 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Jul 06, 2021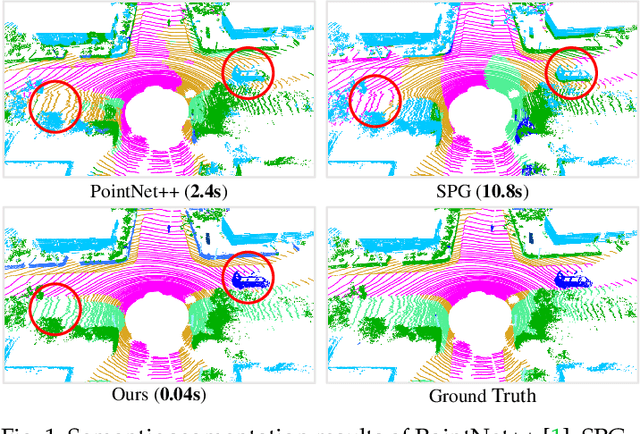
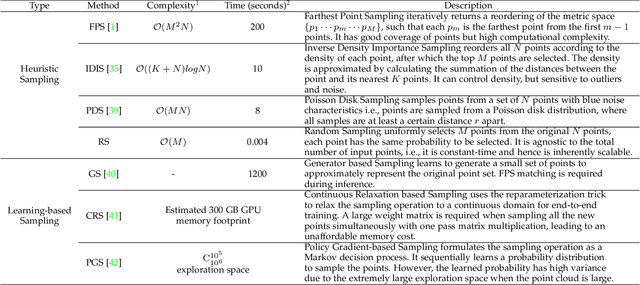
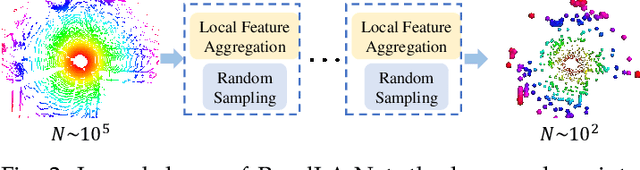
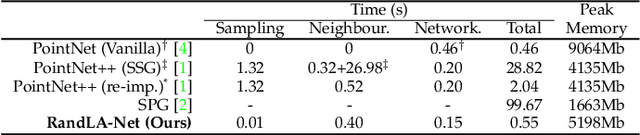
We study the problem of efficient semantic segmentation of large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Comparative experiments show that our RandLA-Net can process 1 million points in a single pass up to 200x faster than existing approaches. Moreover, extensive experiments on five large-scale point cloud datasets, including Semantic3D, SemanticKITTI, Toronto3D, NPM3D and S3DIS, demonstrate the state-of-the-art semantic segmentation performance of our RandLA-Net.
SoundDet: Polyphonic Sound Event Detection and Localization from Raw Waveform
Jun 13, 2021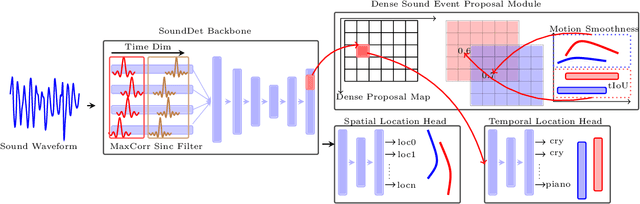
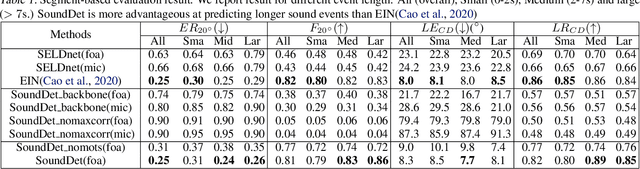
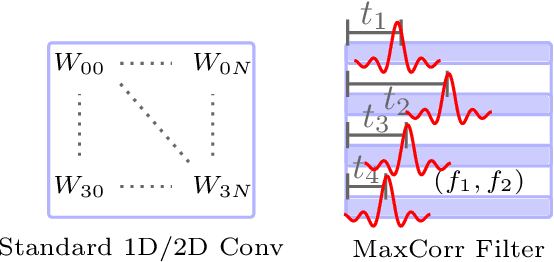
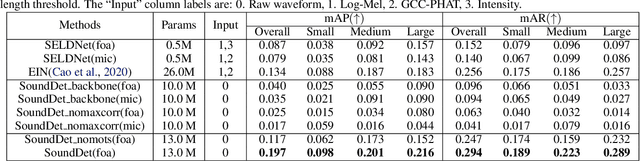
We present a new framework SoundDet, which is an end-to-end trainable and light-weight framework, for polyphonic moving sound event detection and localization. Prior methods typically approach this problem by preprocessing raw waveform into time-frequency representations, which is more amenable to process with well-established image processing pipelines. Prior methods also detect in segment-wise manner, leading to incomplete and partial detections. SoundDet takes a novel approach and directly consumes the raw, multichannel waveform and treats the spatio-temporal sound event as a complete ``sound-object" to be detected. Specifically, SoundDet consists of a backbone neural network and two parallel heads for temporal detection and spatial localization, respectively. Given the large sampling rate of raw waveform, the backbone network first learns a set of phase-sensitive and frequency-selective bank of filters to explicitly retain direction-of-arrival information, whilst being highly computationally and parametrically efficient than standard 1D/2D convolution. A dense sound event proposal map is then constructed to handle the challenges of predicting events with large varying temporal duration. Accompanying the dense proposal map are a temporal overlapness map and a motion smoothness map that measure a proposal's confidence to be an event from temporal detection accuracy and movement consistency perspective. Involving the two maps guarantees SoundDet to be trained in a spatio-temporally unified manner. Experimental results on the public DCASE dataset show the advantage of SoundDet on both segment-based and our newly proposed event-based evaluation system.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021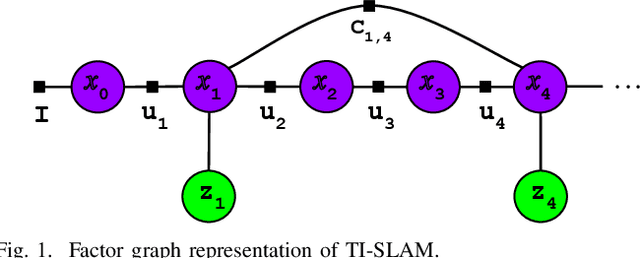
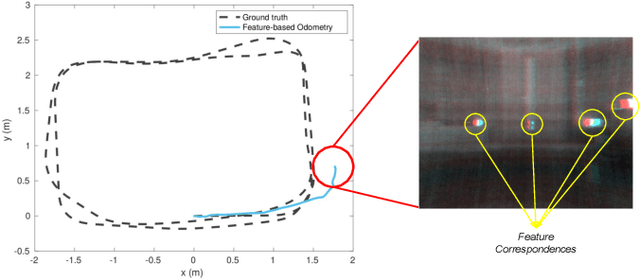
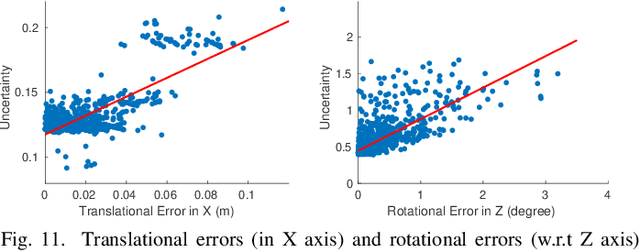
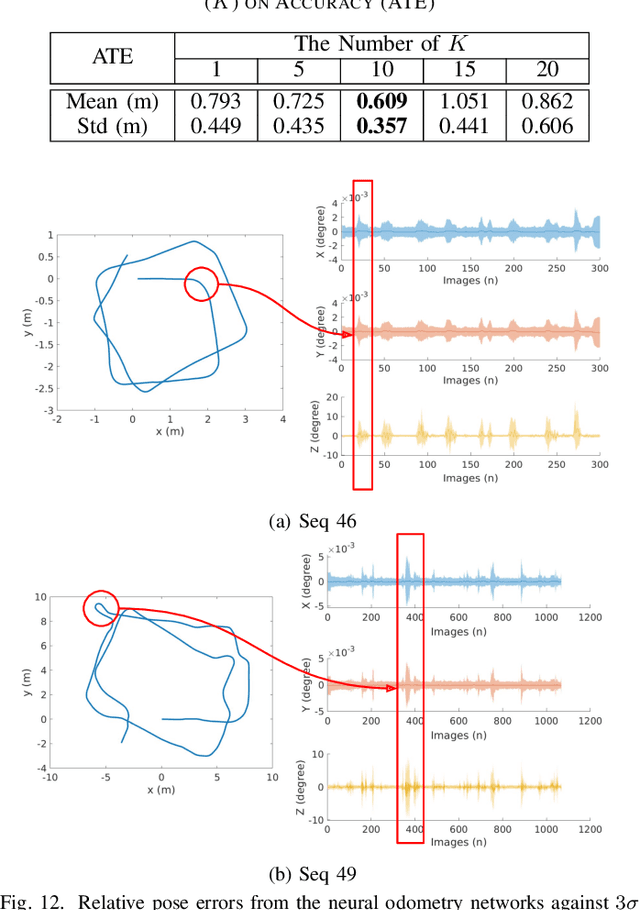
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds with 1000x Fewer Labels
Apr 11, 2021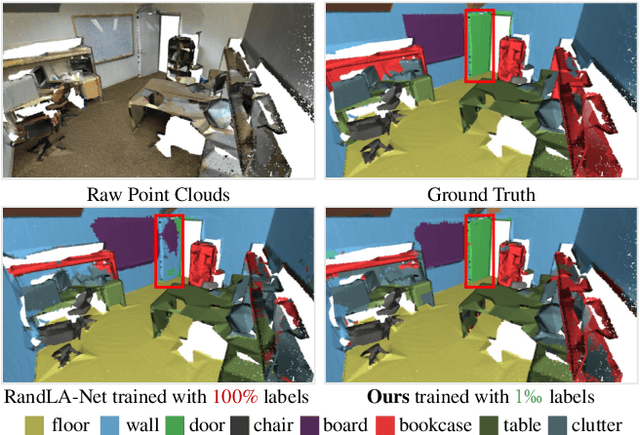
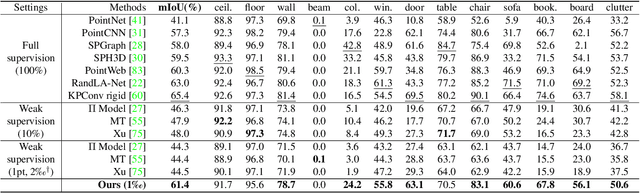
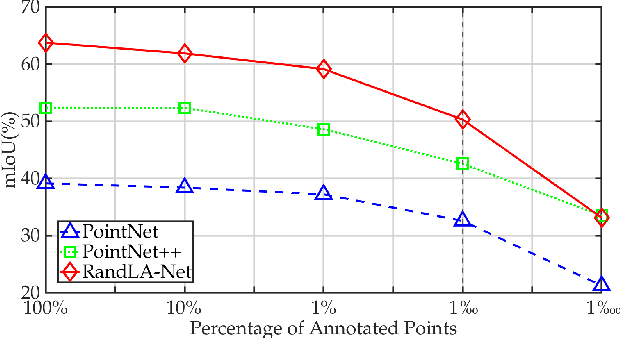
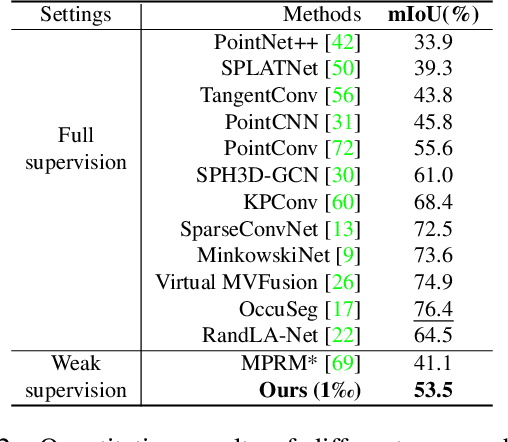
We study the problem of labelling effort for semantic segmentation of large-scale 3D point clouds. Existing works usually rely on densely annotated point-level semantic labels to provide supervision for network training. However, in real-world scenarios that contain billions of points, it is impractical and extremely costly to manually annotate every single point. In this paper, we first investigate whether dense 3D labels are truly required for learning meaningful semantic representations. Interestingly, we find that the segmentation performance of existing works only drops slightly given as few as 1% of the annotations. However, beyond this point (e.g. 1 per thousand and below) existing techniques fail catastrophically. To this end, we propose a new weak supervision method to implicitly augment the total amount of available supervision signals, by leveraging the semantic similarity between neighboring points. Extensive experiments demonstrate that the proposed Semantic Query Network (SQN) achieves state-of-the-art performance on six large-scale open datasets under weak supervision schemes, while requiring only 1000x fewer labeled points for training. The code is available at https://github.com/QingyongHu/SQN.
RadarLoc: Learning to Relocalize in FMCW Radar
Mar 22, 2021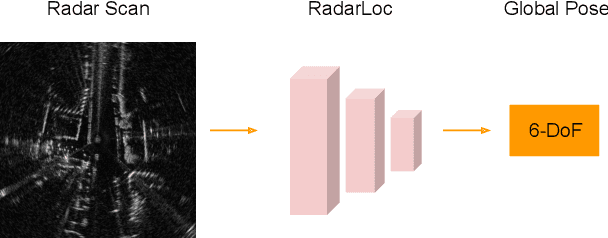
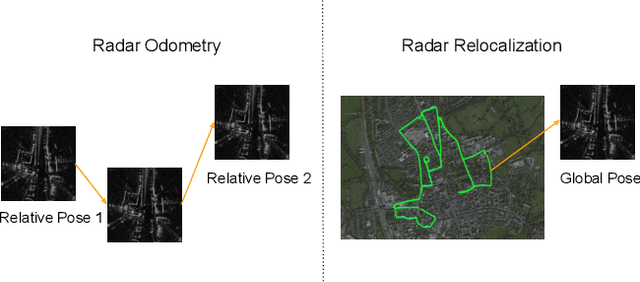
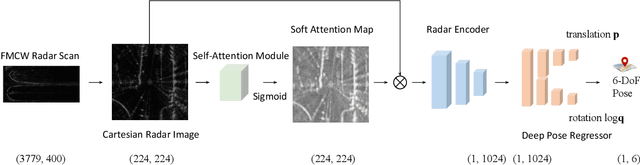
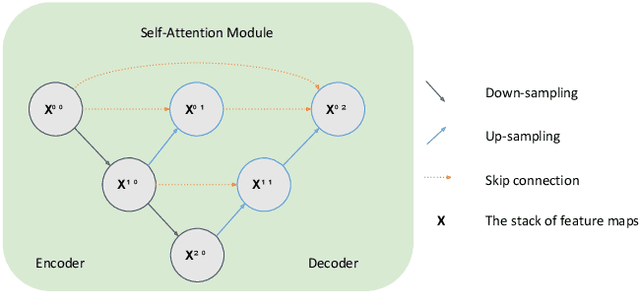
Relocalization is a fundamental task in the field of robotics and computer vision. There is considerable work in the field of deep camera relocalization, which directly estimates poses from raw images. However, learning-based methods have not yet been applied to the radar sensory data. In this work, we investigate how to exploit deep learning to predict global poses from Emerging Frequency-Modulated Continuous Wave (FMCW) radar scans. Specifically, we propose a novel end-to-end neural network with self-attention, termed RadarLoc, which is able to estimate 6-DoF global poses directly. We also propose to improve the localization performance by utilizing geometric constraints between radar scans. We validate our approach on the recently released challenging outdoor dataset Oxford Radar RobotCar. Comprehensive experiments demonstrate that the proposed method outperforms radar-based localization and deep camera relocalization methods by a significant margin.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021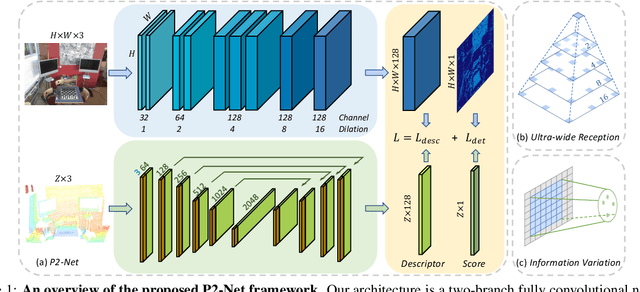
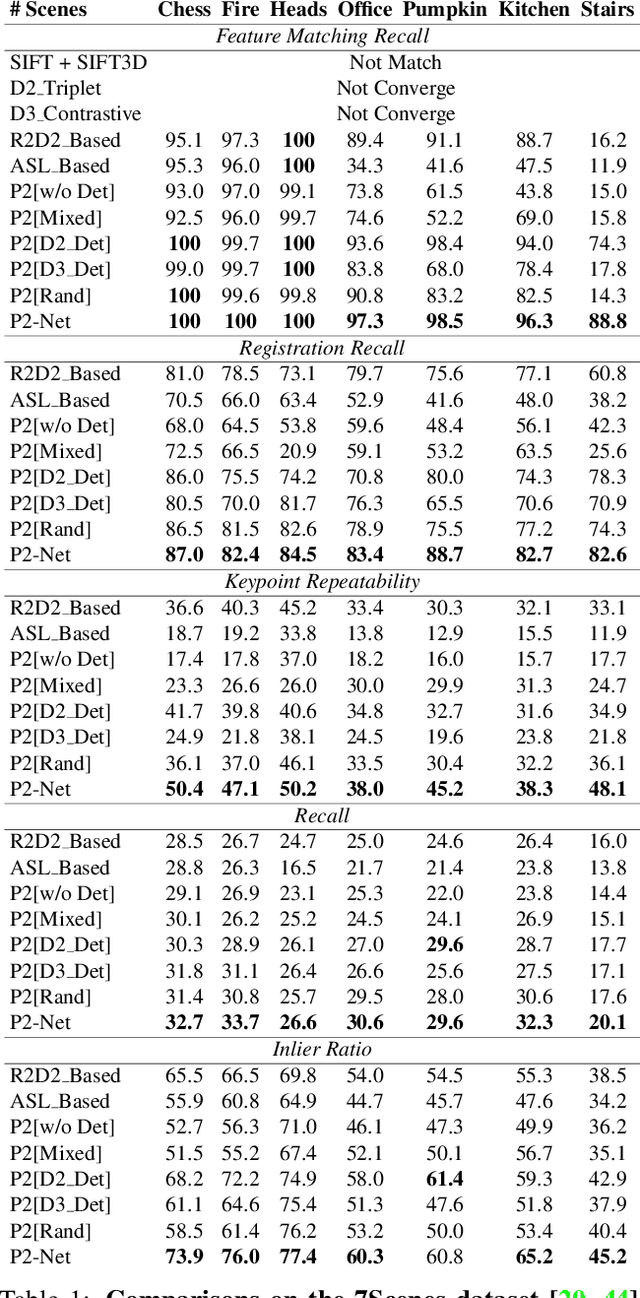
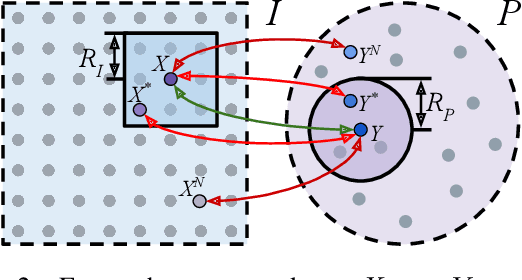
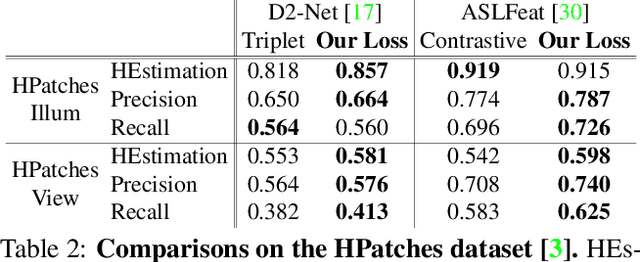
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].
SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration
Nov 24, 2020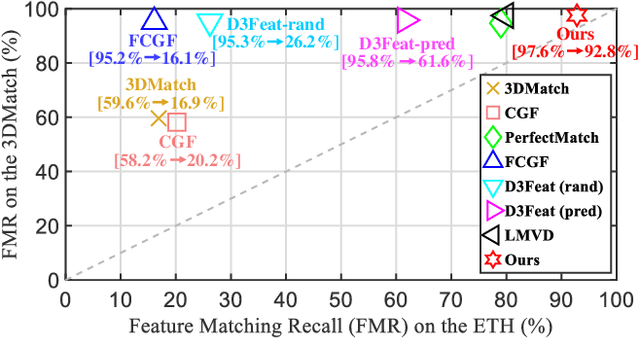
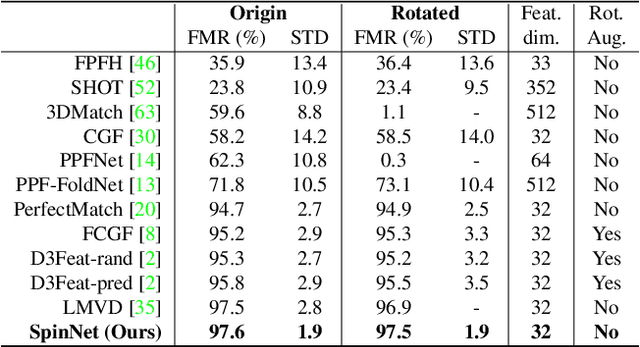
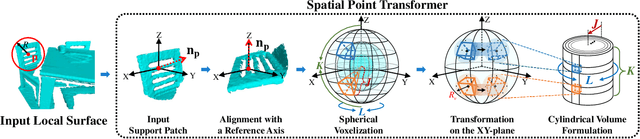
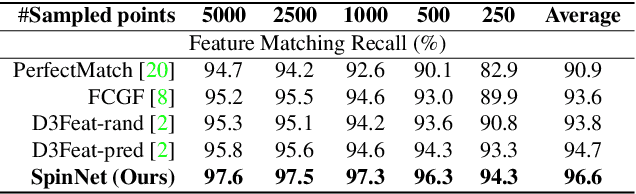
Extracting robust and general 3D local features is key to downstream tasks such as point cloud registration and reconstruction. Existing learning-based local descriptors are either sensitive to rotation transformations, or rely on classical handcrafted features which are neither general nor representative. In this paper, we introduce a new, yet conceptually simple, neural architecture, termed SpinNet, to extract local features which are rotationally invariant whilst sufficiently informative to enable accurate registration. A Spatial Point Transformer is first introduced to map the input local surface into a carefully designed cylindrical space, enabling end-to-end optimization with SO(2) equivariant representation. A Neural Feature Extractor which leverages the powerful point-based and 3D cylindrical convolutional neural layers is then utilized to derive a compact and representative descriptor for matching. Extensive experiments on both indoor and outdoor datasets demonstrate that SpinNet outperforms existing state-of-the-art techniques by a large margin. More critically, it has the best generalization ability across unseen scenarios with different sensor modalities. The code is available at https://github.com/QingyongHu/SpinNet.
3-D Motion Capture of an Unmodified Drone with Single-chip Millimeter Wave Radar
Nov 13, 2020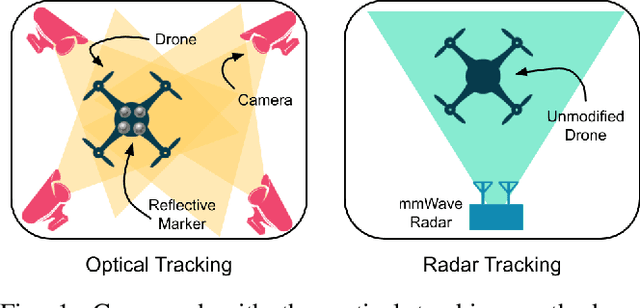
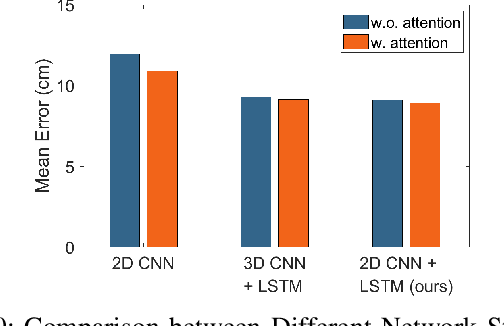
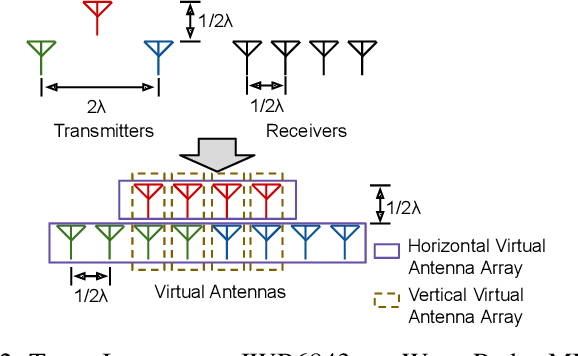
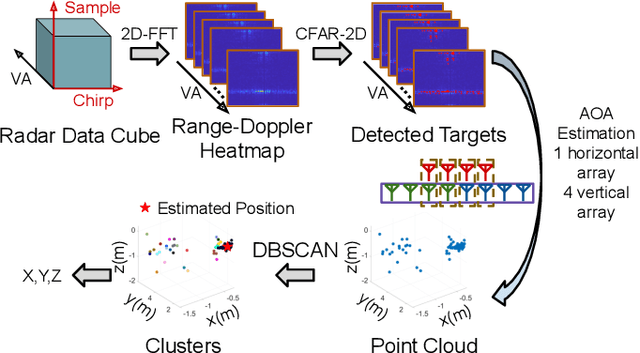
Accurate motion capture of aerial robots in 3-D is a key enabler for autonomous operation in indoor environments such as warehouses or factories, as well as driving forward research in these areas. The most commonly used solutions at present are optical motion capture (e.g. VICON) and Ultrawideband (UWB), but these are costly and cumbersome to deploy, due to their requirement of multiple cameras/sensors spaced around the tracking area. They also require the drone to be modified to carry an active or passive marker. In this work, we present an inexpensive system that can be rapidly installed, based on single-chip millimeter wave (mmWave) radar. Importantly, the drone does not need to be modified or equipped with any markers, as we exploit the Doppler signals from the rotating propellers. Furthermore, 3-D tracking is possible from a single point, greatly simplifying deployment. We develop a novel deep neural network and demonstrate decimeter level 3-D tracking at 10Hz, achieving better performance than classical baselines. Our hope is that this low-cost system will act to catalyse inexpensive drone research and increased autonomy.
Demo Abstract: Indoor Positioning System in Visually-Degraded Environments with Millimetre-Wave Radar and Inertial Sensors
Oct 26, 2020
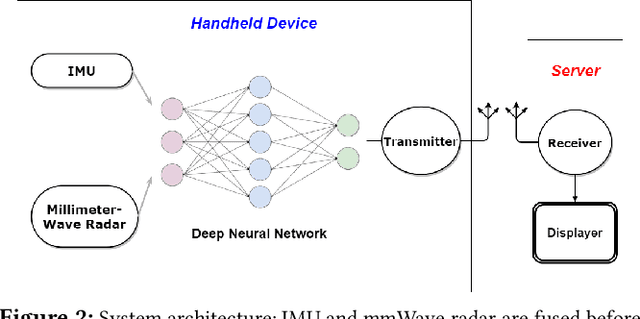
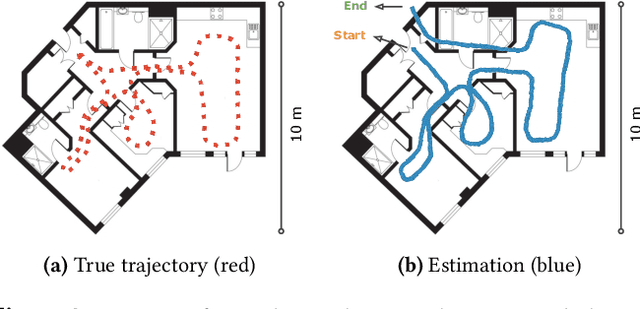
Positional estimation is of great importance in the public safety sector. Emergency responders such as fire fighters, medical rescue teams, and the police will all benefit from a resilient positioning system to deliver safe and effective emergency services. Unfortunately, satellite navigation (e.g., GPS) offers limited coverage in indoor environments. It is also not possible to rely on infrastructure based solutions. To this end, wearable sensor-aided navigation techniques, such as those based on camera and Inertial Measurement Units (IMU), have recently emerged recently as an accurate, infrastructure-free solution. Together with an increase in the computational capabilities of mobile devices, motion estimation can be performed in real-time. In this demonstration, we present a real-time indoor positioning system which fuses millimetre-wave (mmWave) radar and IMU data via deep sensor fusion. We employ mmWave radar rather than an RGB camera as it provides better robustness to visual degradation (e.g., smoke, darkness, etc.) while at the same time requiring lower computational resources to enable runtime computation. We implemented the sensor system on a handheld device and a mobile computer running at 10 FPS to track a user inside an apartment. Good accuracy and resilience were exhibited even in poorly illuminated scenes.
Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
Sep 07, 2020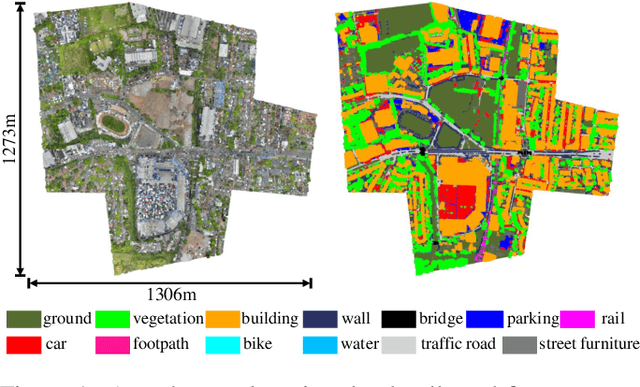
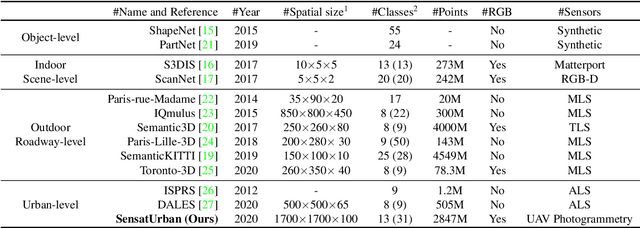
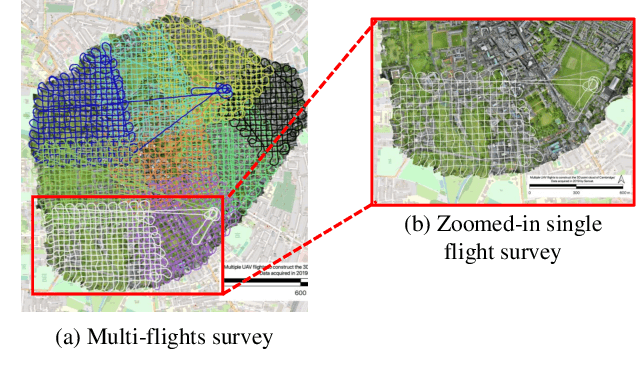
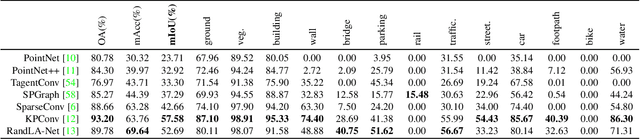
An essential prerequisite for unleashing the potential of supervised deep learning algorithms in the area of 3D scene understanding is the availability of large-scale and richly annotated datasets. However, publicly available datasets are either in relative small spatial scales or have limited semantic annotations due to the expensive cost of data acquisition and data annotation, which severely limits the development of fine-grained semantic understanding in the context of 3D point clouds. In this paper, we present an urban-scale photogrammetric point cloud dataset with nearly three billion richly annotated points, which is five times the number of labeled points than the existing largest point cloud dataset. Our dataset consists of large areas from two UK cities, covering about 6 $km^2$ of the city landscape. In the dataset, each 3D point is labeled as one of 13 semantic classes. We extensively evaluate the performance of state-of-the-art algorithms on our dataset and provide a comprehensive analysis of the results. In particular, we identify several key challenges towards urban-scale point cloud understanding. The dataset is available at https://github.com/QingyongHu/SensatUrban.