 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation
Nov 13, 2023



We present MM-Navigator, a GPT-4V-based agent for the smartphone graphical user interface (GUI) navigation task. MM-Navigator can interact with a smartphone screen as human users, and determine subsequent actions to fulfill given instructions. Our findings demonstrate that large multimodal models (LMMs), specifically GPT-4V, excel in zero-shot GUI navigation through its advanced screen interpretation, action reasoning, and precise action localization capabilities. We first benchmark MM-Navigator on our collected iOS screen dataset. According to human assessments, the system exhibited a 91\% accuracy rate in generating reasonable action descriptions and a 75\% accuracy rate in executing the correct actions for single-step instructions on iOS. Additionally, we evaluate the model on a subset of an Android screen navigation dataset, where the model outperforms previous GUI navigators in a zero-shot fashion. Our benchmark and detailed analyses aim to lay a robust groundwork for future research into the GUI navigation task. The project page is at https://github.com/zzxslp/MM-Navigator.
GPT-4V as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
MedEval: A Multi-Level, Multi-Task, and Multi-Domain Medical Benchmark for Language Model Evaluation
Oct 27, 2023



Curated datasets for healthcare are often limited due to the need of human annotations from experts. In this paper, we present MedEval, a multi-level, multi-task, and multi-domain medical benchmark to facilitate the development of language models for healthcare. MedEval is comprehensive and consists of data from several healthcare systems and spans 35 human body regions from 8 examination modalities. With 22,779 collected sentences and 21,228 reports, we provide expert annotations at multiple levels, offering a granular potential usage of the data and supporting a wide range of tasks. Moreover, we systematically evaluated 10 generic and domain-specific language models under zero-shot and finetuning settings, from domain-adapted baselines in healthcare to general-purposed state-of-the-art large language models (e.g., ChatGPT). Our evaluations reveal varying effectiveness of the two categories of language models across different tasks, from which we notice the importance of instruction tuning for few-shot usage of large language models. Our investigation paves the way toward benchmarking language models for healthcare and provides valuable insights into the strengths and limitations of adopting large language models in medical domains, informing their practical applications and future advancements.
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving
Oct 26, 2023Concept bottleneck models have been successfully used for explainable machine learning by encoding information within the model with a set of human-defined concepts. In the context of human-assisted or autonomous driving, explainability models can help user acceptance and understanding of decisions made by the autonomous vehicle, which can be used to rationalize and explain driver or vehicle behavior. We propose a new approach using concept bottlenecks as visual features for control command predictions and explanations of user and vehicle behavior. We learn a human-understandable concept layer that we use to explain sequential driving scenes while learning vehicle control commands. This approach can then be used to determine whether a change in a preferred gap or steering commands from a human (or autonomous vehicle) is led by an external stimulus or change in preferences. We achieve competitive performance to latent visual features while gaining interpretability within our model setup.
Robust and Interpretable Medical Image Classifiers via Concept Bottleneck Models
Oct 04, 2023



Medical image classification is a critical problem for healthcare, with the potential to alleviate the workload of doctors and facilitate diagnoses of patients. However, two challenges arise when deploying deep learning models to real-world healthcare applications. First, neural models tend to learn spurious correlations instead of desired features, which could fall short when generalizing to new domains (e.g., patients with different ages). Second, these black-box models lack interpretability. When making diagnostic predictions, it is important to understand why a model makes a decision for trustworthy and safety considerations. In this paper, to address these two limitations, we propose a new paradigm to build robust and interpretable medical image classifiers with natural language concepts. Specifically, we first query clinical concepts from GPT-4, then transform latent image features into explicit concepts with a vision-language model. We systematically evaluate our method on eight medical image classification datasets to verify its effectiveness. On challenging datasets with strong confounding factors, our method can mitigate spurious correlations thus substantially outperform standard visual encoders and other baselines. Finally, we show how classification with a small number of concepts brings a level of interpretability for understanding model decisions through case studies in real medical data.
Learning Concise and Descriptive Attributes for Visual Recognition
Aug 07, 2023



Recent advances in foundation models present new opportunities for interpretable visual recognition -- one can first query Large Language Models (LLMs) to obtain a set of attributes that describe each class, then apply vision-language models to classify images via these attributes. Pioneering work shows that querying thousands of attributes can achieve performance competitive with image features. However, our further investigation on 8 datasets reveals that LLM-generated attributes in a large quantity perform almost the same as random words. This surprising finding suggests that significant noise may be present in these attributes. We hypothesize that there exist subsets of attributes that can maintain the classification performance with much smaller sizes, and propose a novel learning-to-search method to discover those concise sets of attributes. As a result, on the CUB dataset, our method achieves performance close to that of massive LLM-generated attributes (e.g., 10k attributes for CUB), yet using only 32 attributes in total to distinguish 200 bird species. Furthermore, our new paradigm demonstrates several additional benefits: higher interpretability and interactivity for humans, and the ability to summarize knowledge for a recognition task.
Comparing Apples to Apples: Generating Aspect-Aware Comparative Sentences from User Reviews
Jul 23, 2023


It is time-consuming to find the best product among many similar alternatives. Comparative sentences can help to contrast one item from others in a way that highlights important features of an item that stand out. Given reviews of one or multiple items and relevant item features, we generate comparative review sentences to aid users to find the best fit. Specifically, our model consists of three successive components in a transformer: (i) an item encoding module to encode an item for comparison, (ii) a comparison generation module that generates comparative sentences in an autoregressive manner, (iii) a novel decoding method for user personalization. We show that our pipeline generates fluent and diverse comparative sentences. We run experiments on the relevance and fidelity of our generated sentences in a human evaluation study and find that our algorithm creates comparative review sentences that are relevant and truthful.
"Nothing Abnormal": Disambiguating Medical Reports via Contrastive Knowledge Infusion
May 15, 2023Sharing medical reports is essential for patient-centered care. A recent line of work has focused on automatically generating reports with NLP methods. However, different audiences have different purposes when writing/reading medical reports -- for example, healthcare professionals care more about pathology, whereas patients are more concerned with the diagnosis ("Is there any abnormality?"). The expectation gap results in a common situation where patients find their medical reports to be ambiguous and therefore unsure about the next steps. In this work, we explore the audience expectation gap in healthcare and summarize common ambiguities that lead patients to be confused about their diagnosis into three categories: medical jargon, contradictory findings, and misleading grammatical errors. Based on our analysis, we define a disambiguation rewriting task to regenerate an input to be unambiguous while preserving information about the original content. We further propose a rewriting algorithm based on contrastive pretraining and perturbation-based rewriting. In addition, we create two datasets, OpenI-Annotated based on chest reports and VA-Annotated based on general medical reports, with available binary labels for ambiguity and abnormality presence annotated by radiology specialists. Experimental results on these datasets show that our proposed algorithm effectively rewrites input sentences in a less ambiguous way with high content fidelity. Our code and annotated data are released to facilitate future research.
CLIP also Understands Text: Prompting CLIP for Phrase Understanding
Oct 11, 2022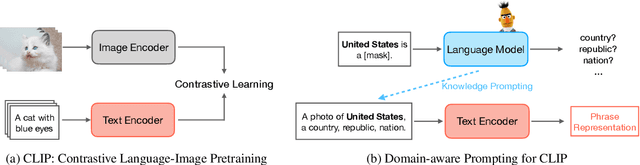
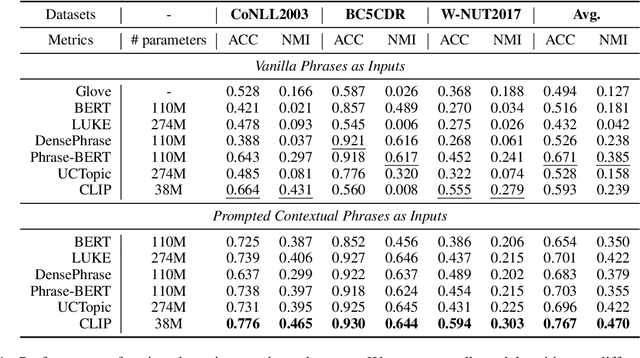
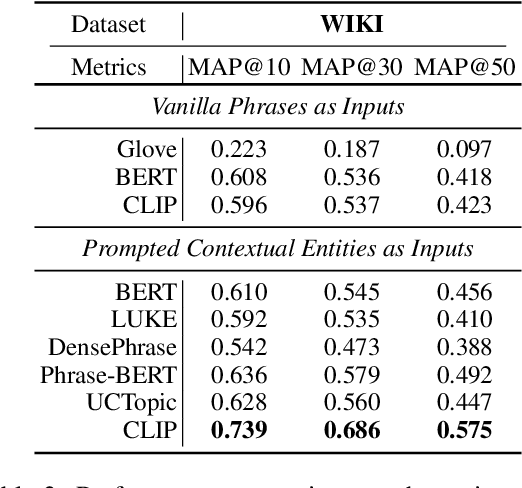
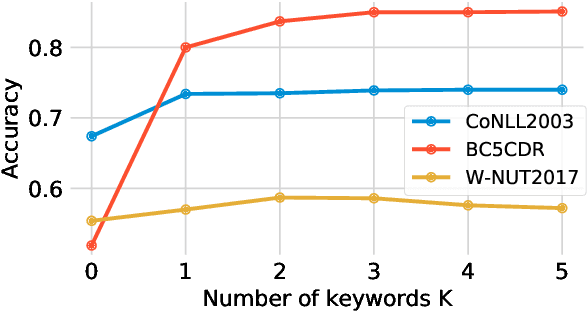
Contrastive Language-Image Pretraining (CLIP) efficiently learns visual concepts by pre-training with natural language supervision. CLIP and its visual encoder have been explored on various vision and language tasks and achieve strong zero-shot or transfer learning performance. However, the application of its text encoder solely for text understanding has been less explored. In this paper, we find that the text encoder of CLIP actually demonstrates strong ability for phrase understanding, and can even significantly outperform popular language models such as BERT with a properly designed prompt. Extensive experiments validate the effectiveness of our method across different datasets and domains on entity clustering and entity set expansion tasks.
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation
Oct 07, 2022
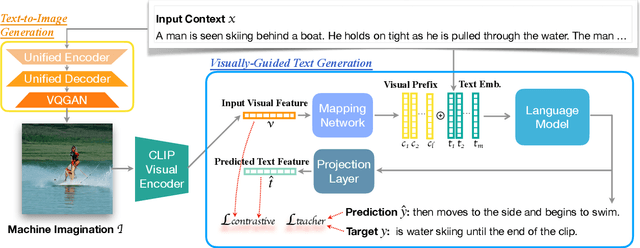
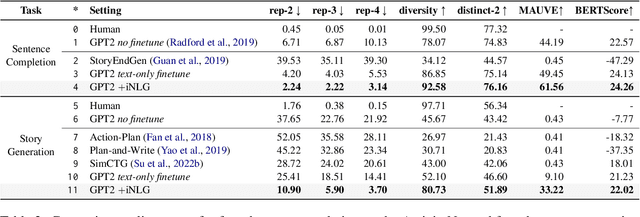
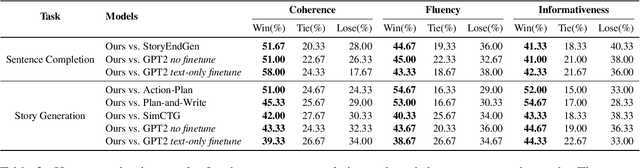
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.