 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Vision-Language Navigation
Paper and Code
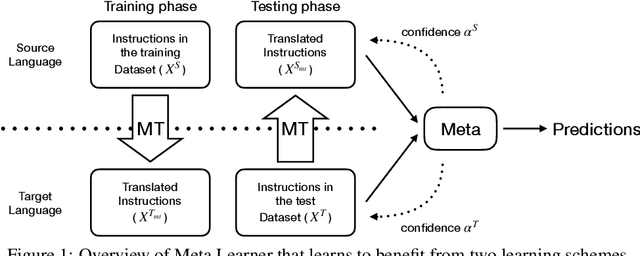
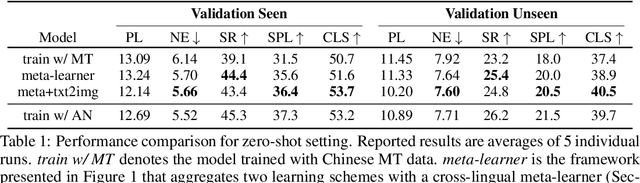
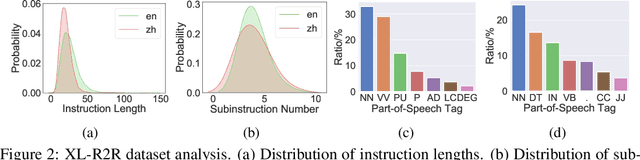
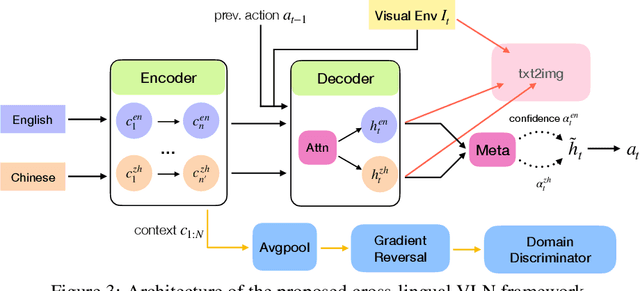
Vision-Language Navigation (VLN) is the task where an agent is commanded to navigate in photo-realistic environments with natural language instructions. Previous research on VLN is primarily conducted on the Room-to-Room (R2R) dataset with only English instructions. The ultimate goal of VLN, however, is to serve people speaking arbitrary languages. To do this, we collect a cross-lingual R2R dataset, extending the original benchmark with corresponding Chinese instructions. But it is impractical to collect human-annotated instructions for every existing language. Based on the newly introduced dataset, we propose a general cross-lingual VLN framework to enable instruction-following navigation for different languages. We first explore the possibility of building a cross-lingual agent when no training data of the target language is available. The cross-lingual agent is equipped with a meta-learner to aggregate cross-lingual representations and with a visually grounded cross-lingual alignment module to align textual representations of different languages. Under the zero-shot learning scenario, our model shows competitive results even compared to a model trained with all target language instructions. Besides, we introduce an adversarial domain adaption loss to improve the transferring ability of our model when given a certain amount of target language data. Our dataset and methods demonstrate potentials of building scalable cross-lingual agents to serve speakers with different languages.