 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtea: Client Profiling within Federated Systems using Flower
Jul 03, 2022
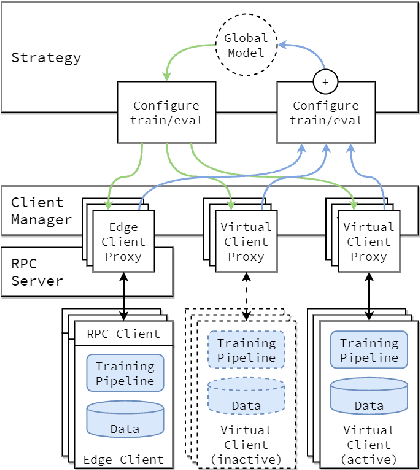
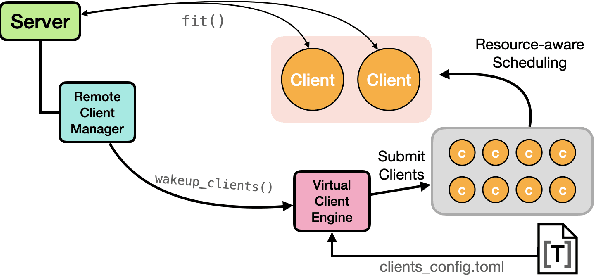
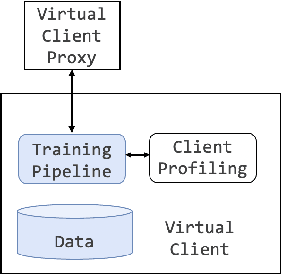
Federated Learning (FL) has emerged as a prospective solution that facilitates the training of a high-performing centralised model without compromising the privacy of users. While successful, research is currently limited by the possibility of establishing a realistic large-scale FL system at the early stages of experimentation. Simulation can help accelerate this process. To facilitate efficient scalable FL simulation of heterogeneous clients, we design and implement Protea, a flexible and lightweight client profiling component within federated systems using the FL framework Flower. It allows automatically collecting system-level statistics and estimating the resources needed for each client, thus running the simulation in a resource-aware fashion. The results show that our design successfully increases parallelism for 1.66 $\times$ faster wall-clock time and 2.6$\times$ better GPU utilisation, which enables large-scale experiments on heterogeneous clients.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019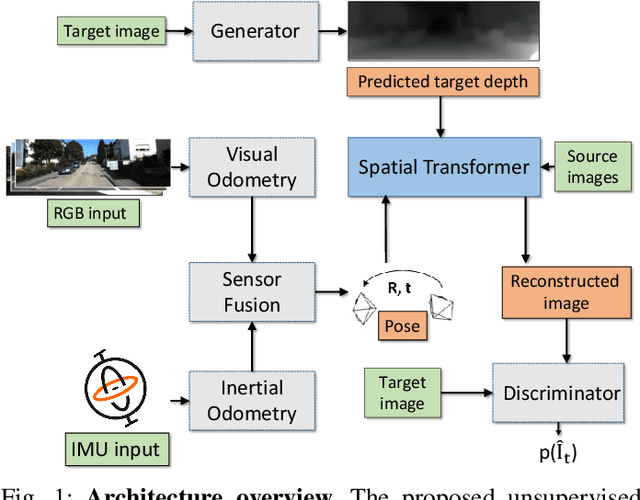
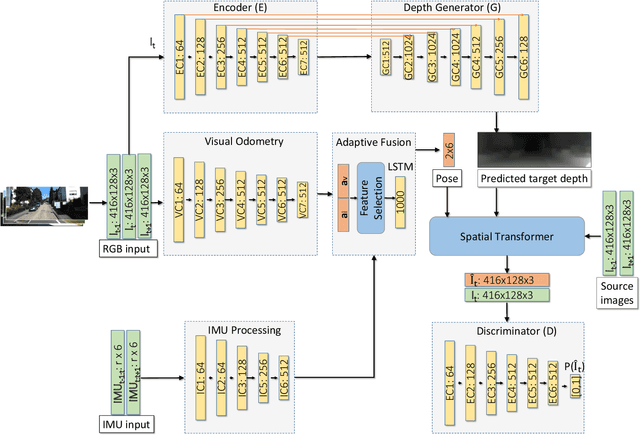
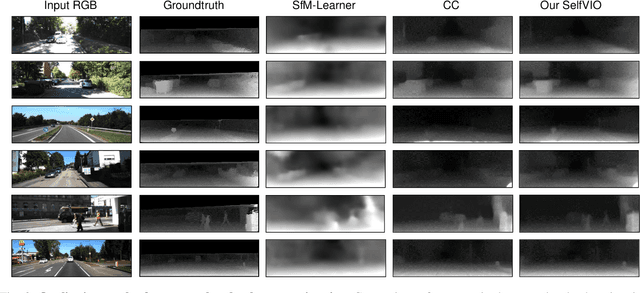

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.