 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemilliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020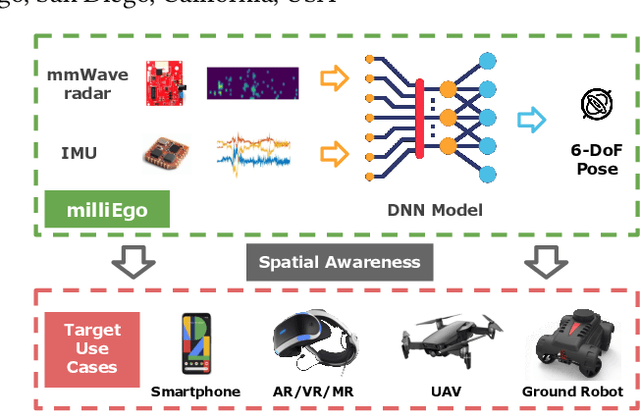
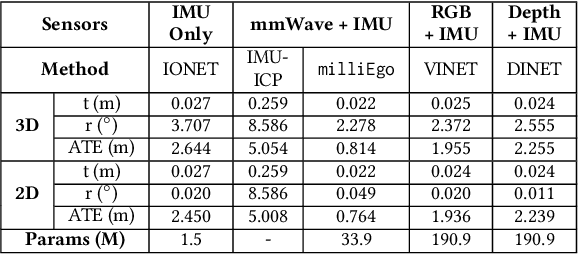
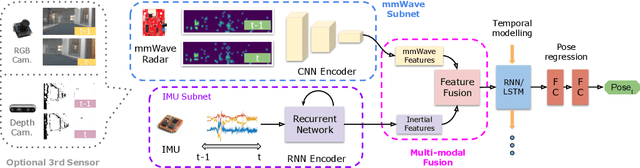
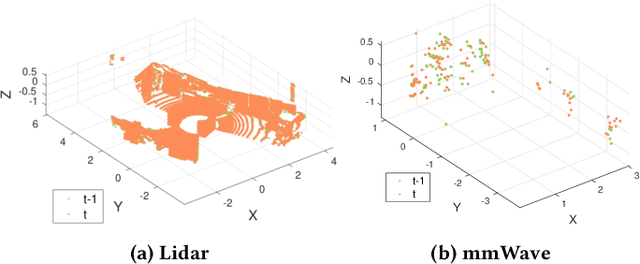
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
MVLoc: Multimodal Variational Geometry-Aware Learning for Visual Localization
Mar 12, 2020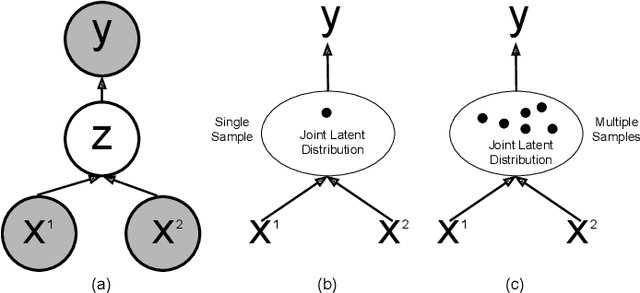
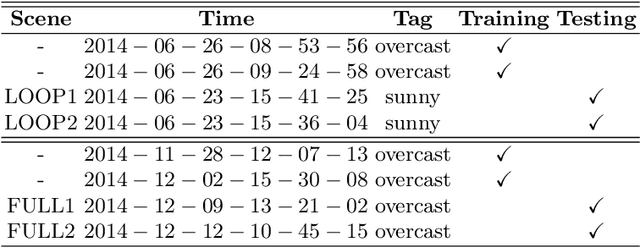
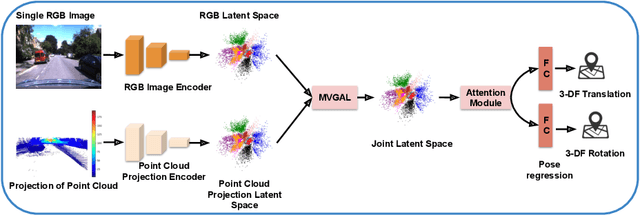
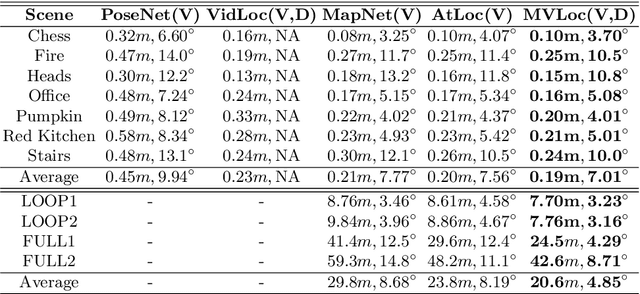
Recent learning-based research has achieved impressive results in the field of single-shot camera relocalization. However, how best to fuse multiple modalities, for example, image and depth, and how to deal with degraded or missing input are less well studied. In particular, we note that previous approaches towards deep fusion do not perform significantly better than models employing a single modality. We conjecture that this is because of the naive approaches to feature space fusion through summation or concatenation which do not take into account the different strengths of each modality, specifically appearance for images and structure for depth. To address this, we propose an end-to-end framework to fuse different sensor inputs through a variational Product-of-Experts (PoE) joint encoder followed by attention-based fusion. Unlike prior work which draws a single sample from the joint encoder, we show how accuracy can be increased through importance sampling and reparameterization of the latent space. Our model is extensively evaluated on RGB-D datasets, outperforming existing baselines by a large margin.
PointLoc: Deep Pose Regressor for LiDAR Point Cloud Localization
Mar 05, 2020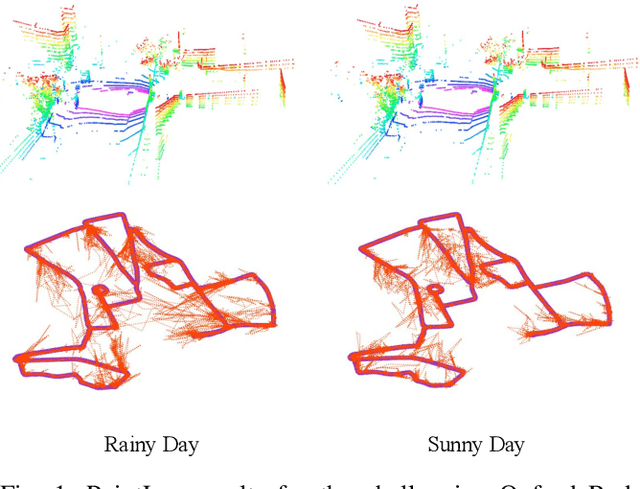
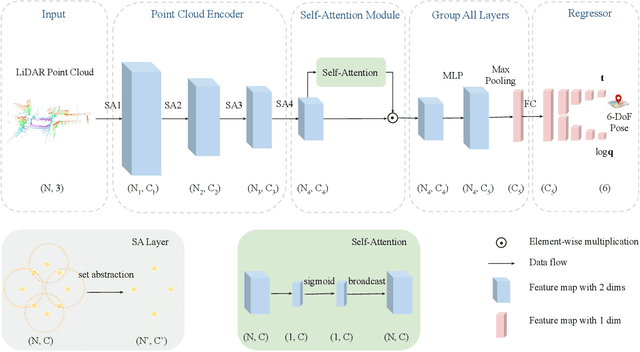
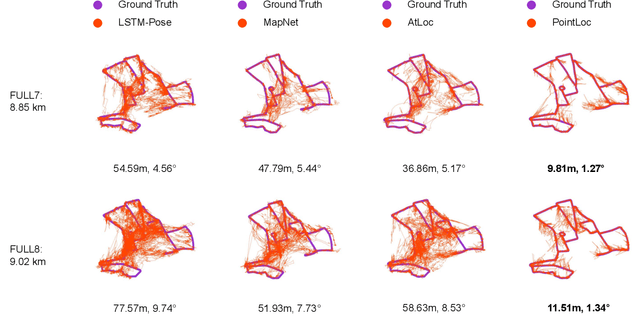
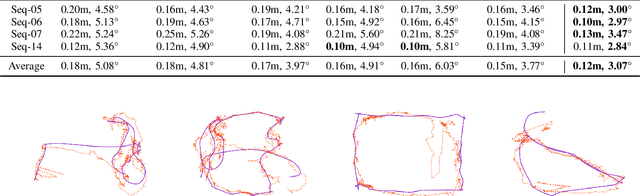
In this paper, we present a novel end-to-end learning-based LiDAR relocalization framework, termed PointLoc, which infers 6-DoF poses directly using only a single point cloud as input, without requiring a pre-built map. Compared to RGB image-based relocalization, LiDAR frames can provide rich and robust geometric information about a scene. However, LiDAR point clouds are sparse and unstructured making it difficult to apply traditional deep learning regression models for this task. We address this issue by proposing a novel PointNet-style architecture with self-attention to efficiently estimate 6-DoF poses from 360{\deg} LiDAR input frames. Extensive experiments on recently released challenging Oxford Radar RobotCar dataset and real-world robot experiments demonstrate that the proposed method can achieve accurate relocalization performance. We show that our approach improves the state-of-the-art MapNet by 69.59% in translation and 75.70% in rotation, and AtLoc by 66.86% in translation and 78.83% in rotation on the challenging outdoor large-scale Oxford Radar RobotCar dataset.
Deep Learning based Pedestrian Inertial Navigation: Methods, Dataset and On-Device Inference
Jan 13, 2020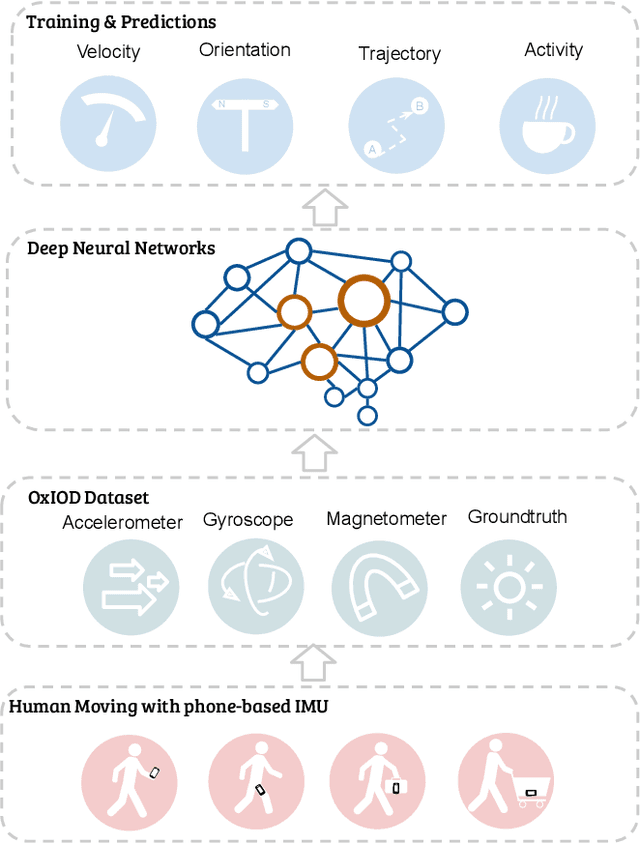
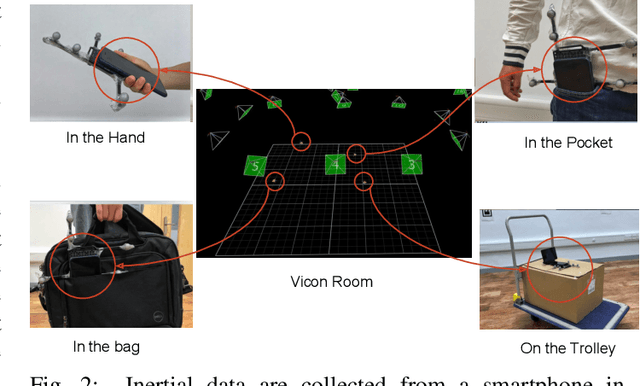
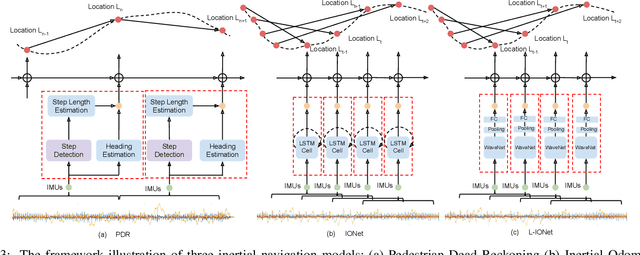
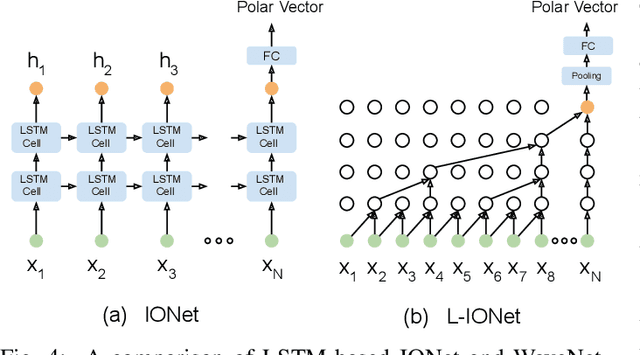
Modern inertial measurements units (IMUs) are small, cheap, energy efficient, and widely employed in smart devices and mobile robots. Exploiting inertial data for accurate and reliable pedestrian navigation supports is a key component for emerging Internet-of-Things applications and services. Recently, there has been a growing interest in applying deep neural networks (DNNs) to motion sensing and location estimation. However, the lack of sufficient labelled data for training and evaluating architecture benchmarks has limited the adoption of DNNs in IMU-based tasks. In this paper, we present and release the Oxford Inertial Odometry Dataset (OxIOD), a first-of-its-kind public dataset for deep learning based inertial navigation research, with fine-grained ground-truth on all sequences. Furthermore, to enable more efficient inference at the edge, we propose a novel lightweight framework to learn and reconstruct pedestrian trajectories from raw IMU data. Extensive experiments show the effectiveness of our dataset and methods in achieving accurate data-driven pedestrian inertial navigation on resource-constrained devices.
SelectFusion: A Generic Framework to Selectively Learn Multisensory Fusion
Dec 30, 2019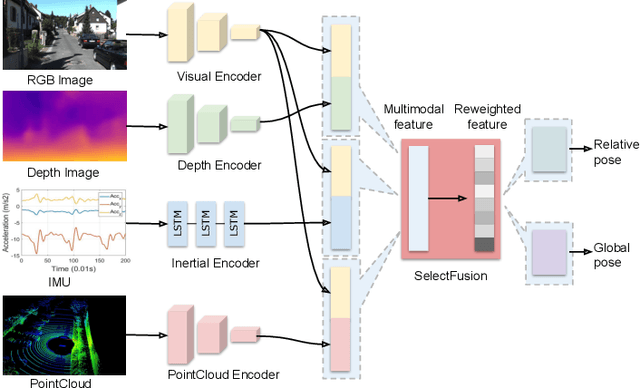

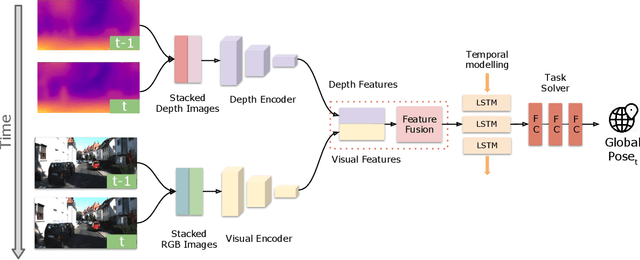
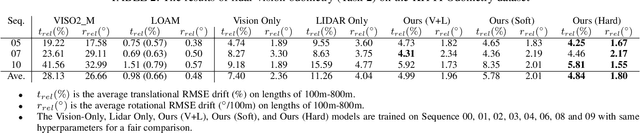
Autonomous vehicles and mobile robotic systems are typically equipped with multiple sensors to provide redundancy. By integrating the observations from different sensors, these mobile agents are able to perceive the environment and estimate system states, e.g. locations and orientations. Although deep learning approaches for multimodal odometry estimation and localization have gained traction, they rarely focus on the issue of robust sensor fusion - a necessary consideration to deal with noisy or incomplete sensor observations in the real world. Moreover, current deep odometry models also suffer from a lack of interpretability. To this extent, we propose SelectFusion, an end-to-end selective sensor fusion module which can be applied to useful pairs of sensor modalities such as monocular images and inertial measurements, depth images and LIDAR point clouds. During prediction, the network is able to assess the reliability of the latent features from different sensor modalities and estimate both trajectory at scale and global pose. In particular, we propose two fusion modules based on different attention strategies: deterministic soft fusion and stochastic hard fusion, and we offer a comprehensive study of the new strategies compared to trivial direct fusion. We evaluate all fusion strategies in both ideal conditions and on progressively degraded datasets that present occlusions, noisy and missing data and time misalignment between sensors, and we investigate the effectiveness of the different fusion strategies in attending the most reliable features, which in itself, provides insights into the operation of the various models.
Snoopy: Sniffing Your Smartwatch Passwords via Deep Sequence Learning
Dec 11, 2019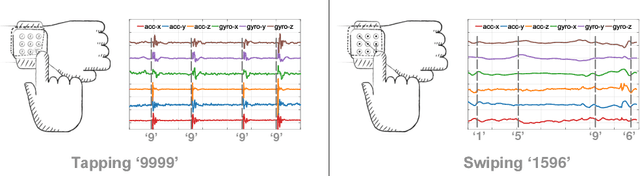
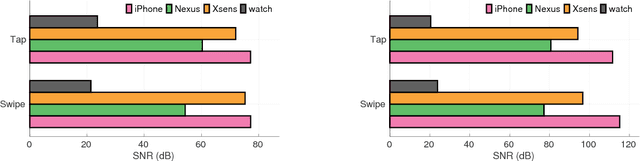
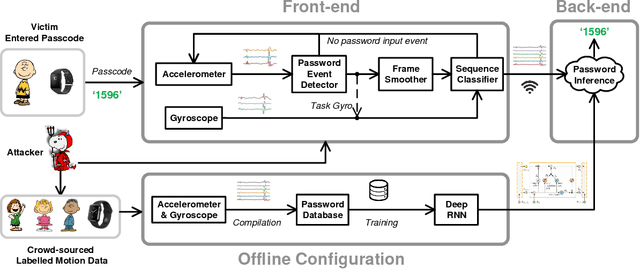
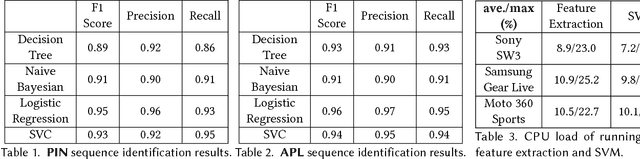
Demand for smartwatches has taken off in recent years with new models which can run independently from smartphones and provide more useful features, becoming first-class mobile platforms. One can access online banking or even make payments on a smartwatch without a paired phone. This makes smartwatches more attractive and vulnerable to malicious attacks, which to date have been largely overlooked. In this paper, we demonstrate Snoopy, a password extraction and inference system which is able to accurately infer passwords entered on Android/Apple watches within 20 attempts, just by eavesdropping on motion sensors. Snoopy uses a uniform framework to extract the segments of motion data when passwords are entered, and uses novel deep neural networks to infer the actual passwords. We evaluate the proposed Snoopy system in the real-world with data from 362 participants and show that our system offers a 3-fold improvement in the accuracy of inferring passwords compared to the state-of-the-art, without consuming excessive energy or computational resources. We also show that Snoopy is very resilient to user and device heterogeneity: it can be trained on crowd-sourced motion data (e.g. via Amazon Mechanical Turk), and then used to attack passwords from a new user, even if they are wearing a different model. This paper shows that, in the wrong hands, Snoopy can potentially cause serious leaks of sensitive information. By raising awareness, we invite the community and manufacturers to revisit the risks of continuous motion sensing on smart wearable devices.
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Nov 25, 2019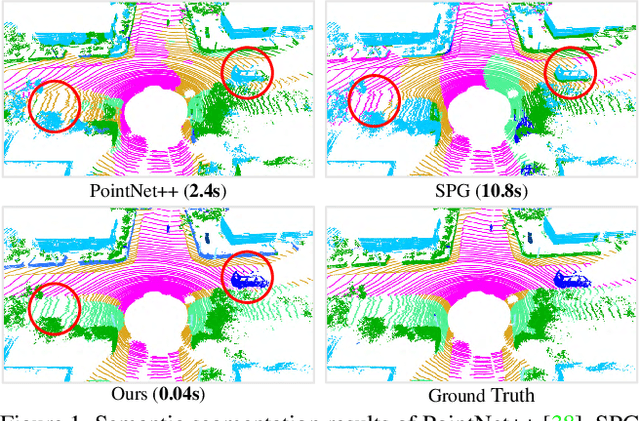
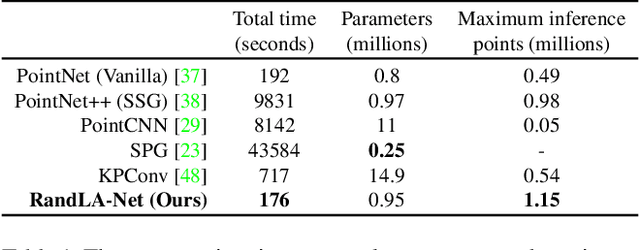
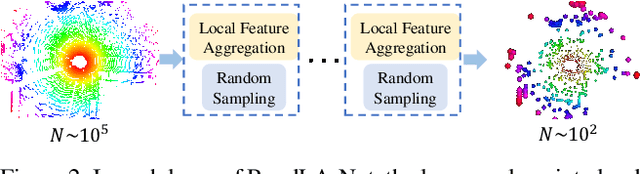
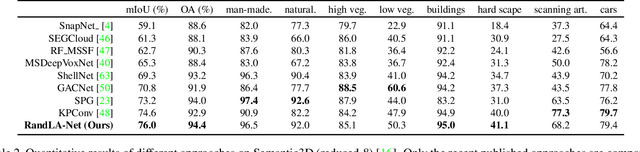
We study the problem of efficient semantic segmentation for large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Extensive experiments show that our RandLA-Net can process 1 million points in a single pass with up to 200X faster than existing approaches. Moreover, our RandLA-Net clearly surpasses state-of-the-art approaches for semantic segmentation on two large-scale benchmarks Semantic3D and SemanticKITTI.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019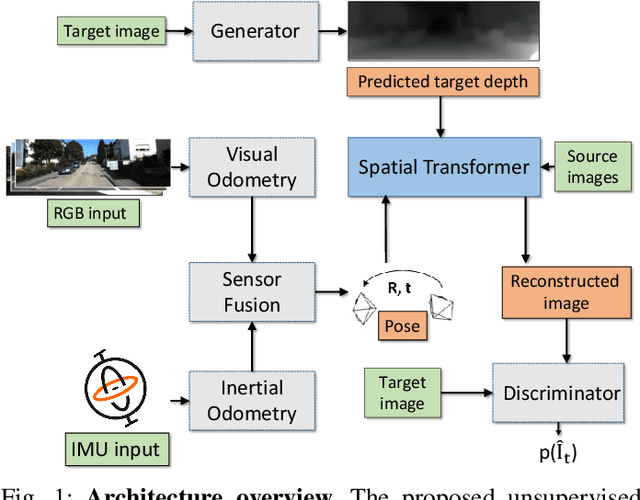
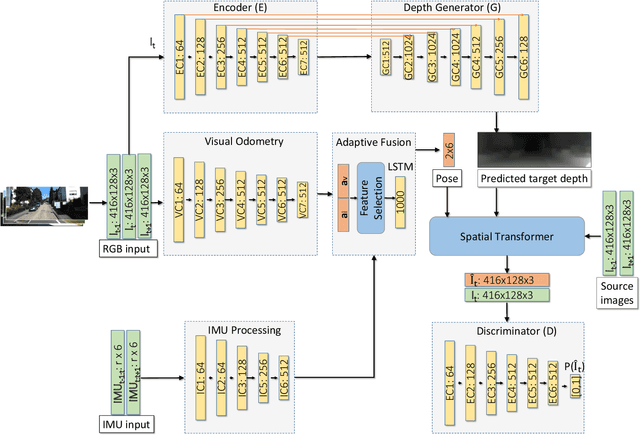
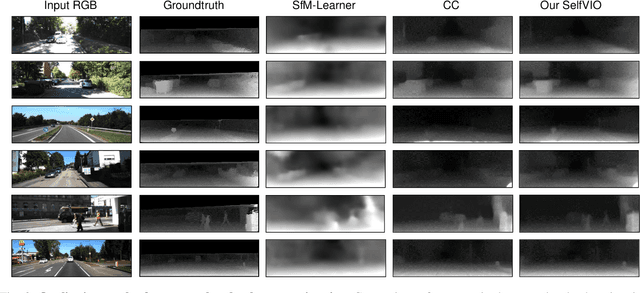

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.
Introducing an Explicit Symplectic Integration Scheme for Riemannian Manifold Hamiltonian Monte Carlo
Oct 14, 2019

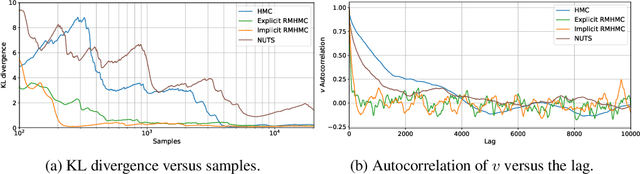
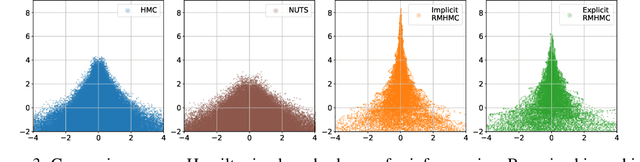
We introduce a recent symplectic integration scheme derived for solving physically motivated systems with non-separable Hamiltonians. We show its relevance to Riemannian manifold Hamiltonian Monte Carlo (RMHMC) and provide an alternative to the currently used generalised leapfrog symplectic integrator, which relies on solving multiple fixed point iterations to convergence. Via this approach, we are able to reduce the number of higher-order derivative calculations per leapfrog step. We explore the implications of this integrator and demonstrate its efficacy in reducing the computational burden of RMHMC. Our code is provided in a new open-source Python package, hamiltorch.
DeepPCO: End-to-End Point Cloud Odometry through Deep Parallel Neural Network
Oct 13, 2019
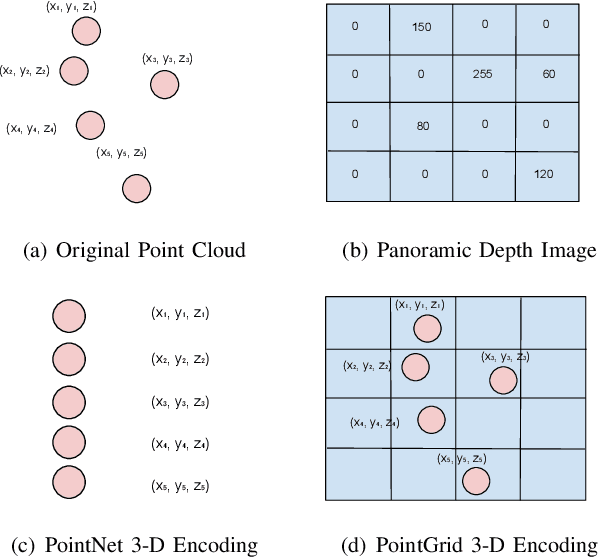
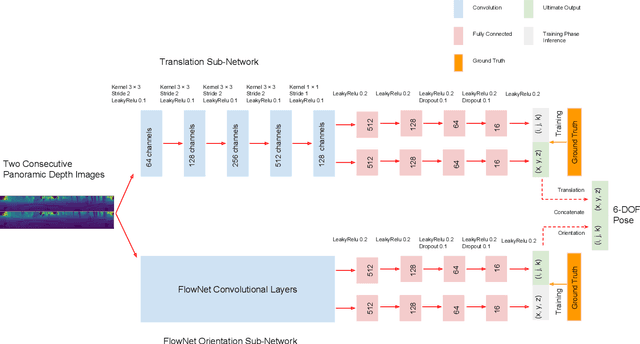
Odometry is of key importance for localization in the absence of a map. There is considerable work in the area of visual odometry (VO), and recent advances in deep learning have brought novel approaches to VO, which directly learn salient features from raw images. These learning-based approaches have led to more accurate and robust VO systems. However, they have not been well applied to point cloud data yet. In this work, we investigate how to exploit deep learning to estimate point cloud odometry (PCO), which may serve as a critical component in point cloud-based downstream tasks or learning-based systems. Specifically, we propose a novel end-to-end deep parallel neural network called DeepPCO, which can estimate the 6-DOF poses using consecutive point clouds. It consists of two parallel sub-networks to estimate 3-D translation and orientation respectively rather than a single neural network. We validate our approach on KITTI Visual Odometry/SLAM benchmark dataset with different baselines. Experiments demonstrate that the proposed approach achieves good performance in terms of pose accuracy.