 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Object Counting in Videos
Paper and Code

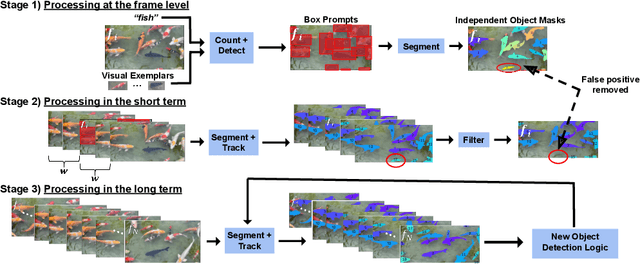
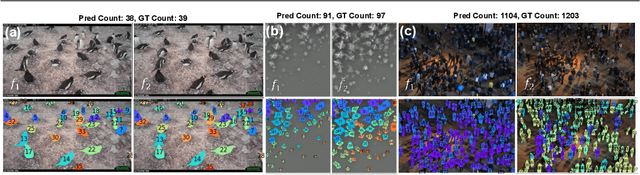
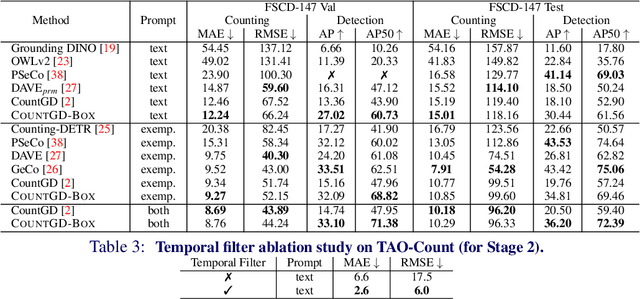
We introduce a new task of open-world object counting in videos: given a text description, or an image example, that specifies the target object, the objective is to enumerate all the unique instances of the target objects in the video. This task is especially challenging in crowded scenes with occlusions and similar objects, where avoiding double counting and identifying reappearances is crucial. To this end, we make the following contributions: we introduce a model, CountVid, for this task. It leverages an image-based counting model, and a promptable video segmentation and tracking model to enable automated, open-world object counting across video frames. To evaluate its performance, we introduce VideoCount, a new dataset for our novel task built from the TAO and MOT20 tracking datasets, as well as from videos of penguins and metal alloy crystallization captured by x-rays. Using this dataset, we demonstrate that CountVid provides accurate object counts, and significantly outperforms strong baselines. The VideoCount dataset, the CountVid model, and all the code are available at https://github.com/niki-amini-naieni/CountVid/.