 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Multimodal Models to Extract Knowledge Components for Knowledge Tracing from Multimedia Question Information
Sep 30, 2024



Knowledge tracing models have enabled a range of intelligent tutoring systems to provide feedback to students. However, existing methods for knowledge tracing in learning sciences are predominantly reliant on statistical data and instructor-defined knowledge components, making it challenging to integrate AI-generated educational content with traditional established methods. We propose a method for automatically extracting knowledge components from educational content using instruction-tuned large multimodal models. We validate this approach by comprehensively evaluating it against knowledge tracing benchmarks in five domains. Our results indicate that the automatically extracted knowledge components can effectively replace human-tagged labels, offering a promising direction for enhancing intelligent tutoring systems in limited-data scenarios, achieving more explainable assessments in educational settings, and laying the groundwork for automated assessment.
Addressing Negative Transfer in Diffusion Models
Jun 01, 2023



Diffusion-based generative models have achieved remarkable success in various domains. It trains a model on denoising tasks that encompass different noise levels simultaneously, representing a form of multi-task learning (MTL). However, analyzing and improving diffusion models from an MTL perspective remains under-explored. In particular, MTL can sometimes lead to the well-known phenomenon of $\textit{negative transfer}$, which results in the performance degradation of certain tasks due to conflicts between tasks. In this paper, we aim to analyze diffusion training from an MTL standpoint, presenting two key observations: $\textbf{(O1)}$ the task affinity between denoising tasks diminishes as the gap between noise levels widens, and $\textbf{(O2)}$ negative transfer can arise even in the context of diffusion training. Building upon these observations, our objective is to enhance diffusion training by mitigating negative transfer. To achieve this, we propose leveraging existing MTL methods, but the presence of a huge number of denoising tasks makes this computationally expensive to calculate the necessary per-task loss or gradient. To address this challenge, we propose clustering the denoising tasks into small task clusters and applying MTL methods to them. Specifically, based on $\textbf{(O2)}$, we employ interval clustering to enforce temporal proximity among denoising tasks within clusters. We show that interval clustering can be solved with dynamic programming and utilize signal-to-noise ratio, timestep, and task affinity for clustering objectives. Through this, our approach addresses the issue of negative transfer in diffusion models by allowing for efficient computation of MTL methods. We validate the proposed clustering and its integration with MTL methods through various experiments, demonstrating improved sample quality of diffusion models.
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023



Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.
Evaluation of Question Generation Needs More References
May 26, 2023Question generation (QG) is the task of generating a valid and fluent question based on a given context and the target answer. According to various purposes, even given the same context, instructors can ask questions about different concepts, and even the same concept can be written in different ways. However, the evaluation for QG usually depends on single reference-based similarity metrics, such as n-gram-based metric or learned metric, which is not sufficient to fully evaluate the potential of QG methods. To this end, we propose to paraphrase the reference question for a more robust QG evaluation. Using large language models such as GPT-3, we created semantically and syntactically diverse questions, then adopt the simple aggregation of the popular evaluation metrics as the final scores. Through our experiments, we found that using multiple (pseudo) references is more effective for QG evaluation while showing a higher correlation with human evaluations than evaluation with a single reference.
Towards Zero-Shot Functional Compositionality of Language Models
Mar 06, 2023Large Pre-trained Language Models (PLM) have become the most desirable starting point in the field of NLP, as they have become remarkably good at solving many individual tasks. Despite such success, in this paper, we argue that current paradigms of working with PLMs are neglecting a critical aspect of modeling human intelligence: functional compositionality. Functional compositionality - the ability to compose learned tasks - has been a long-standing challenge in the field of AI (and many other fields) as it is considered one of the hallmarks of human intelligence. An illustrative example of such is cross-lingual summarization, where a bilingual person (English-French) could directly summarize an English document into French sentences without having to translate the English document or summary into French explicitly. We discuss why this matter is an important open problem that requires further attention from the field. Then, we show that current PLMs (e.g., GPT-2 and T5) don't have functional compositionality yet and it is far from human-level generalizability. Finally, we suggest several research directions that could push the field towards zero-shot functional compositionality of language models.
Evaluating the Knowledge Dependency of Questions
Nov 21, 2022The automatic generation of Multiple Choice Questions (MCQ) has the potential to reduce the time educators spend on student assessment significantly. However, existing evaluation metrics for MCQ generation, such as BLEU, ROUGE, and METEOR, focus on the n-gram based similarity of the generated MCQ to the gold sample in the dataset and disregard their educational value. They fail to evaluate the MCQ's ability to assess the student's knowledge of the corresponding target fact. To tackle this issue, we propose a novel automatic evaluation metric, coined Knowledge Dependent Answerability (KDA), which measures the MCQ's answerability given knowledge of the target fact. Specifically, we first show how to measure KDA based on student responses from a human survey. Then, we propose two automatic evaluation metrics, KDA_disc and KDA_cont, that approximate KDA by leveraging pre-trained language models to imitate students' problem-solving behavior. Through our human studies, we show that KDA_disc and KDA_soft have strong correlations with both (1) KDA and (2) usability in an actual classroom setting, labeled by experts. Furthermore, when combined with n-gram based similarity metrics, KDA_disc and KDA_cont are shown to have a strong predictive power for various expert-labeled MCQ quality measures.
Dialogue Summaries as Dialogue States (DS2), Template-Guided Summarization for Few-shot Dialogue State Tracking
Mar 03, 2022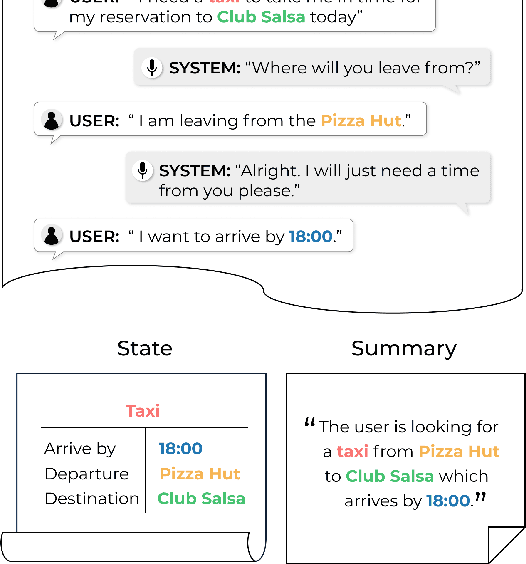
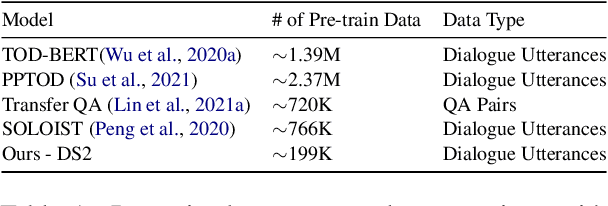
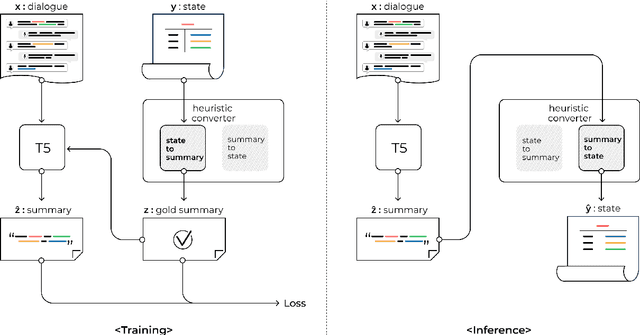
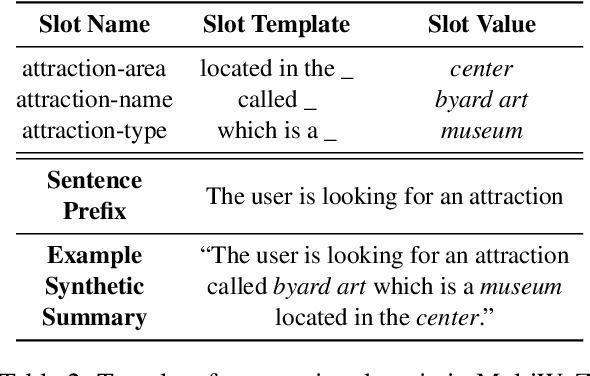
Annotating task-oriented dialogues is notorious for the expensive and difficult data collection process. Few-shot dialogue state tracking (DST) is a realistic solution to this problem. In this paper, we hypothesize that dialogue summaries are essentially unstructured dialogue states; hence, we propose to reformulate dialogue state tracking as a dialogue summarization problem. To elaborate, we train a text-to-text language model with synthetic template-based dialogue summaries, generated by a set of rules from the dialogue states. Then, the dialogue states can be recovered by inversely applying the summary generation rules. We empirically show that our method DS2 outperforms previous works on few-shot DST in MultiWoZ 2.0 and 2.1, in both cross-domain and multi-domain settings. Our method also exhibits vast speedup during both training and inference as it can generate all states at once. Finally, based on our analysis, we discover that the naturalness of the summary templates plays a key role for successful training.