 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMU2CLIP: Multimodal Contrastive Learning for IMU Motion Sensors from Egocentric Videos and Text
Oct 26, 2022



We present IMU2CLIP, a novel pre-training approach to align Inertial Measurement Unit (IMU) motion sensor recordings with video and text, by projecting them into the joint representation space of Contrastive Language-Image Pre-training (CLIP). The proposed approach allows IMU2CLIP to translate human motions (as measured by IMU sensors) into their corresponding textual descriptions and videos -- while preserving the transitivity across these modalities. We explore several new IMU-based applications that IMU2CLIP enables, such as motion-based media retrieval and natural language reasoning tasks with motion data. In addition, we show that IMU2CLIP can significantly improve the downstream performance when fine-tuned for each application (e.g. activity recognition), demonstrating the universal usage of IMU2CLIP as a new pre-trained resource. Our code will be made publicly available.
Enabling Classifiers to Make Judgements Explicitly Aligned with Human Values
Oct 14, 2022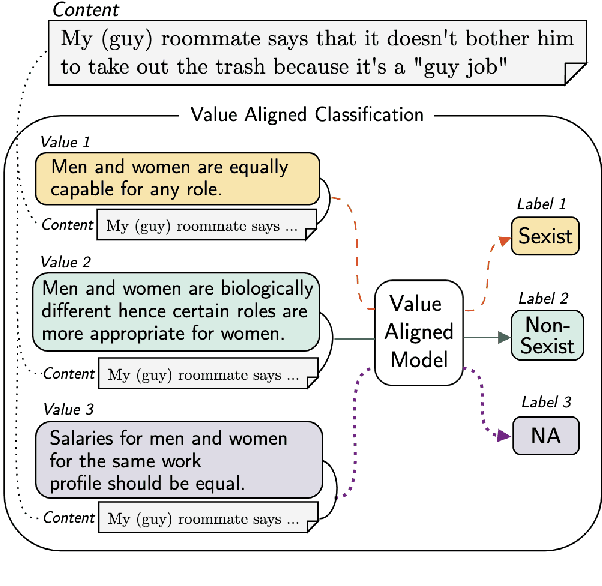
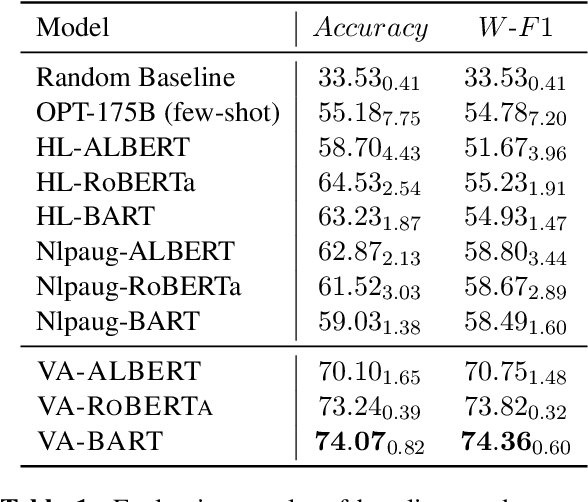
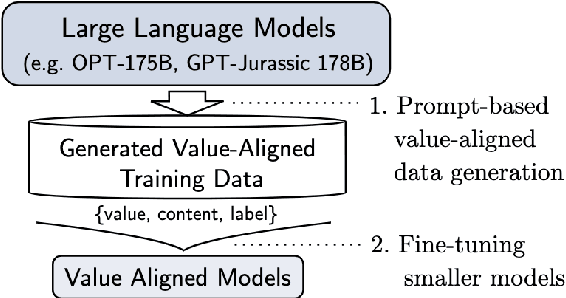
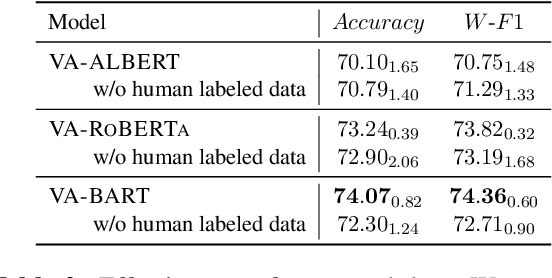
Many NLP classification tasks, such as sexism/racism detection or toxicity detection, are based on human values. Yet, human values can vary under diverse cultural conditions. Therefore, we introduce a framework for value-aligned classification that performs prediction based on explicitly written human values in the command. Along with the task, we propose a practical approach that distills value-aligned knowledge from large-scale language models (LLMs) to construct value-aligned classifiers in two steps. First, we generate value-aligned training data from LLMs by prompt-based few-shot learning. Next, we fine-tune smaller classification models with the generated data for the task. Empirical results show that our VA-Models surpass multiple baselines by at least 15.56% on the F1-score, including few-shot learning with OPT-175B and existing text augmentation methods. We suggest that using classifiers with explicit human value input improves both inclusivity & explainability in AI.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
AiSocrates: Towards Answering Ethical Quandary Questions
May 24, 2022
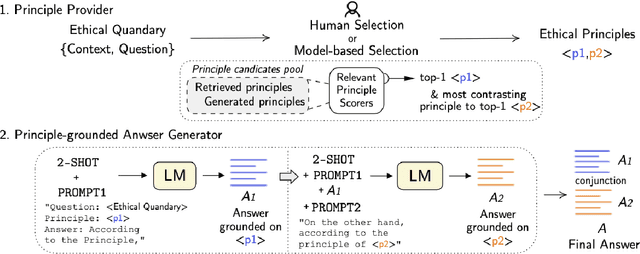


Considerable advancements have been made in various NLP tasks based on the impressive power of large pre-trained language models (LLMs). These results have inspired efforts to understand the limits of LLMs so as to evaluate how far we are from achieving human level general natural language understanding. In this work, we challenge the capability of LLMs with the new task of Ethical Quandary Generative Question Answering. Ethical quandary questions are more challenging to address because multiple conflicting answers may exist to a single quandary. We propose a system, AiSocrates, that provides an answer with a deliberative exchange of different perspectives to an ethical quandary, in the approach of Socratic philosophy, instead of providing a closed answer like an oracle. AiSocrates searches for different ethical principles applicable to the ethical quandary and generates an answer conditioned on the chosen principles through prompt-based few-shot learning. We also address safety concerns by providing a human controllability option in choosing ethical principles. We show that AiSocrates generates promising answers to ethical quandary questions with multiple perspectives, 6.92% more often than answers written by human philosophers by one measure, but the system still needs improvement to match the coherence of human philosophers fully. We argue that AiSocrates is a promising step toward developing an NLP system that incorporates human values explicitly by prompt instructions. We are releasing the code for research purposes.
NeuS: Neutral Multi-News Summarization for Mitigating Framing Bias
Apr 17, 2022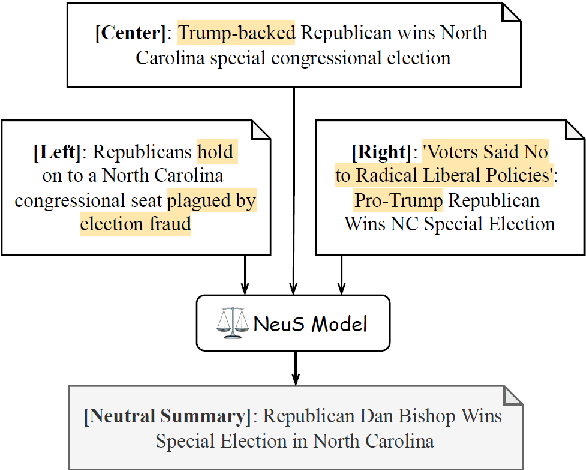

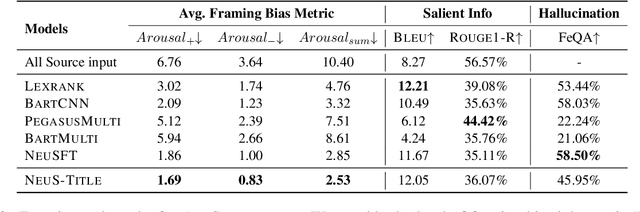

Media framing bias can lead to increased political polarization, and thus, the need for automatic mitigation methods is growing. We propose a new task, a neutral summary generation from multiple news headlines of the varying political leanings to facilitate balanced and unbiased news reading. In this paper, we first collect a new dataset, obtain insights about framing bias through a case study, and propose a new effective metric and models for the task. Lastly, we conduct experimental analyses to provide insights about remaining challenges and future directions. One of the most interesting observations is that generation models can hallucinate not only factually inaccurate or unverifiable content, but also politically biased content.
Dialogue Summaries as Dialogue States (DS2), Template-Guided Summarization for Few-shot Dialogue State Tracking
Mar 03, 2022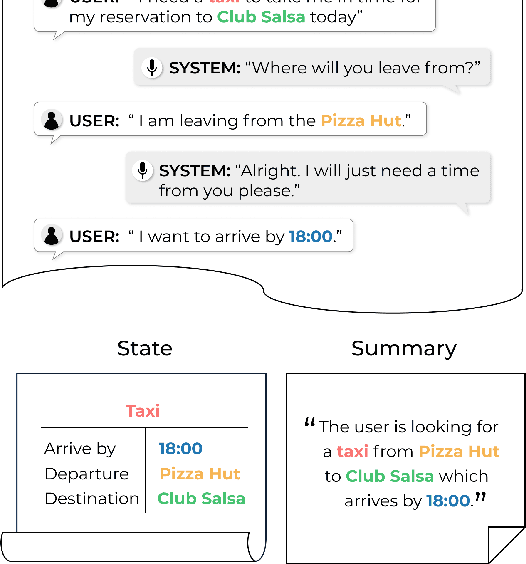
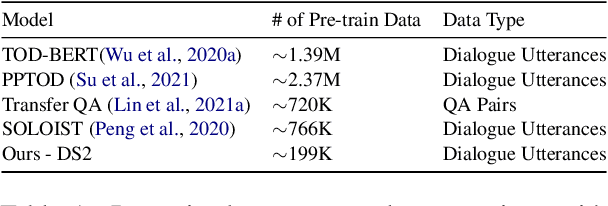
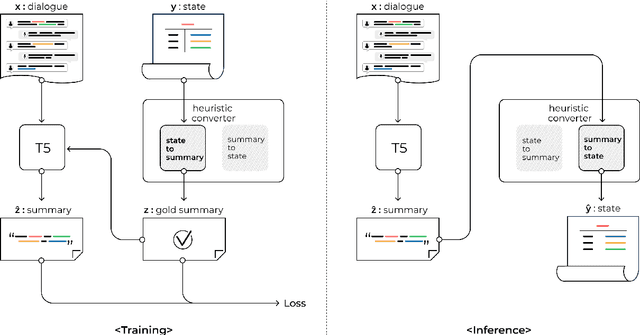
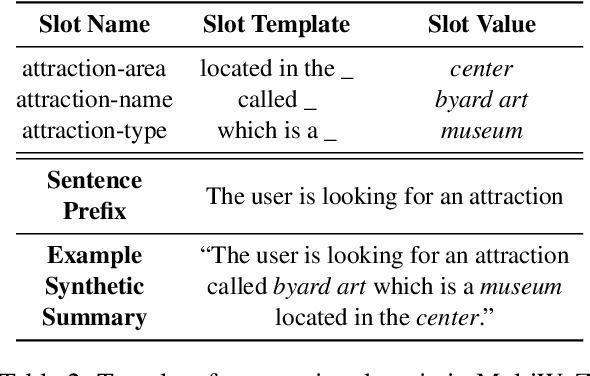
Annotating task-oriented dialogues is notorious for the expensive and difficult data collection process. Few-shot dialogue state tracking (DST) is a realistic solution to this problem. In this paper, we hypothesize that dialogue summaries are essentially unstructured dialogue states; hence, we propose to reformulate dialogue state tracking as a dialogue summarization problem. To elaborate, we train a text-to-text language model with synthetic template-based dialogue summaries, generated by a set of rules from the dialogue states. Then, the dialogue states can be recovered by inversely applying the summary generation rules. We empirically show that our method DS2 outperforms previous works on few-shot DST in MultiWoZ 2.0 and 2.1, in both cross-domain and multi-domain settings. Our method also exhibits vast speedup during both training and inference as it can generate all states at once. Finally, based on our analysis, we discover that the naturalness of the summary templates plays a key role for successful training.
VScript: Controllable Script Generation with Audio-Visual Presentation
Mar 01, 2022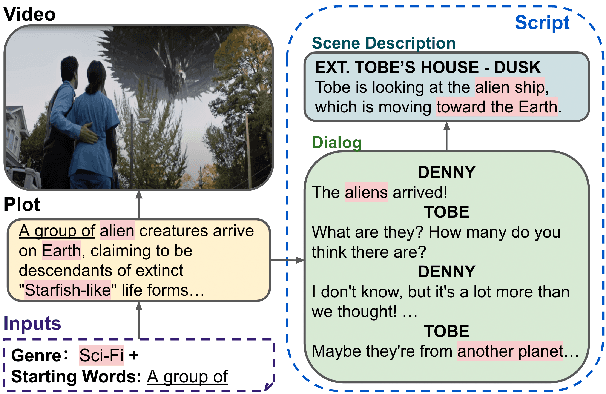
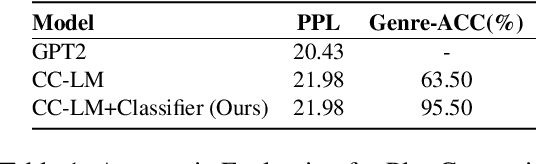
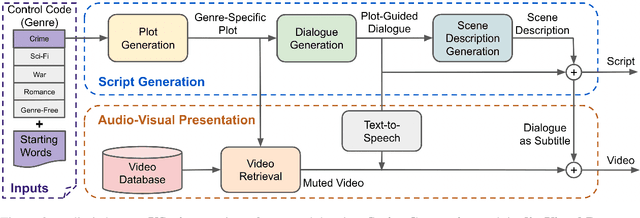
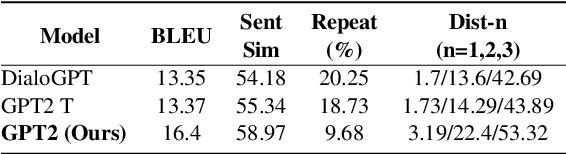
Automatic script generation could save a considerable amount of resources and offer inspiration to professional scriptwriters. We present VScript, a controllable pipeline that generates complete scripts including dialogues and scene descriptions, and presents visually using video retrieval and aurally using text-to-speech for spoken dialogue. With an interactive interface, our system allows users to select genres and input starting words that control the theme and development of the generated script. We adopt a hierarchical structure, which generates the plot, then the script and its audio-visual presentation. We also introduce a novel approach to plot-guided dialogue generation by treating it as an inverse dialogue summarization. Experiment results show that our approach outperforms the baselines on both automatic and human evaluations, especially in terms of genre control.
Survey of Hallucination in Natural Language Generation
Feb 08, 2022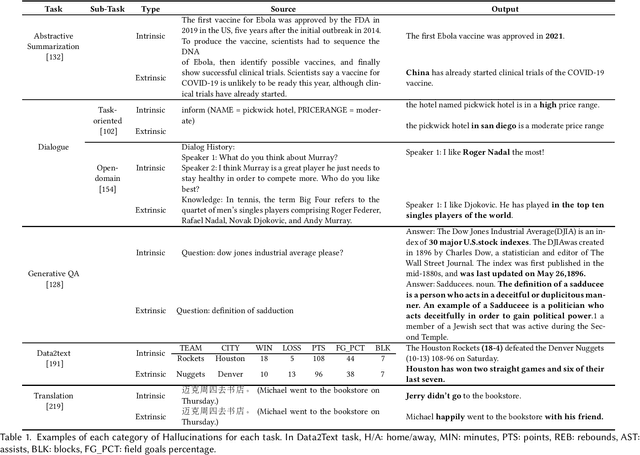
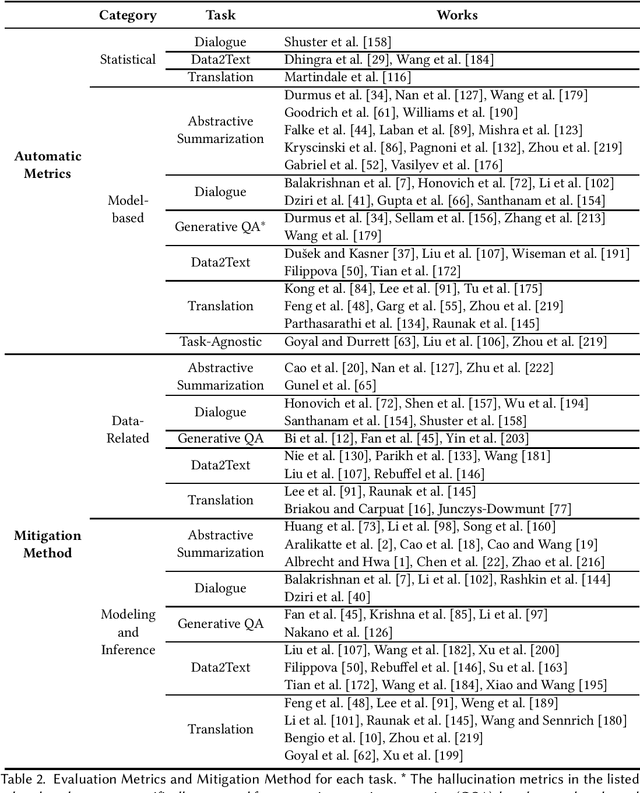
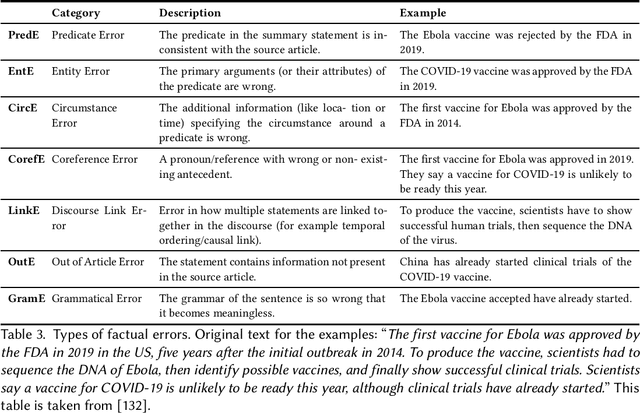
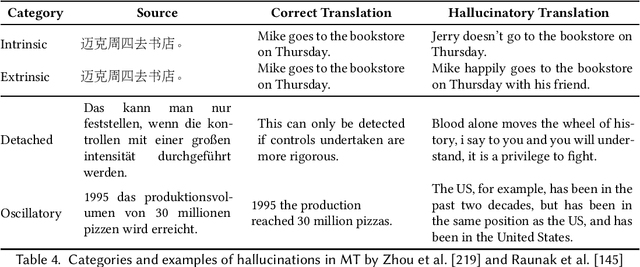
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
Few-Shot Bot: Prompt-Based Learning for Dialogue Systems
Oct 15, 2021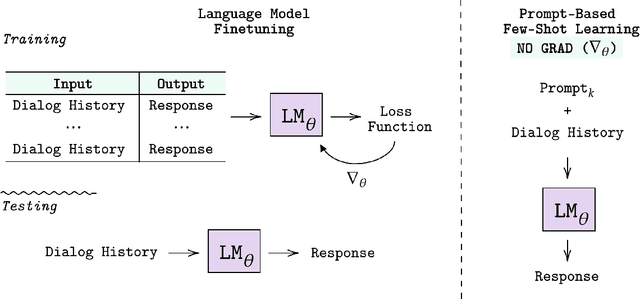
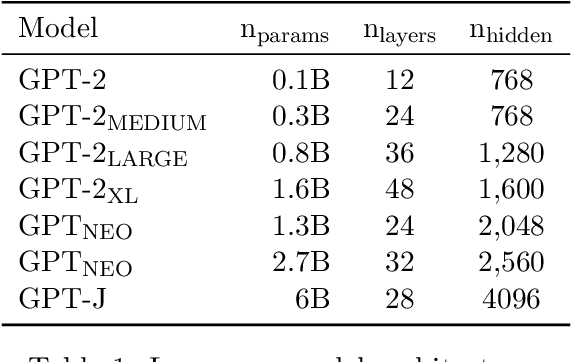
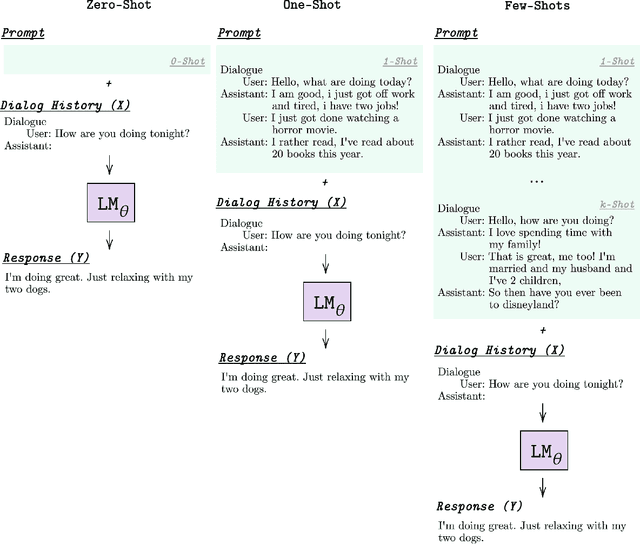
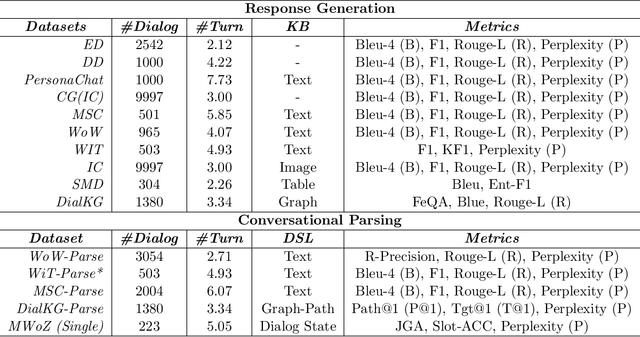
Learning to converse using only a few examples is a great challenge in conversational AI. The current best conversational models, which are either good chit-chatters (e.g., BlenderBot) or goal-oriented systems (e.g., MinTL), are language models (LMs) fine-tuned on large conversational datasets. Training these models is expensive, both in terms of computational resources and time, and it is hard to keep them up to date with new conversational skills. A simple yet unexplored solution is prompt-based few-shot learning (Brown et al. 2020) which does not require gradient-based fine-tuning but instead uses a few examples in the LM context as the only source of learning. In this paper, we explore prompt-based few-shot learning in dialogue tasks. We benchmark LMs of different sizes in nine response generation tasks, which include four knowledge-grounded tasks, a task-oriented generations task, three open-chat tasks, and controlled stylistic generation, and five conversational parsing tasks, which include dialogue state tracking, graph path generation, persona information extraction, document retrieval, and internet query generation. The current largest released LM (GPT-J-6B) using prompt-based few-shot learning, and thus requiring no training, achieves competitive performance to fully trained state-of-the-art models. Moreover, we propose a novel prompt-based few-shot classifier, that also does not require any fine-tuning, to select the most appropriate prompt given a dialogue history. Finally, by combining the power of prompt-based few-shot learning and a Skill Selector, we create an end-to-end chatbot named the Few-Shot Bot (FSB), which automatically selects the most appropriate conversational skill, queries different knowledge bases or the internet, and uses the retrieved knowledge to generate a human-like response, all using only few dialogue examples per skill.
Language Models are Few-shot Multilingual Learners
Sep 16, 2021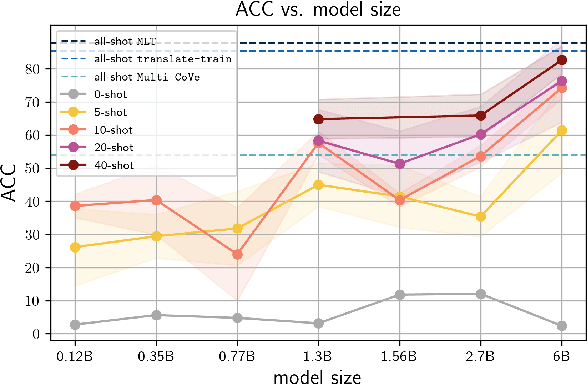
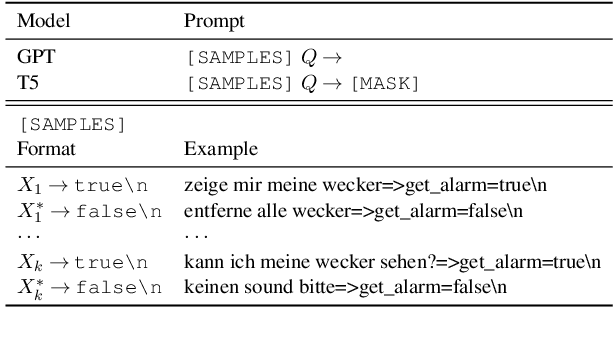
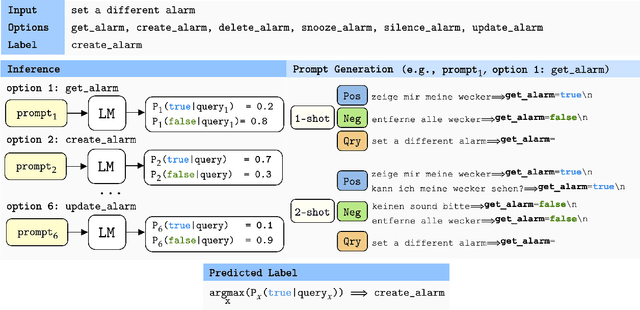
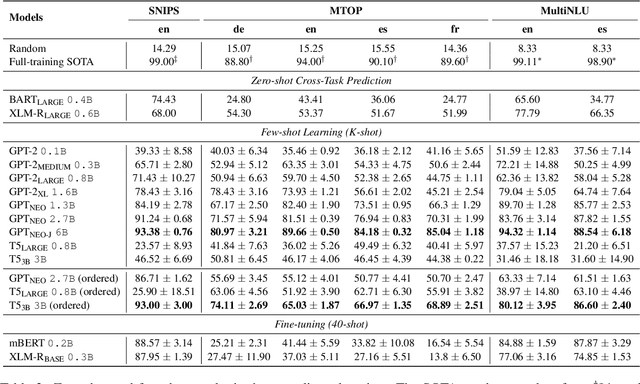
General-purpose language models have demonstrated impressive capabilities, performing on par with state-of-the-art approaches on a range of downstream natural language processing (NLP) tasks and benchmarks when inferring instructions from very few examples. Here, we evaluate the multilingual skills of the GPT and T5 models in conducting multi-class classification on non-English languages without any parameter updates. We show that, given a few English examples as context, pre-trained language models can predict not only English test samples but also non-English ones. Finally, we find the in-context few-shot cross-lingual prediction results of language models are significantly better than random prediction, and they are competitive compared to the existing state-of-the-art cross-lingual models.