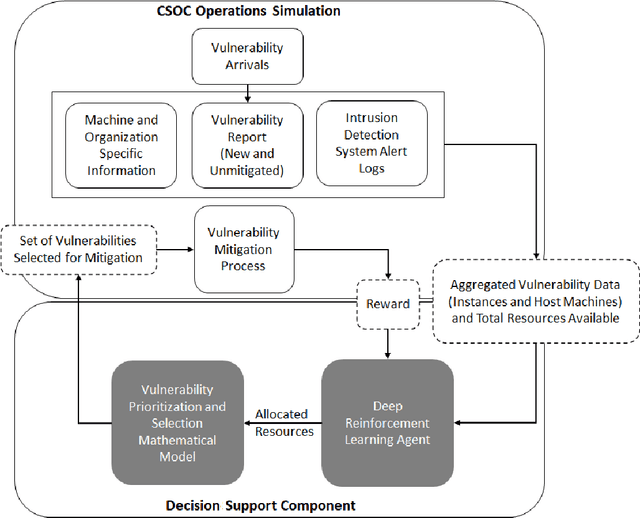
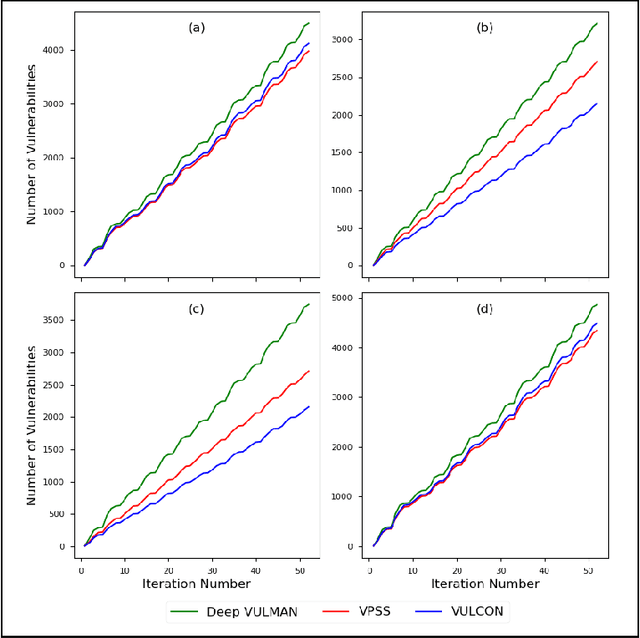
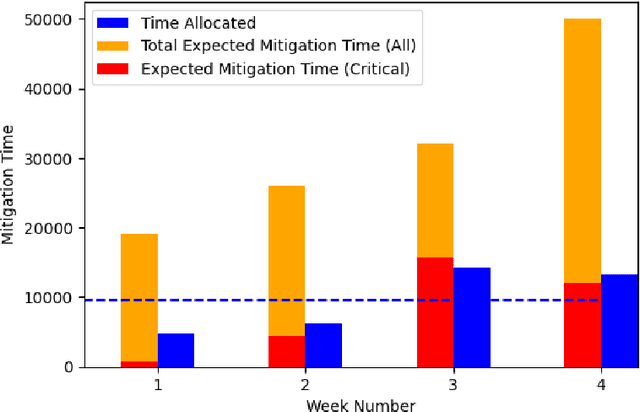
Cyber vulnerability management is a critical function of a cybersecurity operations center (CSOC) that helps protect organizations against cyber-attacks on their computer and network systems. Adversaries hold an asymmetric advantage over the CSOC, as the number of deficiencies in these systems is increasing at a significantly higher rate compared to the expansion rate of the security teams to mitigate them in a resource-constrained environment. The current approaches are deterministic and one-time decision-making methods, which do not consider future uncertainties when prioritizing and selecting vulnerabilities for mitigation. These approaches are also constrained by the sub-optimal distribution of resources, providing no flexibility to adjust their response to fluctuations in vulnerability arrivals. We propose a novel framework, Deep VULMAN, consisting of a deep reinforcement learning agent and an integer programming method to fill this gap in the cyber vulnerability management process. Our sequential decision-making framework, first, determines the near-optimal amount of resources to be allocated for mitigation under uncertainty for a given system state and then determines the optimal set of prioritized vulnerability instances for mitigation. Our proposed framework outperforms the current methods in prioritizing the selection of important organization-specific vulnerabilities, on both simulated and real-world vulnerability data, observed over a one-year period.
Skill Transfer for Temporally-Extended Task Specifications
Jun 10, 2022
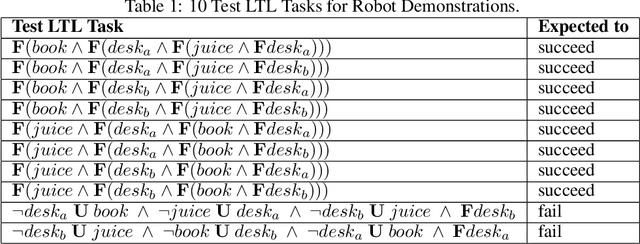
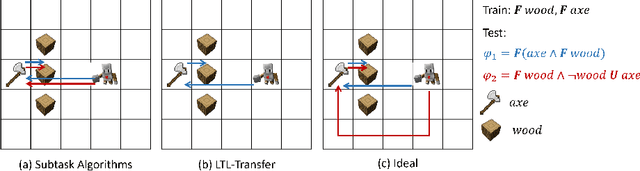
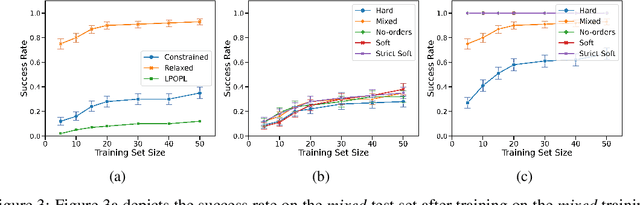
Deploying robots in real-world domains, such as households and flexible manufacturing lines, requires the robots to be taskable on demand. Linear temporal logic (LTL) is a widely-used specification language with a compositional grammar that naturally induces commonalities across tasks. However, the majority of prior research on reinforcement learning with LTL specifications treats every new formula independently. We propose LTL-Transfer, a novel algorithm that enables subpolicy reuse across tasks by segmenting policies for training tasks into portable transition-centric skills capable of satisfying a wide array of unseen LTL specifications while respecting safety-critical constraints. Our experiments in a Minecraft-inspired domain demonstrate the capability of LTL-Transfer to satisfy over 90% of 500 unseen tasks while training on only 50 task specifications and never violating a safety constraint. We also deployed LTL-Transfer on a quadruped mobile manipulator in a household environment to show its ability to transfer to many fetch and delivery tasks in a zero-shot fashion.