 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Technology to 1,000+ Languages
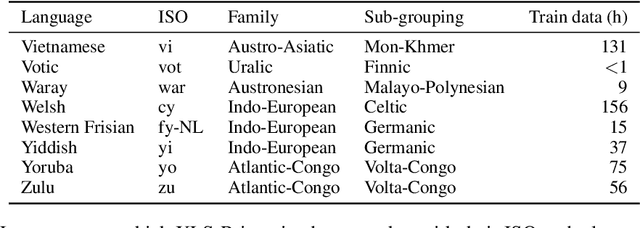
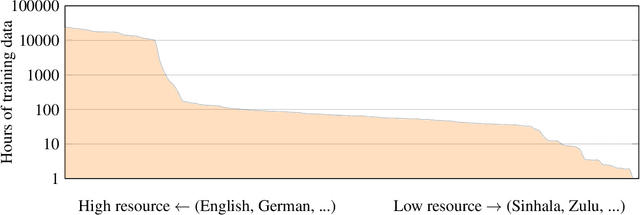
May 22, 2023Expanding the language coverage of speech technology has the potential to improve access to information for many more people. However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000 languages spoken around the world. The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task. The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for the same number of languages, as well as a language identification model for 4,017 languages. Experiments show that our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.
SpeeChain: A Speech Toolkit for Large-Scale Machine Speech Chain
Jan 08, 2023This paper introduces SpeeChain, an open-source Pytorch-based toolkit designed to develop the machine speech chain for large-scale use. This first release focuses on the TTS-to-ASR chain, a core component of the machine speech chain, that refers to the TTS data augmentation by unspoken text for ASR. To build an efficient pipeline for the large-scale TTS-to-ASR chain, we implement easy-to-use multi-GPU batch-level model inference, multi-dataloader batch generation, and on-the-fly data selection techniques. In this paper, we first explain the overall procedure of the TTS-to-ASR chain and the difficulties of each step. Then, we present a detailed ablation study on different types of unlabeled data, data filtering thresholds, batch composition, and real-synthetic data ratios. Our experimental results on train_clean_460 of LibriSpeech demonstrate that our TTS-to-ASR chain can significantly improve WER in a semi-supervised setting.
Voice-preserving Zero-shot Multiple Accent Conversion
Nov 23, 2022Most people who have tried to learn a foreign language would have experienced difficulties understanding or speaking with a native speaker's accent. For native speakers, understanding or speaking a new accent is likewise a difficult task. An accent conversion system that changes a speaker's accent but preserves that speaker's voice identity, such as timbre and pitch, has the potential for a range of applications, such as communication, language learning, and entertainment. Existing accent conversion models tend to change the speaker identity and accent at the same time. Here, we use adversarial learning to disentangle accent dependent features while retaining other acoustic characteristics. What sets our work apart from existing accent conversion models is the capability to convert an unseen speaker's utterance to multiple accents while preserving its original voice identity. Subjective evaluations show that our model generates audio that sound closer to the target accent and like the original speaker.
Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities
Nov 10, 2022



End-to-end multilingual ASR has become more appealing because of several reasons such as simplifying the training and deployment process and positive performance transfer from high-resource to low-resource languages. However, scaling up the number of languages, total hours, and number of unique tokens is not a trivial task. This paper explores large-scale multilingual ASR models on 70 languages. We inspect two architectures: (1) Shared embedding and output and (2) Multiple embedding and output model. In the shared model experiments, we show the importance of tokenization strategy across different languages. Later, we use our optimal tokenization strategy to train multiple embedding and output model to further improve our result. Our multilingual ASR achieves 13.9%-15.6% average WER relative improvement compared to monolingual models. We show that our multilingual ASR generalizes well on an unseen dataset and domain, achieving 9.5% and 7.5% WER on Multilingual Librispeech (MLS) with zero-shot and finetuning, respectively.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022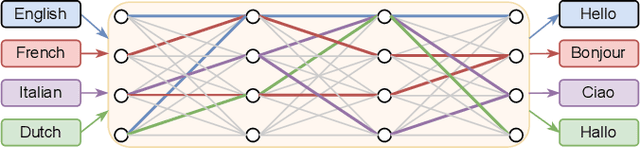
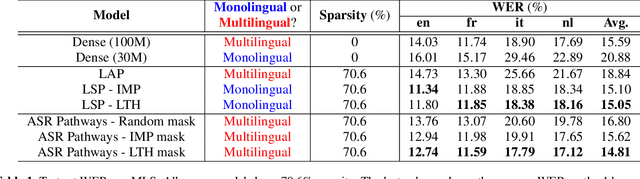
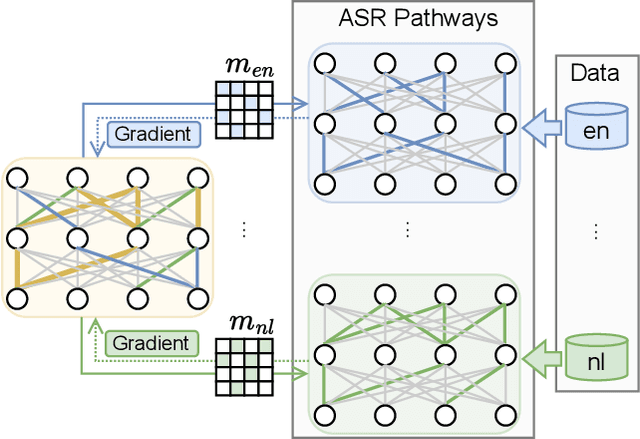
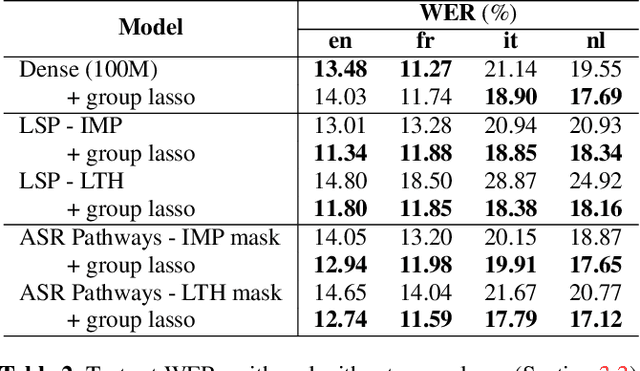
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Nov 19, 2021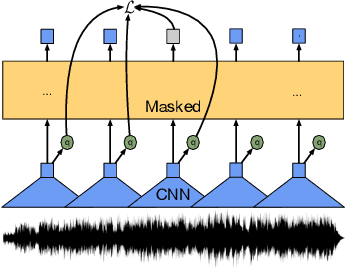

This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
Conformer-Based Self-Supervised Learning for Non-Speech Audio Tasks
Nov 10, 2021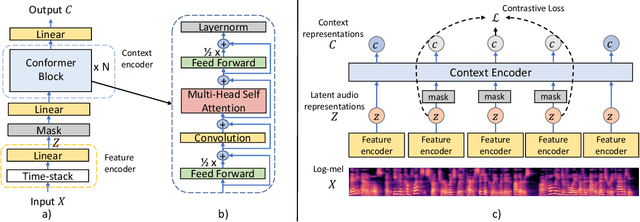
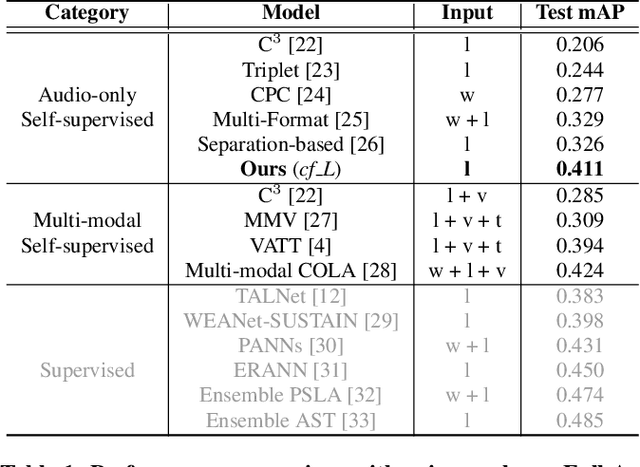

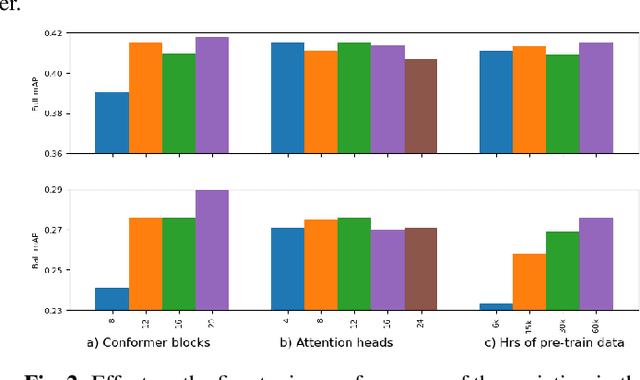
Representation learning from unlabeled data has been of major interest in artificial intelligence research. While self-supervised speech representation learning has been popular in the speech research community, very few works have comprehensively analyzed audio representation learning for non-speech audio tasks. In this paper, we propose a self-supervised audio representation learning method and apply it to a variety of downstream non-speech audio tasks. We combine the well-known wav2vec 2.0 framework, which has shown success in self-supervised learning for speech tasks, with parameter-efficient conformer architectures. Our self-supervised pre-training can reduce the need for labeled data by two-thirds. On the AudioSet benchmark, we achieve a mean average precision (mAP) score of 0.415, which is a new state-of-the-art on this dataset through audio-only self-supervised learning. Our fine-tuned conformers also surpass or match the performance of previous systems pre-trained in a supervised way on several downstream tasks. We further discuss the important design considerations for both pre-training and fine-tuning.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021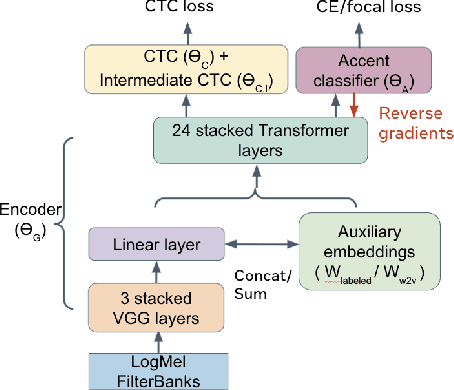
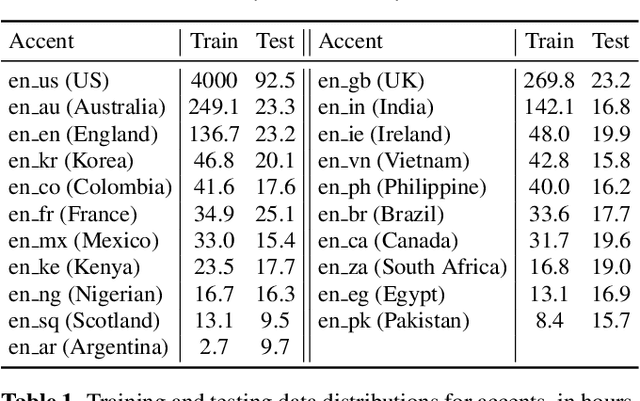

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021
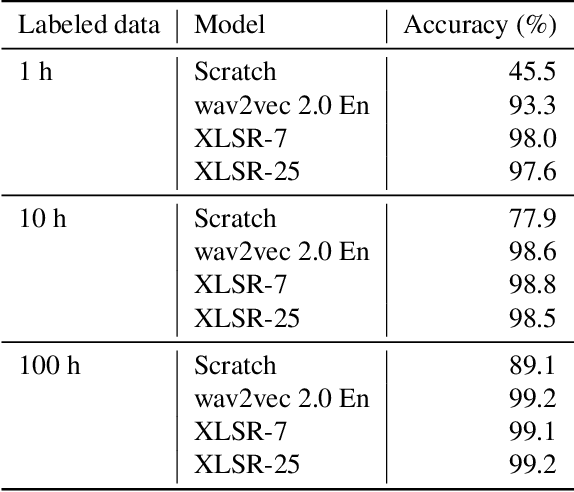
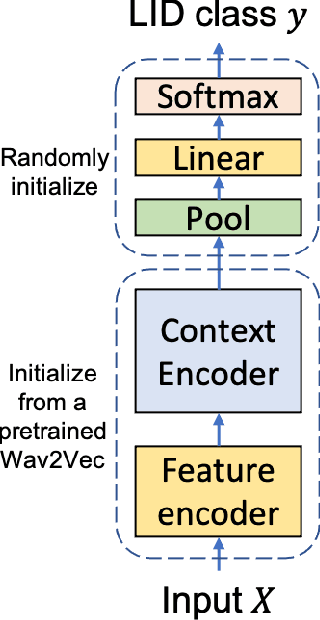
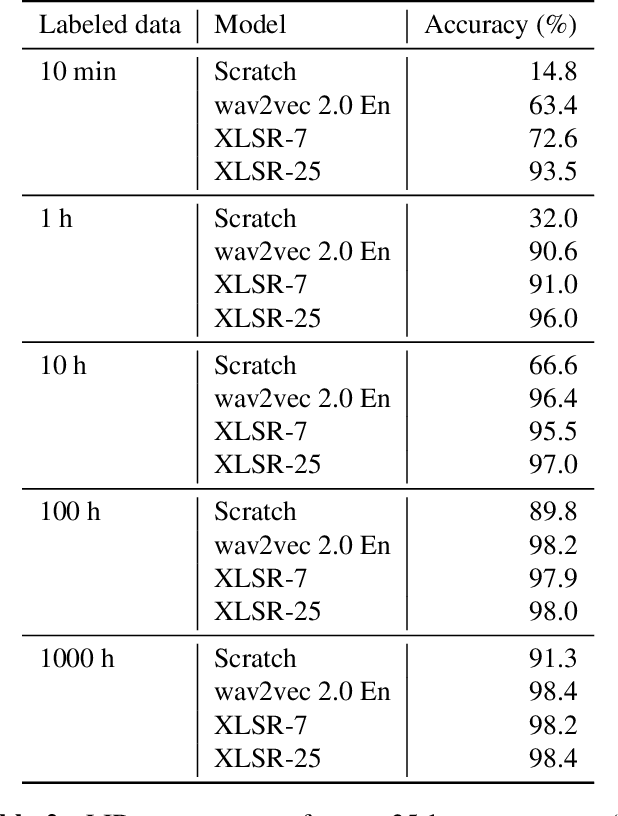
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis
Nov 04, 2020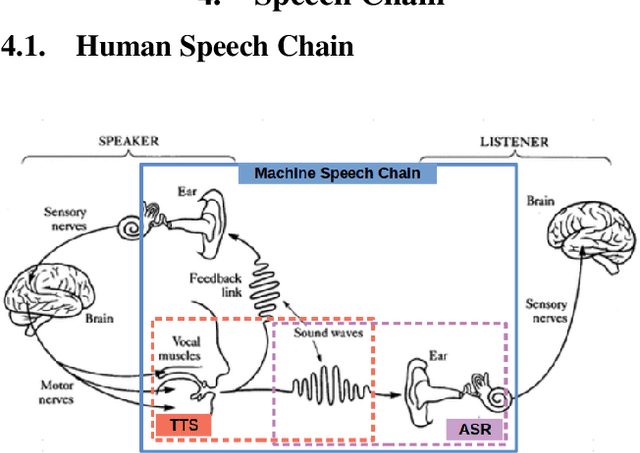


Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages.