 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
CountGD++: Generalized Prompting for Open-World Counting
Dec 29, 2025The flexibility and accuracy of methods for automatically counting objects in images and videos are limited by the way the object can be specified. While existing methods allow users to describe the target object with text and visual examples, the visual examples must be manually annotated inside the image, and there is no way to specify what not to count. To address these gaps, we introduce novel capabilities that expand how the target object can be specified. Specifically, we extend the prompt to enable what not to count to be described with text and/or visual examples, introduce the concept of `pseudo-exemplars' that automate the annotation of visual examples at inference, and extend counting models to accept visual examples from both natural and synthetic external images. We also use our new counting model, CountGD++, as a vision expert agent for an LLM. Together, these contributions expand the prompt flexibility of multi-modal open-world counting and lead to significant improvements in accuracy, efficiency, and generalization across multiple datasets. Code is available at https://github.com/niki-amini-naieni/CountGDPlusPlus.
Recurrent Video Masked Autoencoders
Dec 15, 2025We present Recurrent Video Masked-Autoencoders (RVM): a novel video representation learning approach that uses a transformer-based recurrent neural network to aggregate dense image features over time, effectively capturing the spatio-temporal structure of natural video data. RVM learns via an asymmetric masked prediction task requiring only a standard pixel reconstruction objective. This design yields a highly efficient ``generalist'' encoder: RVM achieves competitive performance with state-of-the-art video models (e.g. VideoMAE, V-JEPA) on video-level tasks like action recognition and point/object tracking, while also performing favorably against image models (e.g. DINOv2) on tasks that test geometric and dense spatial understanding. Notably, RVM achieves strong performance in the small-model regime without requiring knowledge distillation, exhibiting up to 30x greater parameter efficiency than competing video masked autoencoders. Moreover, we demonstrate that RVM's recurrent nature allows for stable feature propagation over long temporal horizons with linear computational cost, overcoming some of the limitations of standard spatio-temporal attention-based architectures. Finally, we use qualitative visualizations to highlight that RVM learns rich representations of scene semantics, structure, and motion.
TARA: Simple and Efficient Time Aware Retrieval Adaptation of MLLMs for Video Understanding
Dec 15, 2025Our objective is to build a general time-aware video-text embedding model for retrieval. To that end, we propose a simple and efficient recipe, dubbed TARA (Time Aware Retrieval Adaptation), to adapt Multimodal LLMs (MLLMs) to a time-aware video-text embedding model without using any video data at all. For evaluating time-awareness in retrieval, we propose a new benchmark with temporally opposite (chiral) actions as hard negatives and curated splits for chiral and non-chiral actions. We show that TARA outperforms all existing video-text models on this chiral benchmark while also achieving strong results on standard benchmarks. Furthermore, we discover additional benefits of TARA beyond time-awareness: (i) TARA embeddings are negation-aware as shown in NegBench benchmark that evaluates negation in video retrieval, (ii) TARA achieves state of the art performance on verb and adverb understanding in videos. Overall, TARA yields a strong, versatile, time-aware video-text embedding model with state of the art zero-shot performance.
Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025



Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Lost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025


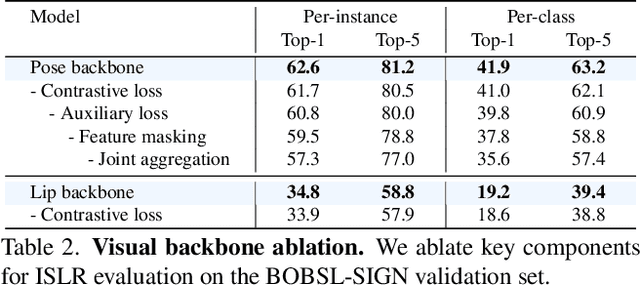
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.
Segment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Inferring Dynamic Physical Properties from Video Foundation Models
Oct 02, 2025We study the task of predicting dynamic physical properties from videos. More specifically, we consider physical properties that require temporal information to be inferred: elasticity of a bouncing object, viscosity of a flowing liquid, and dynamic friction of an object sliding on a surface. To this end, we make the following contributions: (i) We collect a new video dataset for each physical property, consisting of synthetic training and testing splits, as well as a real split for real world evaluation. (ii) We explore three ways to infer the physical property from videos: (a) an oracle method where we supply the visual cues that intrinsically reflect the property using classical computer vision techniques; (b) a simple read out mechanism using a visual prompt and trainable prompt vector for cross-attention on pre-trained video generative and self-supervised models; and (c) prompt strategies for Multi-modal Large Language Models (MLLMs). (iii) We show that video foundation models trained in a generative or self-supervised manner achieve a similar performance, though behind that of the oracle, and MLLMs are currently inferior to the other models, though their performance can be improved through suitable prompting.
Chirality in Action: Time-Aware Video Representation Learning by Latent Straightening
Sep 10, 2025Our objective is to develop compact video representations that are sensitive to visual change over time. To measure such time-sensitivity, we introduce a new task: chiral action recognition, where one needs to distinguish between a pair of temporally opposite actions, such as "opening vs. closing a door", "approaching vs. moving away from something", "folding vs. unfolding paper", etc. Such actions (i) occur frequently in everyday life, (ii) require understanding of simple visual change over time (in object state, size, spatial position, count . . . ), and (iii) are known to be poorly represented by many video embeddings. Our goal is to build time aware video representations which offer linear separability between these chiral pairs. To that end, we propose a self-supervised adaptation recipe to inject time-sensitivity into a sequence of frozen image features. Our model is based on an auto-encoder with a latent space with inductive bias inspired by perceptual straightening. We show that this results in a compact but time-sensitive video representation for the proposed task across three datasets: Something-Something, EPIC-Kitchens, and Charade. Our method (i) outperforms much larger video models pre-trained on large-scale video datasets, and (ii) leads to an improvement in classification performance on standard benchmarks when combined with these existing models.
Open-World Object Counting in Videos
Jun 18, 2025
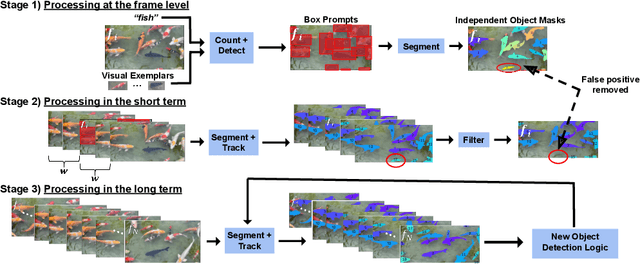
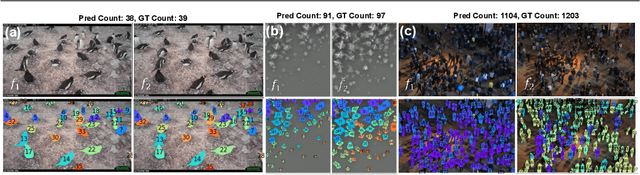
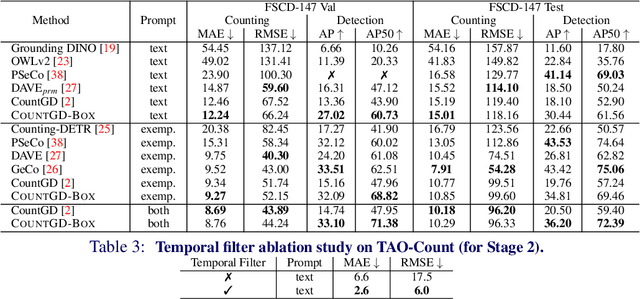
We introduce a new task of open-world object counting in videos: given a text description, or an image example, that specifies the target object, the objective is to enumerate all the unique instances of the target objects in the video. This task is especially challenging in crowded scenes with occlusions and similar objects, where avoiding double counting and identifying reappearances is crucial. To this end, we make the following contributions: we introduce a model, CountVid, for this task. It leverages an image-based counting model, and a promptable video segmentation and tracking model to enable automated, open-world object counting across video frames. To evaluate its performance, we introduce VideoCount, a new dataset for our novel task built from the TAO and MOT20 tracking datasets, as well as from videos of penguins and metal alloy crystallization captured by x-rays. Using this dataset, we demonstrate that CountVid provides accurate object counts, and significantly outperforms strong baselines. The VideoCount dataset, the CountVid model, and all the code are available at https://github.com/niki-amini-naieni/CountVid/.