 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
IMU2CLIP: Multimodal Contrastive Learning for IMU Motion Sensors from Egocentric Videos and Text
Oct 26, 2022



We present IMU2CLIP, a novel pre-training approach to align Inertial Measurement Unit (IMU) motion sensor recordings with video and text, by projecting them into the joint representation space of Contrastive Language-Image Pre-training (CLIP). The proposed approach allows IMU2CLIP to translate human motions (as measured by IMU sensors) into their corresponding textual descriptions and videos -- while preserving the transitivity across these modalities. We explore several new IMU-based applications that IMU2CLIP enables, such as motion-based media retrieval and natural language reasoning tasks with motion data. In addition, we show that IMU2CLIP can significantly improve the downstream performance when fine-tuned for each application (e.g. activity recognition), demonstrating the universal usage of IMU2CLIP as a new pre-trained resource. Our code will be made publicly available.
Connecting What to Say With Where to Look by Modeling Human Attention Traces
May 12, 2021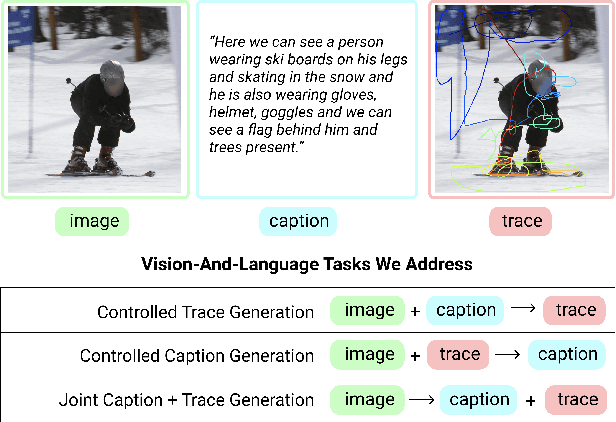

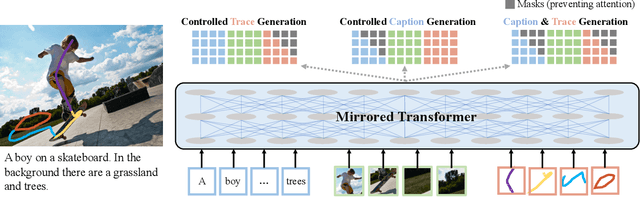
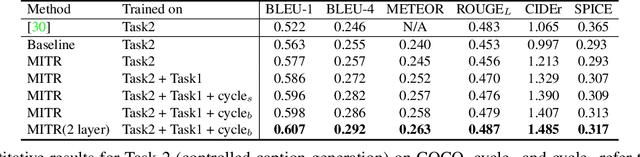
We introduce a unified framework to jointly model images, text, and human attention traces. Our work is built on top of the recent Localized Narratives annotation framework [30], where each word of a given caption is paired with a mouse trace segment. We propose two novel tasks: (1) predict a trace given an image and caption (i.e., visual grounding), and (2) predict a caption and a trace given only an image. Learning the grounding of each word is challenging, due to noise in the human-provided traces and the presence of words that cannot be meaningfully visually grounded. We present a novel model architecture that is jointly trained on dual tasks (controlled trace generation and controlled caption generation). To evaluate the quality of the generated traces, we propose a local bipartite matching (LBM) distance metric which allows the comparison of two traces of different lengths. Extensive experiments show our model is robust to the imperfect training data and outperforms the baselines by a clear margin. Moreover, we demonstrate that our model pre-trained on the proposed tasks can be also beneficial to the downstream task of COCO's guided image captioning. Our code and project page are publicly available.
What's the Point: Semantic Segmentation with Point Supervision
Jul 23, 2016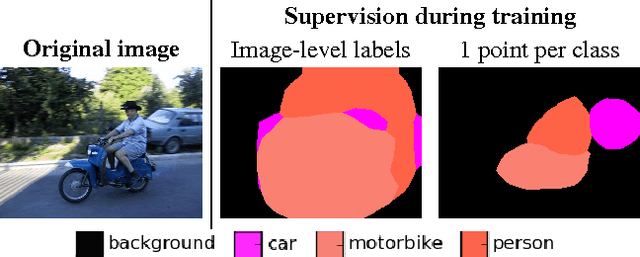
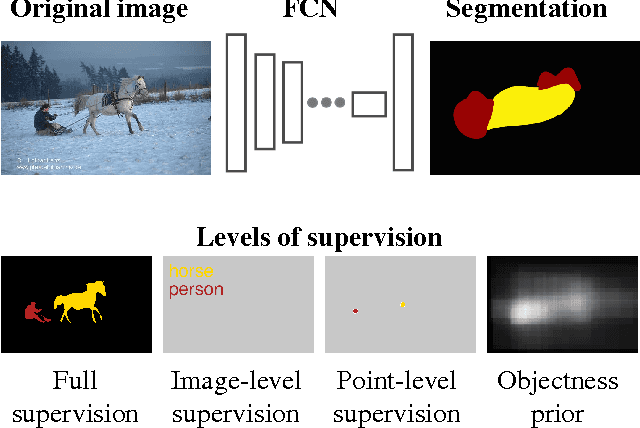
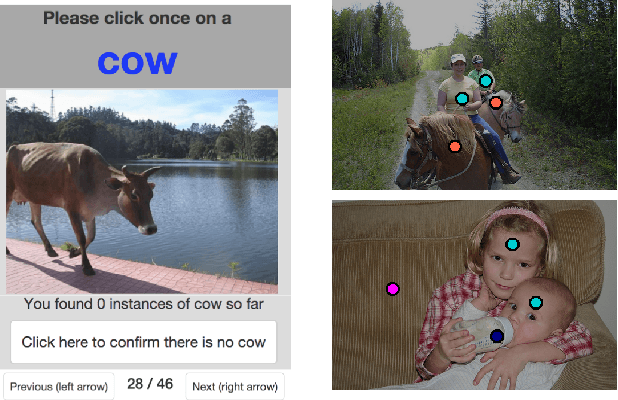

The semantic image segmentation task presents a trade-off between test time accuracy and training-time annotation cost. Detailed per-pixel annotations enable training accurate models but are very time-consuming to obtain, image-level class labels are an order of magnitude cheaper but result in less accurate models. We take a natural step from image-level annotation towards stronger supervision: we ask annotators to point to an object if one exists. We incorporate this point supervision along with a novel objectness potential in the training loss function of a CNN model. Experimental results on the PASCAL VOC 2012 benchmark reveal that the combined effect of point-level supervision and objectness potential yields an improvement of 12.9% mIOU over image-level supervision. Further, we demonstrate that models trained with point-level supervision are more accurate than models trained with image-level, squiggle-level or full supervision given a fixed annotation budget.