 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Estimation for Random Graphs
Nov 09, 2021We study the problem of robustly estimating the parameter $p$ of an Erd\H{o}s-R\'enyi random graph on $n$ nodes, where a $\gamma$ fraction of nodes may be adversarially corrupted. After showing the deficiencies of canonical estimators, we design a computationally-efficient spectral algorithm which estimates $p$ up to accuracy $\tilde O(\sqrt{p(1-p)}/n + \gamma\sqrt{p(1-p)} /\sqrt{n}+ \gamma/n)$ for $\gamma < 1/60$. Furthermore, we give an inefficient algorithm with similar accuracy for all $\gamma <1/2$, the information-theoretic limit. Finally, we prove a nearly-matching statistical lower bound, showing that the error of our algorithms is optimal up to logarithmic factors.
HD-cos Networks: Efficient Neural Architectures for Secure Multi-Party Computation
Oct 28, 2021
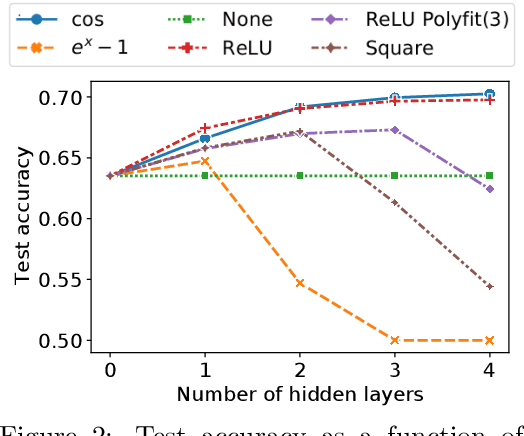
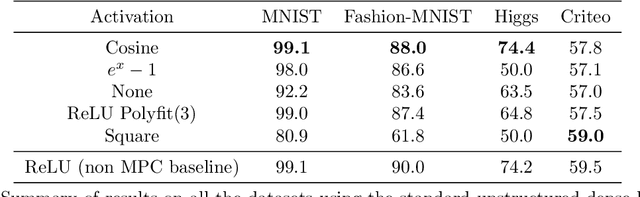

Multi-party computation (MPC) is a branch of cryptography where multiple non-colluding parties execute a well designed protocol to securely compute a function. With the non-colluding party assumption, MPC has a cryptographic guarantee that the parties will not learn sensitive information from the computation process, making it an appealing framework for applications that involve privacy-sensitive user data. In this paper, we study training and inference of neural networks under the MPC setup. This is challenging because the elementary operations of neural networks such as the ReLU activation function and matrix-vector multiplications are very expensive to compute due to the added multi-party communication overhead. To address this, we propose the HD-cos network that uses 1) cosine as activation function, 2) the Hadamard-Diagonal transformation to replace the unstructured linear transformations. We show that both of the approaches enjoy strong theoretical motivations and efficient computation under the MPC setup. We demonstrate on multiple public datasets that HD-cos matches the quality of the more expensive baselines.
FedJAX: Federated learning simulation with JAX
Aug 04, 2021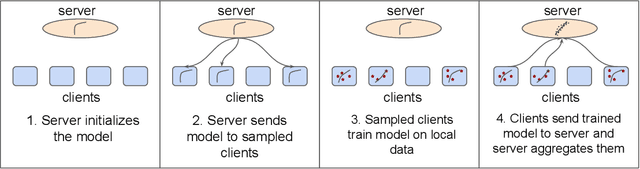


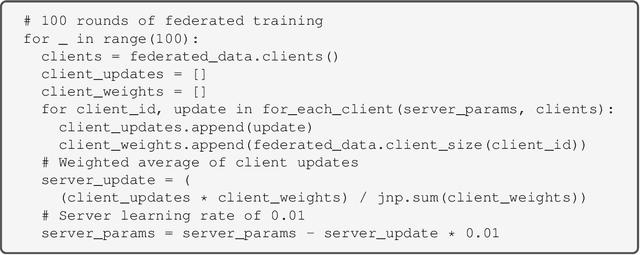
Federated learning is a machine learning technique that enables training across decentralized data. Recently, federated learning has become an active area of research due to the increased concerns over privacy and security. In light of this, a variety of open source federated learning libraries have been developed and released. We introduce FedJAX, a JAX-based open source library for federated learning simulations that emphasizes ease-of-use in research. With its simple primitives for implementing federated learning algorithms, prepackaged datasets, models and algorithms, and fast simulation speed, FedJAX aims to make developing and evaluating federated algorithms faster and easier for researchers. Our benchmark results show that FedJAX can be used to train models with federated averaging on the EMNIST dataset in a few minutes and the Stack Overflow dataset in roughly an hour with standard hyperparmeters using TPUs.
A Field Guide to Federated Optimization
Jul 14, 2021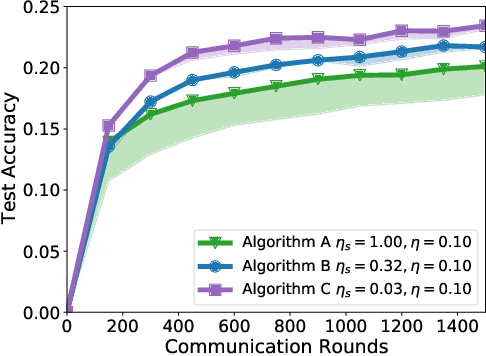


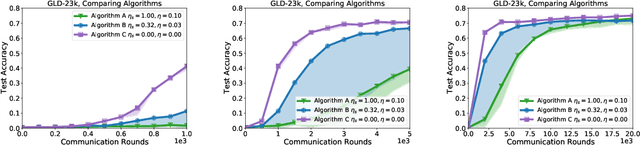
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
On the benefits of maximum likelihood estimation for Regression and Forecasting
Jun 18, 2021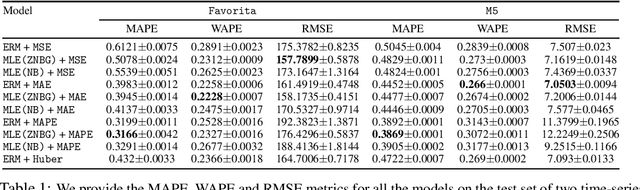
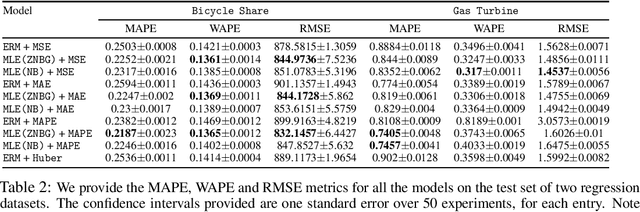
We advocate for a practical Maximum Likelihood Estimation (MLE) approach for regression and forecasting, as an alternative to the typical approach of Empirical Risk Minimization (ERM) for a specific target metric. This approach is better suited to capture inductive biases such as prior domain knowledge in datasets, and can output post-hoc estimators at inference time that can optimize different types of target metrics. We present theoretical results to demonstrate that our approach is always competitive with any estimator for the target metric under some general conditions, and in many practical settings (such as Poisson Regression) can actually be much superior to ERM. We demonstrate empirically that our method instantiated with a well-designed general purpose mixture likelihood family can obtain superior performance over ERM for a variety of tasks across time-series forecasting and regression datasets with different data distributions.
On the Renyi Differential Privacy of the Shuffle Model
May 11, 2021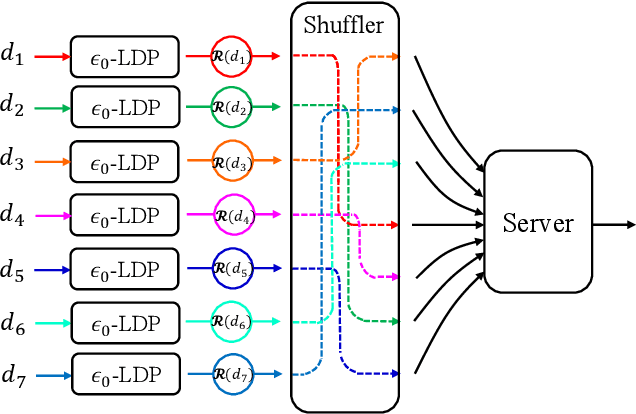
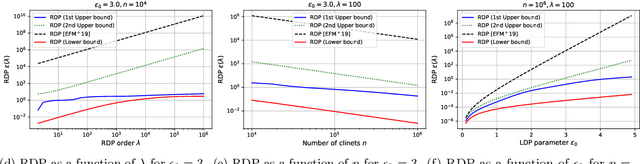
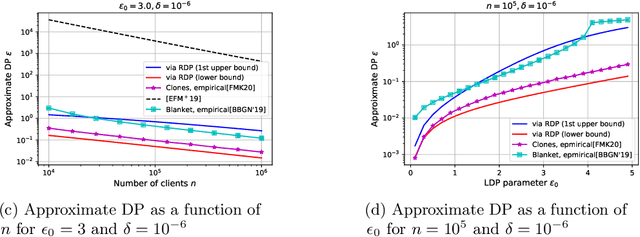
The central question studied in this paper is Renyi Differential Privacy (RDP) guarantees for general discrete local mechanisms in the shuffle privacy model. In the shuffle model, each of the $n$ clients randomizes its response using a local differentially private (LDP) mechanism and the untrusted server only receives a random permutation (shuffle) of the client responses without association to each client. The principal result in this paper is the first non-trivial RDP guarantee for general discrete local randomization mechanisms in the shuffled privacy model, and we develop new analysis techniques for deriving our results which could be of independent interest. In applications, such an RDP guarantee is most useful when we use it for composing several private interactions. We numerically demonstrate that, for important regimes, with composition our bound yields an improvement in privacy guarantee by a factor of $8\times$ over the state-of-the-art approximate Differential Privacy (DP) guarantee (with standard composition) for shuffled models. Moreover, combining with Poisson subsampling, our result leads to at least $10\times$ improvement over subsampled approximate DP with standard composition.
Communication-Efficient Agnostic Federated Averaging
Apr 06, 2021
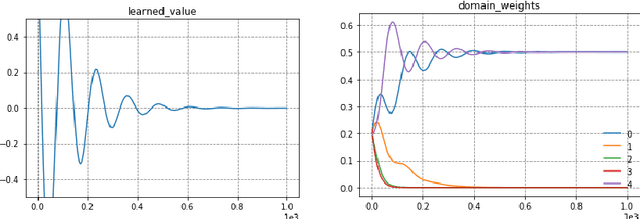
In distributed learning settings such as federated learning, the training algorithm can be potentially biased towards different clients. Mohri et al. (2019) proposed a domain-agnostic learning algorithm, where the model is optimized for any target distribution formed by a mixture of the client distributions in order to overcome this bias. They further proposed an algorithm for the cross-silo federated learning setting, where the number of clients is small. We consider this problem in the cross-device setting, where the number of clients is much larger. We propose a communication-efficient distributed algorithm called Agnostic Federated Averaging (or AgnosticFedAvg) to minimize the domain-agnostic objective proposed in Mohri et al. (2019), which is amenable to other private mechanisms such as secure aggregation. We highlight two types of naturally occurring domains in federated learning and argue that AgnosticFedAvg performs well on both. To demonstrate the practical effectiveness of AgnosticFedAvg, we report positive results for large-scale language modeling tasks in both simulation and live experiments, where the latter involves training language models for Spanish virtual keyboard for millions of user devices.
Remember What You Want to Forget: Algorithms for Machine Unlearning
Mar 04, 2021We study the problem of forgetting datapoints from a learnt model. In this case, the learner first receives a dataset $S$ drawn i.i.d. from an unknown distribution, and outputs a predictor $w$ that performs well on unseen samples from that distribution. However, at some point in the future, any training data point $z \in S$ can request to be unlearned, thus prompting the learner to modify its output predictor while still ensuring the same accuracy guarantees. In our work, we initiate a rigorous study of machine unlearning in the population setting, where the goal is to maintain performance on the unseen test loss. We then provide unlearning algorithms for convex loss functions. For the setting of convex losses, we provide an unlearning algorithm that can delete up to $O(n/d^{1/4})$ samples, where $d$ is the problem dimension. In comparison, in general, differentially private learningv(which implies unlearning) only guarantees deletion of $O(n/d^{1/2})$ samples. This shows that unlearning is at least polynomially more efficient than learning privately in terms of dependence on $d$ in the deletion capacity.
Learning with User-Level Privacy
Mar 02, 2021We propose and analyze algorithms to solve a range of learning tasks under user-level differential privacy constraints. Rather than guaranteeing only the privacy of individual samples, user-level DP protects a user's entire contribution ($m \ge 1$ samples), providing more stringent but more realistic protection against information leaks. We show that for high-dimensional mean estimation, empirical risk minimization with smooth losses, stochastic convex optimization, and learning hypothesis class with finite metric entropy, the privacy cost decreases as $O(1/\sqrt{m})$ as users provide more samples. In contrast, when increasing the number of users $n$, the privacy cost decreases at a faster $O(1/n)$ rate. We complement these results with lower bounds showing the worst-case optimality of our algorithm for mean estimation and stochastic convex optimization. Our algorithms rely on novel techniques for private mean estimation in arbitrary dimension with error scaling as the concentration radius $\tau$ of the distribution rather than the entire range. Under uniform convergence, we derive an algorithm that privately answers a sequence of $K$ adaptively chosen queries with privacy cost proportional to $\tau$, and apply it to solve the learning tasks we consider.
Wyner-Ziv Estimators: Efficient Distributed Mean Estimation with Side Information
Nov 24, 2020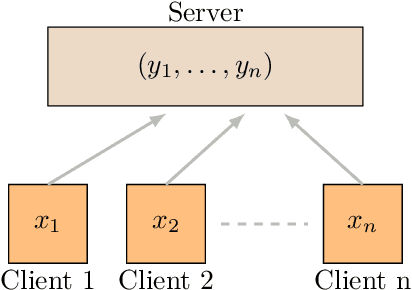
Communication efficient distributed mean estimation is an important primitive that arises in many distributed learning and optimization scenarios such as federated learning. Without any probabilistic assumptions on the underlying data, we study the problem of distributed mean estimation where the server has access to side information. We propose \emph{Wyner-Ziv estimators}, which are communication and computationally efficient and near-optimal when an upper bound for the distance between the side information and the data is known. As a corollary, we also show that our algorithms provide efficient schemes for the classic Wyner-Ziv problem in information theory. In a different direction, when there is no knowledge assumed about the distance between side information and the data, we present an alternative Wyner-Ziv estimator that uses correlated sampling. This latter setting offers {\em universal recovery guarantees}, and perhaps will be of interest in practice when the number of users is large and keeping track of the distances between the data and the side information may not be possible.