 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Manipulation via Visual Target Localization
Mar 15, 2022
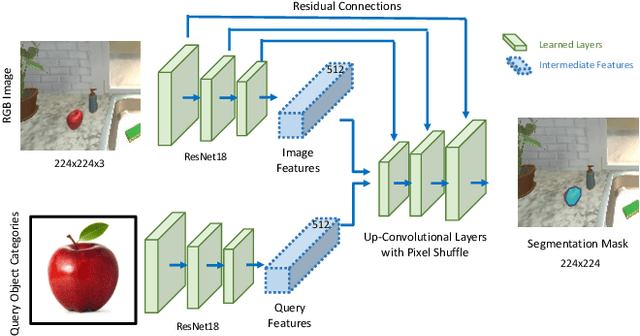
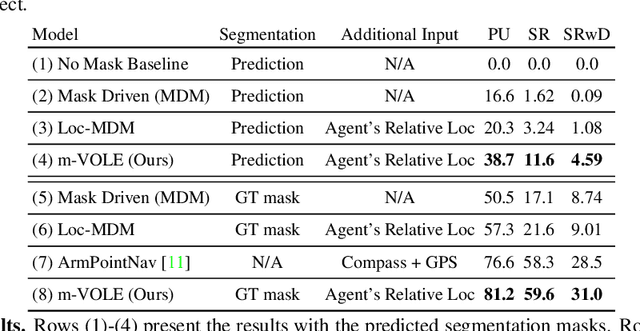
Object manipulation is a critical skill required for Embodied AI agents interacting with the world around them. Training agents to manipulate objects, poses many challenges. These include occlusion of the target object by the agent's arm, noisy object detection and localization, and the target frequently going out of view as the agent moves around in the scene. We propose Manipulation via Visual Object Location Estimation (m-VOLE), an approach that explores the environment in search for target objects, computes their 3D coordinates once they are located, and then continues to estimate their 3D locations even when the objects are not visible, thus robustly aiding the task of manipulating these objects throughout the episode. Our evaluations show a massive 3x improvement in success rate over a model that has access to the same sensory suite but is trained without the object location estimator, and our analysis shows that our agent is robust to noise in depth perception and agent localization. Importantly, our proposed approach relaxes several assumptions about idealized localization and perception that are commonly employed by recent works in embodied AI -- an important step towards training agents for object manipulation in the real world.
ASC me to Do Anything: Multi-task Training for Embodied AI
Feb 14, 2022



Embodied AI has seen steady progress across a diverse set of independent tasks. While these varied tasks have different end goals, the basic skills required to complete them successfully overlap significantly. In this paper, our goal is to leverage these shared skills to learn to perform multiple tasks jointly. We propose Atomic Skill Completion (ASC), an approach for multi-task training for Embodied AI, where a set of atomic skills shared across multiple tasks are composed together to perform the tasks. The key to the success of this approach is a pre-training scheme that decouples learning of the skills from the high-level tasks making joint training effective. We use ASC to train agents within the AI2-THOR environment to perform four interactive tasks jointly and find it to be remarkably effective. In a multi-task setting, ASC improves success rates by a factor of 2x on Seen scenes and 4x on Unseen scenes compared to no pre-training. Importantly, ASC enables us to train a multi-task agent that has a 52% higher Success Rate than training 4 independent single task agents. Finally, our hierarchical agents are more interpretable than traditional black-box architectures.
Webly Supervised Concept Expansion for General Purpose Vision Models
Feb 04, 2022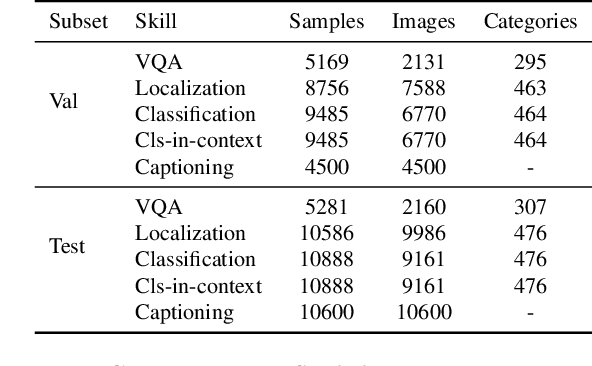
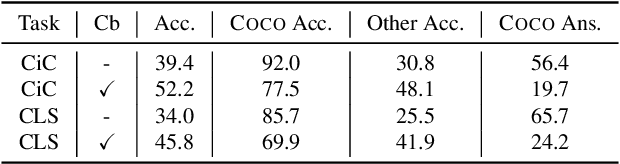
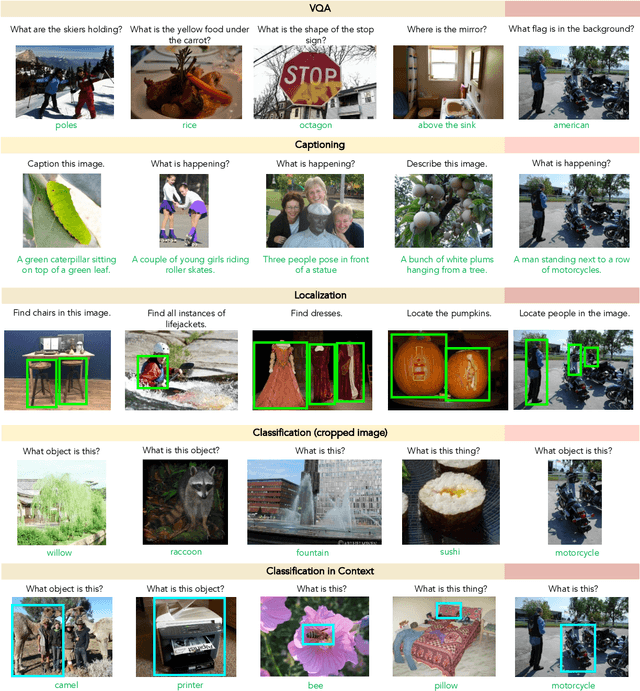
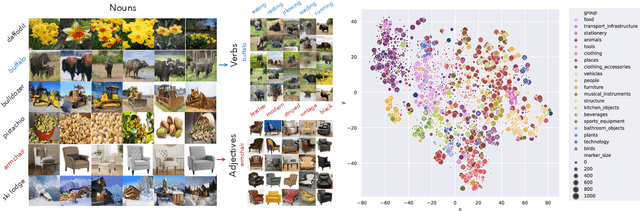
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts from large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.
Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text
Dec 01, 2021Communicating with humans is challenging for AIs because it requires a shared understanding of the world, complex semantics (e.g., metaphors or analogies), and at times multi-modal gestures (e.g., pointing with a finger, or an arrow in a diagram). We investigate these challenges in the context of Iconary, a collaborative game of drawing and guessing based on Pictionary, that poses a novel challenge for the research community. In Iconary, a Guesser tries to identify a phrase that a Drawer is drawing by composing icons, and the Drawer iteratively revises the drawing to help the Guesser in response. This back-and-forth often uses canonical scenes, visual metaphor, or icon compositions to express challenging words, making it an ideal test for mixing language and visual/symbolic communication in AI. We propose models to play Iconary and train them on over 55,000 games between human players. Our models are skillful players and are able to employ world knowledge in language models to play with words unseen during training. Elite human players outperform our models, particularly at the drawing task, leaving an important gap for future research to address. We release our dataset, code, and evaluation setup as a challenge to the community at http://www.github.com/allenai/iconary.
Simple but Effective: CLIP Embeddings for Embodied AI
Nov 18, 2021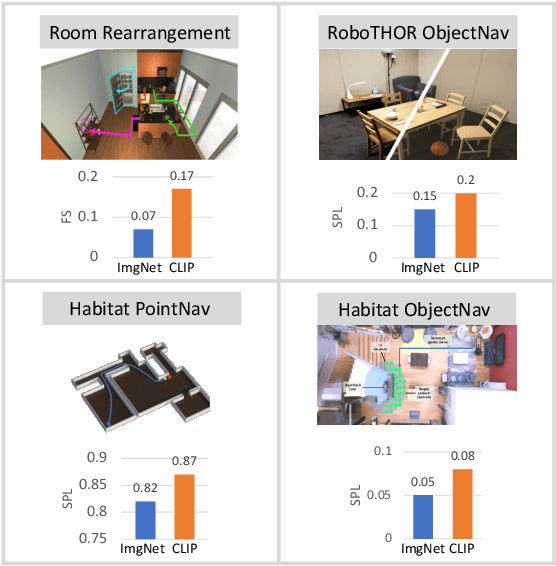
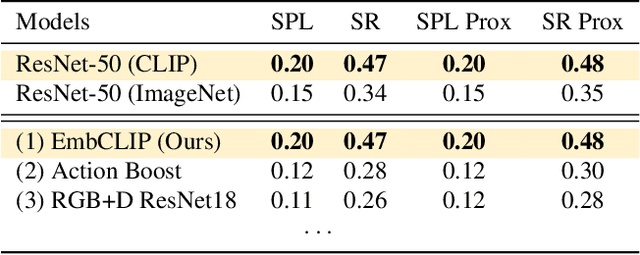
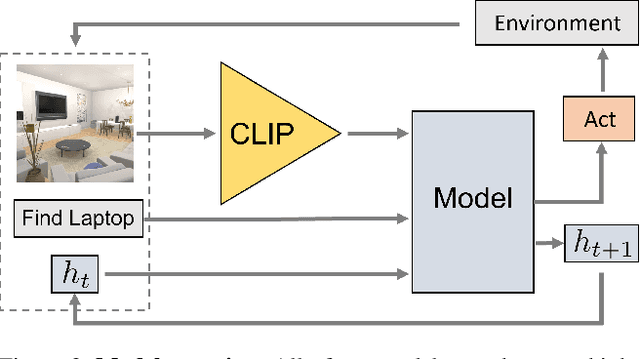
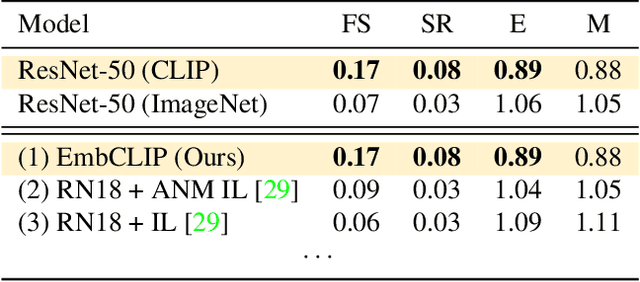
Contrastive language image pretraining (CLIP) encoders have been shown to be beneficial for a range of visual tasks from classification and detection to captioning and image manipulation. We investigate the effectiveness of CLIP visual backbones for embodied AI tasks. We build incredibly simple baselines, named EmbCLIP, with no task specific architectures, inductive biases (such as the use of semantic maps), auxiliary tasks during training, or depth maps -- yet we find that our improved baselines perform very well across a range of tasks and simulators. EmbCLIP tops the RoboTHOR ObjectNav leaderboard by a huge margin of 20 pts (Success Rate). It tops the iTHOR 1-Phase Rearrangement leaderboard, beating the next best submission, which employs Active Neural Mapping, and more than doubling the % Fixed Strict metric (0.08 to 0.17). It also beats the winners of the 2021 Habitat ObjectNav Challenge, which employ auxiliary tasks, depth maps, and human demonstrations, and those of the 2019 Habitat PointNav Challenge. We evaluate the ability of CLIP's visual representations at capturing semantic information about input observations -- primitives that are useful for navigation-heavy embodied tasks -- and find that CLIP's representations encode these primitives more effectively than ImageNet-pretrained backbones. Finally, we extend one of our baselines, producing an agent capable of zero-shot object navigation that can navigate to objects that were not used as targets during training.
RobustNav: Towards Benchmarking Robustness in Embodied Navigation
Jun 08, 2021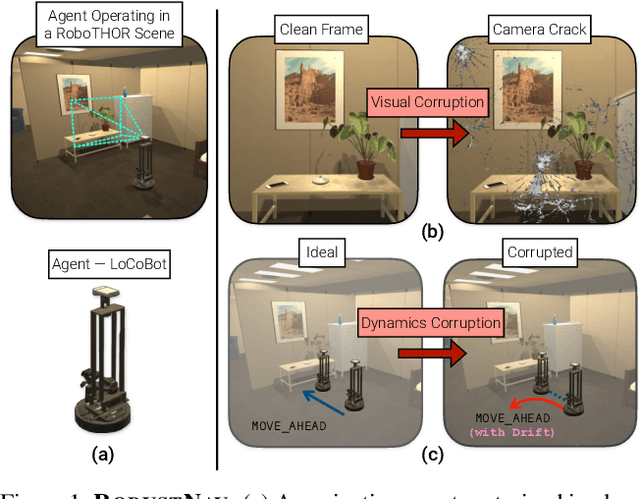
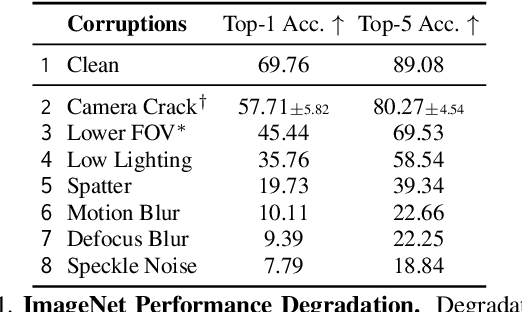

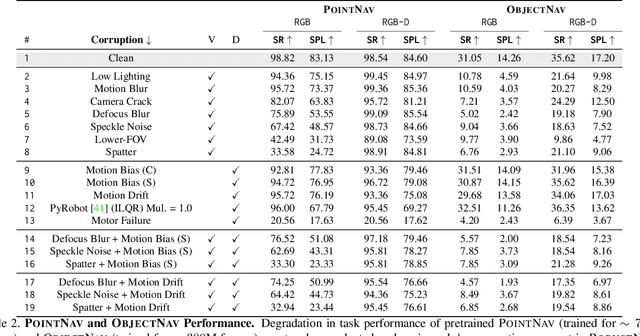
As an attempt towards assessing the robustness of embodied navigation agents, we propose RobustNav, a framework to quantify the performance of embodied navigation agents when exposed to a wide variety of visual - affecting RGB inputs - and dynamics - affecting transition dynamics - corruptions. Most recent efforts in visual navigation have typically focused on generalizing to novel target environments with similar appearance and dynamics characteristics. With RobustNav, we find that some standard embodied navigation agents significantly underperform (or fail) in the presence of visual or dynamics corruptions. We systematically analyze the kind of idiosyncrasies that emerge in the behavior of such agents when operating under corruptions. Finally, for visual corruptions in RobustNav, we show that while standard techniques to improve robustness such as data-augmentation and self-supervised adaptation offer some zero-shot resistance and improvements in navigation performance, there is still a long way to go in terms of recovering lost performance relative to clean "non-corrupt" settings, warranting more research in this direction. Our code is available at https://github.com/allenai/robustnav
Container: Context Aggregation Network
Jun 02, 2021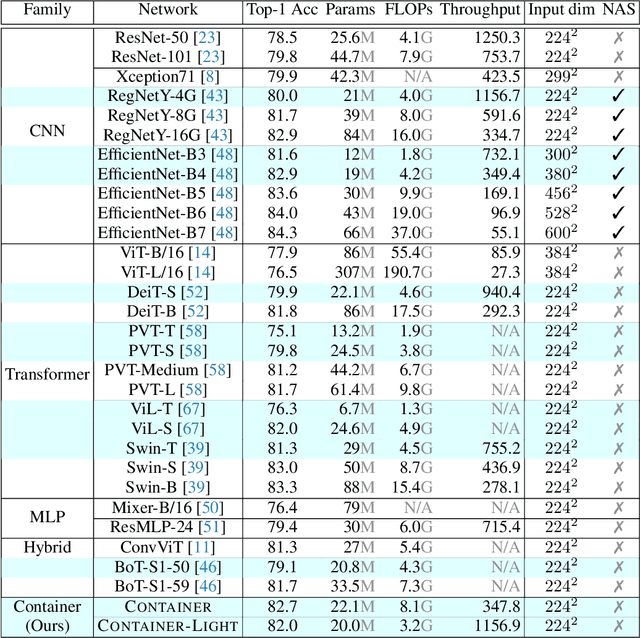
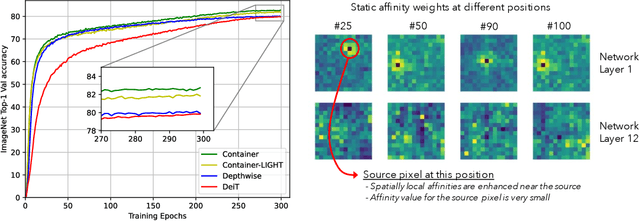
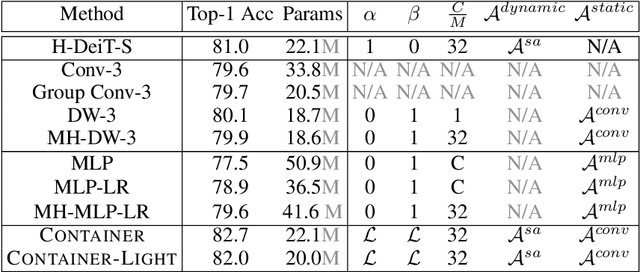
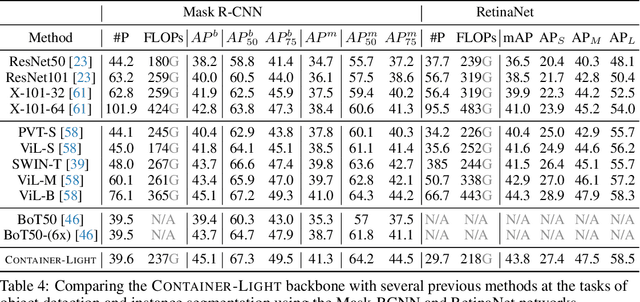
Convolutional neural networks (CNNs) are ubiquitous in computer vision, with a myriad of effective and efficient variations. Recently, Transformers -- originally introduced in natural language processing -- have been increasingly adopted in computer vision. While early adopters continue to employ CNN backbones, the latest networks are end-to-end CNN-free Transformer solutions. A recent surprising finding shows that a simple MLP based solution without any traditional convolutional or Transformer components can produce effective visual representations. While CNNs, Transformers and MLP-Mixers may be considered as completely disparate architectures, we provide a unified view showing that they are in fact special cases of a more general method to aggregate spatial context in a neural network stack. We present the \model (CONText AggregatIon NEtwoRk), a general-purpose building block for multi-head context aggregation that can exploit long-range interactions \emph{a la} Transformers while still exploiting the inductive bias of the local convolution operation leading to faster convergence speeds, often seen in CNNs. In contrast to Transformer-based methods that do not scale well to downstream tasks that rely on larger input image resolutions, our efficient network, named \modellight, can be employed in object detection and instance segmentation networks such as DETR, RetinaNet and Mask-RCNN to obtain an impressive detection mAP of 38.9, 43.8, 45.1 and mask mAP of 41.3, providing large improvements of 6.6, 7.3, 6.9 and 6.6 pts respectively, compared to a ResNet-50 backbone with a comparable compute and parameter size. Our method also achieves promising results on self-supervised learning compared to DeiT on the DINO framework.
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
Jun 01, 2021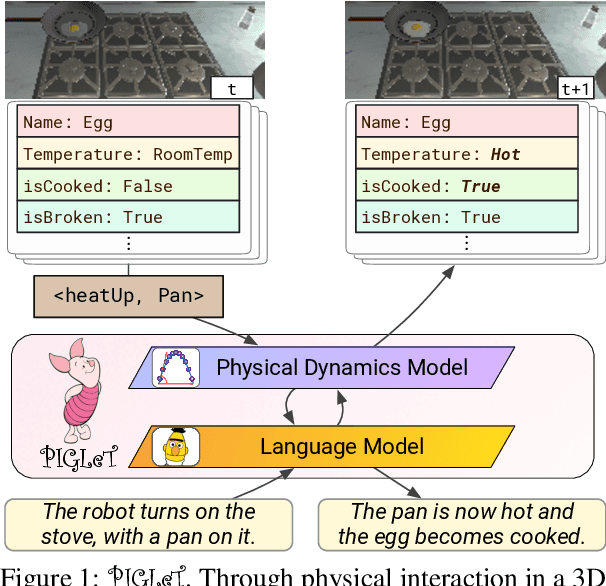
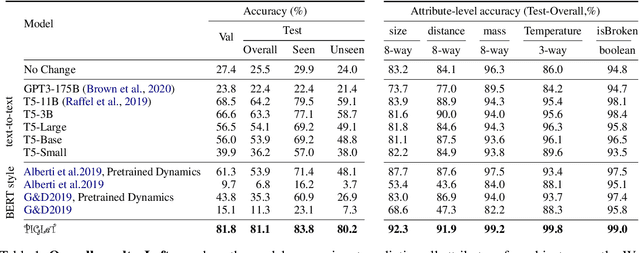

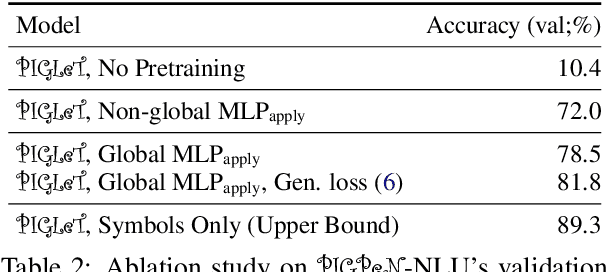
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don't. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast "what happens next" given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
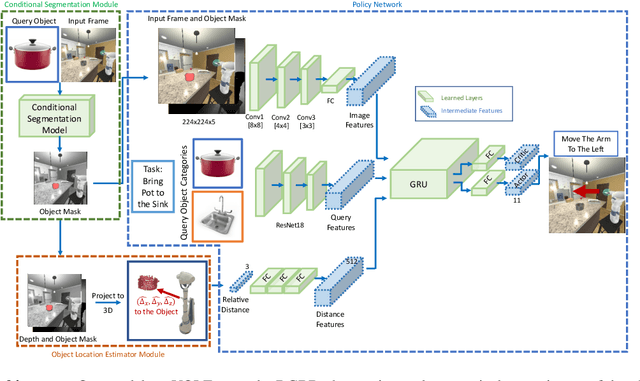
ManipulaTHOR: A Framework for Visual Object Manipulation
Apr 22, 2021
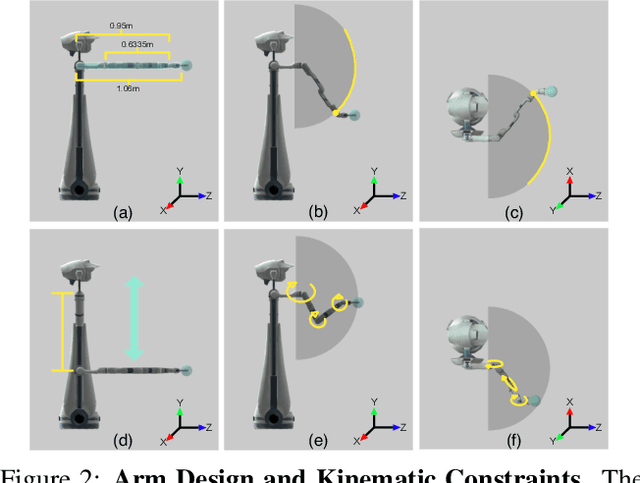
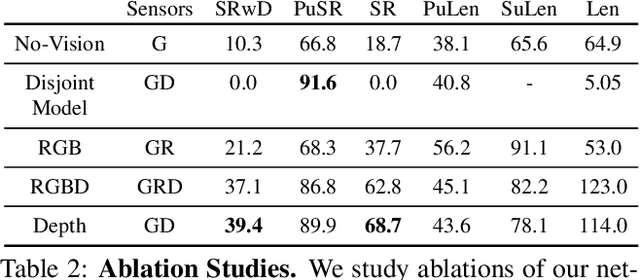

The domain of Embodied AI has recently witnessed substantial progress, particularly in navigating agents within their environments. These early successes have laid the building blocks for the community to tackle tasks that require agents to actively interact with objects in their environment. Object manipulation is an established research domain within the robotics community and poses several challenges including manipulator motion, grasping and long-horizon planning, particularly when dealing with oft-overlooked practical setups involving visually rich and complex scenes, manipulation using mobile agents (as opposed to tabletop manipulation), and generalization to unseen environments and objects. We propose a framework for object manipulation built upon the physics-enabled, visually rich AI2-THOR framework and present a new challenge to the Embodied AI community known as ArmPointNav. This task extends the popular point navigation task to object manipulation and offers new challenges including 3D obstacle avoidance, manipulating objects in the presence of occlusion, and multi-object manipulation that necessitates long term planning. Popular learning paradigms that are successful on PointNav challenges show promise, but leave a large room for improvement.
GridToPix: Training Embodied Agents with Minimal Supervision
Apr 14, 2021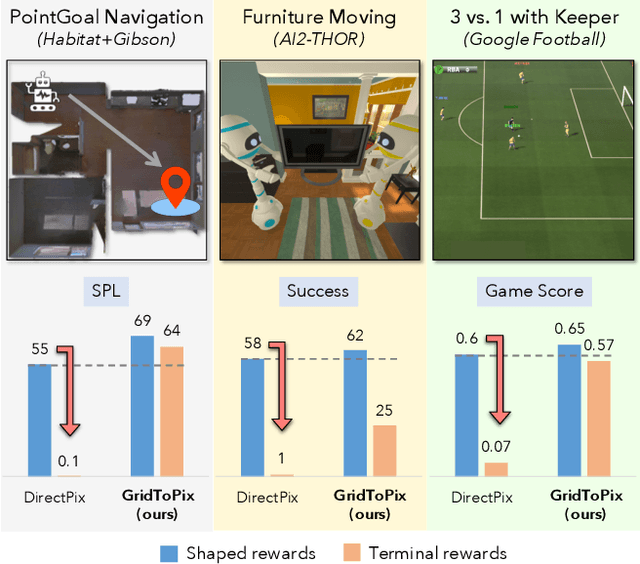

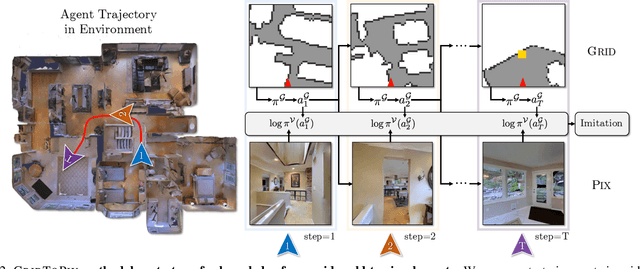

While deep reinforcement learning (RL) promises freedom from hand-labeled data, great successes, especially for Embodied AI, require significant work to create supervision via carefully shaped rewards. Indeed, without shaped rewards, i.e., with only terminal rewards, present-day Embodied AI results degrade significantly across Embodied AI problems from single-agent Habitat-based PointGoal Navigation (SPL drops from 55 to 0) and two-agent AI2-THOR-based Furniture Moving (success drops from 58% to 1%) to three-agent Google Football-based 3 vs. 1 with Keeper (game score drops from 0.6 to 0.1). As training from shaped rewards doesn't scale to more realistic tasks, the community needs to improve the success of training with terminal rewards. For this we propose GridToPix: 1) train agents with terminal rewards in gridworlds that generically mirror Embodied AI environments, i.e., they are independent of the task; 2) distill the learned policy into agents that reside in complex visual worlds. Despite learning from only terminal rewards with identical models and RL algorithms, GridToPix significantly improves results across tasks: from PointGoal Navigation (SPL improves from 0 to 64) and Furniture Moving (success improves from 1% to 25%) to football gameplay (game score improves from 0.1 to 0.6). GridToPix even helps to improve the results of shaped reward training.