 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Emerging AI/ML Accelerators: IPU, RDU, and NVIDIA/AMD GPUs
Nov 08, 2023The relentless advancement of artificial intelligence (AI) and machine learning (ML) applications necessitates the development of specialized hardware accelerators capable of handling the increasing complexity and computational demands. Traditional computing architectures, based on the von Neumann model, are being outstripped by the requirements of contemporary AI/ML algorithms, leading to a surge in the creation of accelerators like the Graphcore Intelligence Processing Unit (IPU), Sambanova Reconfigurable Dataflow Unit (RDU), and enhanced GPU platforms. These hardware accelerators are characterized by their innovative data-flow architectures and other design optimizations that promise to deliver superior performance and energy efficiency for AI/ML tasks. This research provides a preliminary evaluation and comparison of these commercial AI/ML accelerators, delving into their hardware and software design features to discern their strengths and unique capabilities. By conducting a series of benchmark evaluations on common DNN operators and other AI/ML workloads, we aim to illuminate the advantages of data-flow architectures over conventional processor designs and offer insights into the performance trade-offs of each platform. The findings from our study will serve as a valuable reference for the design and performance expectations of research prototypes, thereby facilitating the development of next-generation hardware accelerators tailored for the ever-evolving landscape of AI/ML applications. Through this analysis, we aspire to contribute to the broader understanding of current accelerator technologies and to provide guidance for future innovations in the field.
Research Team Identification Based on Representation Learning of Academic Heterogeneous Information Network
Nov 02, 2023



Academic networks in the real world can usually be described by heterogeneous information networks composed of multi-type nodes and relationships. Some existing research on representation learning for homogeneous information networks lacks the ability to explore heterogeneous information networks in heterogeneous information networks. It cannot be applied to heterogeneous information networks. Aiming at the practical needs of effectively identifying and discovering scientific research teams from the academic heterogeneous information network composed of massive and complex scientific and technological big data, this paper proposes a scientific research team identification method based on representation learning of academic heterogeneous information networks. The attention mechanism at node level and meta-path level learns low-dimensional, dense and real-valued vector representations on the basis of retaining the rich topological information of nodes in the network and the semantic information based on meta-paths, and realizes effective identification and discovery of scientific research teams and important team members in academic heterogeneous information networks based on maximizing node influence. Experimental results show that our proposed method outperforms the comparative methods.
Federated Topic Model and Model Pruning Based on Variational Autoencoder
Nov 01, 2023Topic modeling has emerged as a valuable tool for discovering patterns and topics within large collections of documents. However, when cross-analysis involves multiple parties, data privacy becomes a critical concern. Federated topic modeling has been developed to address this issue, allowing multiple parties to jointly train models while protecting pri-vacy. However, there are communication and performance challenges in the federated sce-nario. In order to solve the above problems, this paper proposes a method to establish a federated topic model while ensuring the privacy of each node, and use neural network model pruning to accelerate the model, where the client periodically sends the model neu-ron cumulative gradients and model weights to the server, and the server prunes the model. To address different requirements, two different methods are proposed to determine the model pruning rate. The first method involves slow pruning throughout the entire model training process, which has limited acceleration effect on the model training process, but can ensure that the pruned model achieves higher accuracy. This can significantly reduce the model inference time during the inference process. The second strategy is to quickly reach the target pruning rate in the early stage of model training in order to accelerate the model training speed, and then continue to train the model with a smaller model size after reaching the target pruning rate. This approach may lose more useful information but can complete the model training faster. Experimental results show that the federated topic model pruning based on the variational autoencoder proposed in this paper can greatly accelerate the model training speed while ensuring the model's performance.
* 8 pages
SiDA: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models
Oct 29, 2023



Mixture-of-Experts (MoE) has emerged as a favorable architecture in the era of large models due to its inherent advantage, i.e., enlarging model capacity without incurring notable computational overhead. Yet, the realization of such benefits often results in ineffective GPU memory utilization, as large portions of the model parameters remain dormant during inference. Moreover, the memory demands of large models consistently outpace the memory capacity of contemporary GPUs. Addressing this, we introduce SiDA (Sparsity-inspired Data-Aware), an efficient inference approach tailored for large MoE models. SiDA judiciously exploits both the system's main memory, which is now abundant and readily scalable, and GPU memory by capitalizing on the inherent sparsity on expert activation in MoE models. By adopting a data-aware perspective, SiDA achieves enhanced model efficiency with a neglectable performance drop. Specifically, SiDA attains a remarkable speedup in MoE inference with up to 3.93X throughput increasing, up to 75% latency reduction, and up to 80% GPU memory saving with down to 1% performance drop. This work paves the way for scalable and efficient deployment of large MoE models, even in memory-constrained systems.
Adversarial Examples Are Not Real Features
Oct 29, 2023



The existence of adversarial examples has been a mystery for years and attracted much interest. A well-known theory by \citet{ilyas2019adversarial} explains adversarial vulnerability from a data perspective by showing that one can extract non-robust features from adversarial examples and these features alone are useful for classification. However, the explanation remains quite counter-intuitive since non-robust features are mostly noise features to humans. In this paper, we re-examine the theory from a larger context by incorporating multiple learning paradigms. Notably, we find that contrary to their good usefulness under supervised learning, non-robust features attain poor usefulness when transferred to other self-supervised learning paradigms, such as contrastive learning, masked image modeling, and diffusion models. It reveals that non-robust features are not really as useful as robust or natural features that enjoy good transferability between these paradigms. Meanwhile, for robustness, we also show that naturally trained encoders from robust features are largely non-robust under AutoAttack. Our cross-paradigm examination suggests that the non-robust features are not really useful but more like paradigm-wise shortcuts, and robust features alone might be insufficient to attain reliable model robustness. Code is available at \url{https://github.com/PKU-ML/AdvNotRealFeatures}.
Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Oct 08, 2023



Despite significant results achieved by Contrastive Language-Image Pretraining (CLIP) in zero-shot image recognition, limited effort has been made exploring its potential for zero-shot video recognition. This paper presents Open-VCLIP++, a simple yet effective framework that adapts CLIP to a strong zero-shot video classifier, capable of identifying novel actions and events during testing. Open-VCLIP++ minimally modifies CLIP to capture spatial-temporal relationships in videos, thereby creating a specialized video classifier while striving for generalization. We formally demonstrate that training Open-VCLIP++ is tantamount to continual learning with zero historical data. To address this problem, we introduce Interpolated Weight Optimization, a technique that leverages the advantages of weight interpolation during both training and testing. Furthermore, we build upon large language models to produce fine-grained video descriptions. These detailed descriptions are further aligned with video features, facilitating a better transfer of CLIP to the video domain. Our approach is evaluated on three widely used action recognition datasets, following a variety of zero-shot evaluation protocols. The results demonstrate that our method surpasses existing state-of-the-art techniques by significant margins. Specifically, we achieve zero-shot accuracy scores of 88.1%, 58.7%, and 81.2% on UCF, HMDB, and Kinetics-600 datasets respectively, outpacing the best-performing alternative methods by 8.5%, 8.2%, and 12.3%. We also evaluate our approach on the MSR-VTT video-text retrieval dataset, where it delivers competitive video-to-text and text-to-video retrieval performance, while utilizing substantially less fine-tuning data compared to other methods. Code is released at https://github.com/wengzejia1/Open-VCLIP.
FedHyper: A Universal and Robust Learning Rate Scheduler for Federated Learning with Hypergradient Descent
Oct 06, 2023



The theoretical landscape of federated learning (FL) undergoes rapid evolution, but its practical application encounters a series of intricate challenges, and hyperparameter optimization is one of these critical challenges. Amongst the diverse adjustments in hyperparameters, the adaptation of the learning rate emerges as a crucial component, holding the promise of significantly enhancing the efficacy of FL systems. In response to this critical need, this paper presents FedHyper, a novel hypergradient-based learning rate adaptation algorithm specifically designed for FL. FedHyper serves as a universal learning rate scheduler that can adapt both global and local rates as the training progresses. In addition, FedHyper not only showcases unparalleled robustness to a spectrum of initial learning rate configurations but also significantly alleviates the necessity for laborious empirical learning rate adjustments. We provide a comprehensive theoretical analysis of FedHyper's convergence rate and conduct extensive experiments on vision and language benchmark datasets. The results demonstrate that FEDHYPER consistently converges 1.1-3x faster than FedAvg and the competing baselines while achieving superior final accuracy. Moreover, FedHyper catalyzes a remarkable surge in accuracy, augmenting it by up to 15% compared to FedAvg under suboptimal initial learning rate settings.
FedNAR: Federated Optimization with Normalized Annealing Regularization
Oct 04, 2023



Weight decay is a standard technique to improve generalization performance in modern deep neural network optimization, and is also widely adopted in federated learning (FL) to prevent overfitting in local clients. In this paper, we first explore the choices of weight decay and identify that weight decay value appreciably influences the convergence of existing FL algorithms. While preventing overfitting is crucial, weight decay can introduce a different optimization goal towards the global objective, which is further amplified in FL due to multiple local updates and heterogeneous data distribution. To address this challenge, we develop {\it Federated optimization with Normalized Annealing Regularization} (FedNAR), a simple yet effective and versatile algorithmic plug-in that can be seamlessly integrated into any existing FL algorithms. Essentially, we regulate the magnitude of each update by performing co-clipping of the gradient and weight decay. We provide a comprehensive theoretical analysis of FedNAR's convergence rate and conduct extensive experiments on both vision and language datasets with different backbone federated optimization algorithms. Our experimental results consistently demonstrate that incorporating FedNAR into existing FL algorithms leads to accelerated convergence and heightened model accuracy. Moreover, FedNAR exhibits resilience in the face of various hyperparameter configurations. Specifically, FedNAR has the ability to self-adjust the weight decay when the initial specification is not optimal, while the accuracy of traditional FL algorithms would markedly decline. Our codes are released at \href{https://github.com/ljb121002/fednar}{https://github.com/ljb121002/fednar}.
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023



Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.
Block-Level Interference Exploitation Precoding for MU-MISO: An ADMM Approach
Aug 30, 2023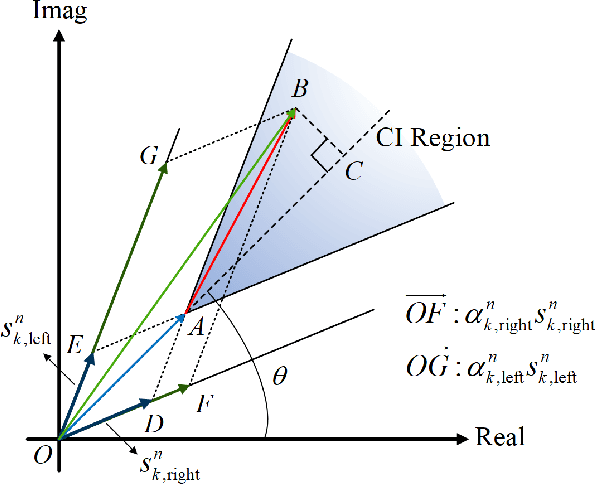
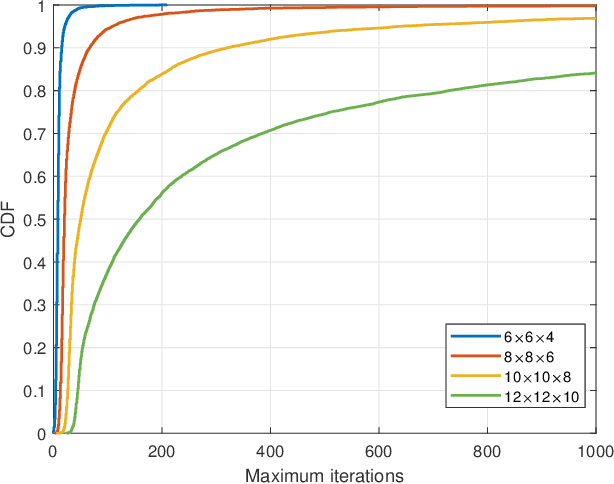
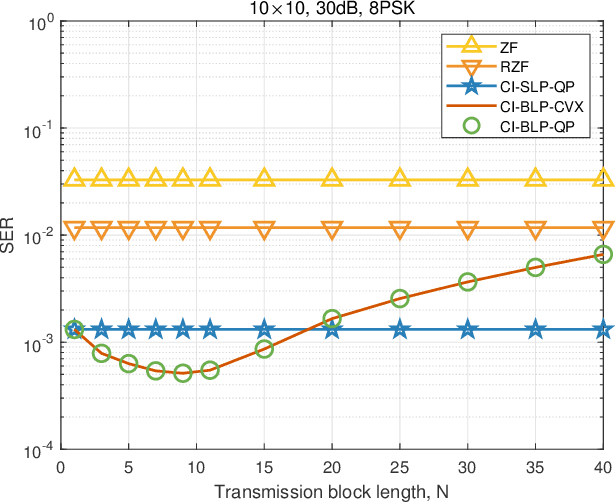
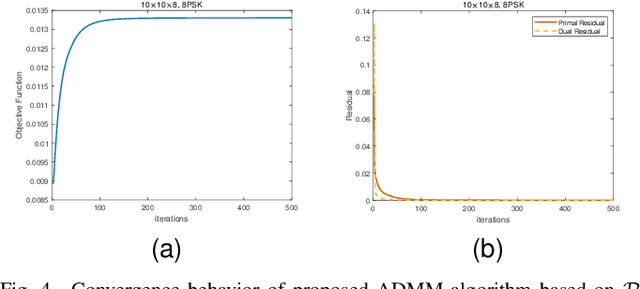
We study constructive interference based block-level precoding (CI-BLP) in the downlink of multi-user multiple-input single-output (MU-MISO) systems. Specifically, our aim is to extend the analysis on CI-BLP to the case where the considered number of symbol slots is smaller than that of the users. To this end, we mathematically prove the feasibility of using the pseudo-inverse to obtain the optimal CI-BLP precoding matrix in a closed form. Similar to the case when the number of users is small, we show that a quadratic programming (QP) optimization on simplex can be constructed. We also design a low-complexity algorithm based on the alternating direction method of multipliers (ADMM) framework, which can efficiently solve large-scale QP problems. We further analyze the convergence and complexity of the proposed algorithm. Numerical results validate our analysis and the optimality of the proposed algorithm, and further show that the proposed algorithm offers a flexible performance-complexity tradeoff by limiting the maximum number of iterations, which motivates the use of CI-BLP in practical wireless systems.