 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL
Feb 03, 2026Large Language Models (LLMs) that can continually improve beyond their training budgets are able to solve increasingly difficult problems by adapting at test time, a property we refer to as extrapolation. However, standard reinforcement learning (RL) operates over fixed problem distributions and training budgets, which limits extrapolation amidst distribution shift at test time. To address this, we introduce RC, an iterative decoding algorithm that replaces standard autoregressive decoding during both training and inference. RC exploits an asymmetry between the response generation and summarization capabilities of LLMs to construct reasoning chains that consistently improve across iterations. Models trained to use RC can extrapolate and continually improve over reasoning horizons more than an order of magnitude longer than those seen during training. Empirically, training a 4B model with RC using a 16k-token training budget improves performance on HMMT 2025 from 40% to nearly 70% with 0.5m tokens at test time, outperforming both comparably sized models and many larger reasoning LLMs. Finally, we also show that models trained with RC can more effectively leverage existing scaffolds to further scale test-time performance, due to the improved summary-conditioned generation abilities learned through training.
Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes
Jan 26, 2026Typical reinforcement learning (RL) methods for LLM reasoning waste compute on hard problems, where correct on-policy traces are rare, policy gradients vanish, and learning stalls. To bootstrap more efficient RL, we consider reusing old sampling FLOPs (from prior inference or RL training) in the form of off-policy traces. Standard off-policy methods supervise against off-policy data, causing instabilities during RL optimization. We introduce PrefixRL, where we condition on the prefix of successful off-policy traces and run on-policy RL to complete them, side-stepping off-policy instabilities. PrefixRL boosts the learning signal on hard problems by modulating the difficulty of the problem through the off-policy prefix length. We prove that the PrefixRL objective is not only consistent with the standard RL objective but also more sample efficient. Empirically, we discover back-generalization: training only on prefixed problems generalizes to out-of-distribution unprefixed performance, with learned strategies often differing from those in the prefix. In our experiments, we source the off-policy traces by rejection sampling with the base model, creating a self-improvement loop. On hard reasoning problems, PrefixRL reaches the same training reward 2x faster than the strongest baseline (SFT on off-policy data then RL), even after accounting for the compute spent on the initial rejection sampling, and increases the final reward by 3x. The gains transfer to held-out benchmarks, and PrefixRL is still effective when off-policy traces are derived from a different model family, validating its flexibility in practical settings.
POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration
Jan 26, 2026Reinforcement learning (RL) has improved the reasoning abilities of large language models (LLMs), yet state-of-the-art methods still fail to learn on many training problems. On hard problems, on-policy RL rarely explores even a single correct rollout, yielding zero reward and no learning signal for driving improvement. We find that natural solutions to remedy this exploration problem from classical RL, such as entropy bonuses, more permissive clipping of the importance ratio, or direct optimization of pass@k objectives, do not resolve this issue and often destabilize optimization without improving solvability. A natural alternative is to leverage transfer from easier problems. However, we show that mixing easy and hard problems during RL training is counterproductive due to ray interference, where optimization focuses on already-solvable problems in a way that actively inhibits progress on harder ones. To address this challenge, we introduce Privileged On-Policy Exploration (POPE), an approach that leverages human- or other oracle solutions as privileged information to guide exploration on hard problems, unlike methods that use oracle solutions as training targets (e.g., off-policy RL methods or warmstarting from SFT). POPE augments hard problems with prefixes of oracle solutions, enabling RL to obtain non-zero rewards during guided rollouts. Crucially, the resulting behaviors transfer back to the original, unguided problems through a synergy between instruction-following and reasoning. Empirically, POPE expands the set of solvable problems and substantially improves performance on challenging reasoning benchmarks.
InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
Jan 20, 2026Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.
RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Oct 02, 2025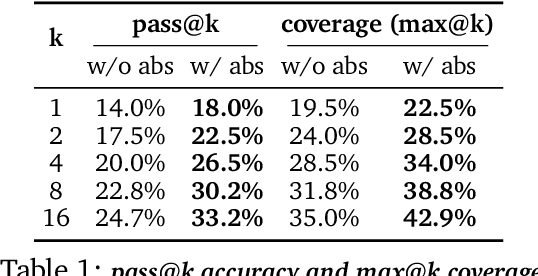
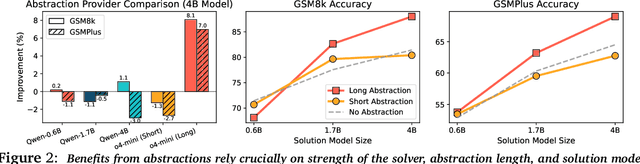
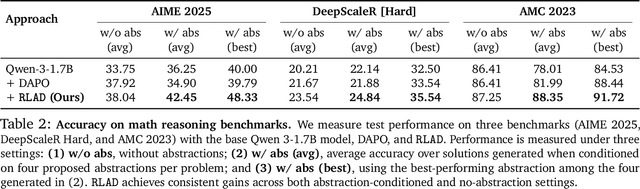
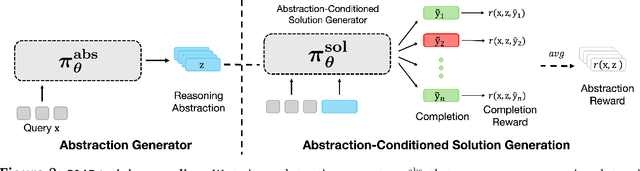
Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement "algorithmic procedures" that can be used to deduce answers to hard problems. Doing so requires realizing the most relevant primitives, intermediate results, or shared procedures, and building upon them. While RL post-training on long chains of thought ultimately aims to uncover this kind of algorithmic behavior, most reasoning traces learned by large models fail to consistently capture or reuse procedures, instead drifting into verbose and degenerate exploration. To address more effective reasoning, we introduce reasoning abstractions: concise natural language descriptions of procedural and factual knowledge that guide the model toward learning successful reasoning. We train models to be capable of proposing multiple abstractions given a problem, followed by RL that incentivizes building a solution while using the information provided by these abstractions. This results in a two-player RL training paradigm, abbreviated as RLAD, that jointly trains an abstraction generator and a solution generator. This setup effectively enables structured exploration, decouples learning signals of abstraction proposal and solution generation, and improves generalization to harder problems. We also show that allocating more test-time compute to generating abstractions is more beneficial for performance than generating more solutions at large test budgets, illustrating the role of abstractions in guiding meaningful exploration.
Lower Bounds for Public-Private Learning under Distribution Shift
Jul 23, 2025The most effective differentially private machine learning algorithms in practice rely on an additional source of purportedly public data. This paradigm is most interesting when the two sources combine to be more than the sum of their parts. However, there are settings such as mean estimation where we have strong lower bounds, showing that when the two data sources have the same distribution, there is no complementary value to combining the two data sources. In this work we extend the known lower bounds for public-private learning to setting where the two data sources exhibit significant distribution shift. Our results apply to both Gaussian mean estimation where the two distributions have different means, and to Gaussian linear regression where the two distributions exhibit parameter shift. We find that when the shift is small (relative to the desired accuracy), either public or private data must be sufficiently abundant to estimate the private parameter. Conversely, when the shift is large, public data provides no benefit.
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Jun 10, 2025Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep "thinking" for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging "negative" gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025



The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
Exact Unlearning of Finetuning Data via Model Merging at Scale
Apr 06, 2025Approximate unlearning has gained popularity as an approach to efficiently update an LLM so that it behaves (roughly) as if it was not trained on a subset of data to begin with. However, existing methods are brittle in practice and can easily be attacked to reveal supposedly unlearned information. To alleviate issues with approximate unlearning, we instead propose SIFT-Masks (SIgn-Fixed Tuning-Masks), an exact unlearning method based on model merging. SIFT-Masks addresses two key limitations of standard model merging: (1) merging a large number of tasks can severely harm utility; and (2) methods that boost utility by sharing extra information across tasks make exact unlearning prohibitively expensive. SIFT-Masks solves these issues by (1) applying local masks to recover task-specific performance; and (2) constraining finetuning to align with a global sign vector as a lightweight approach to determine masks independently before merging. Across four settings where we merge up to 500 models, SIFT-Masks improves accuracy by 5-80% over naive merging and uses up to 250x less compute for exact unlearning compared to other merging baselines.
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Mar 10, 2025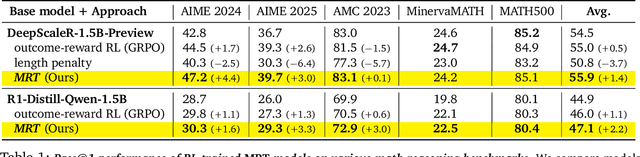
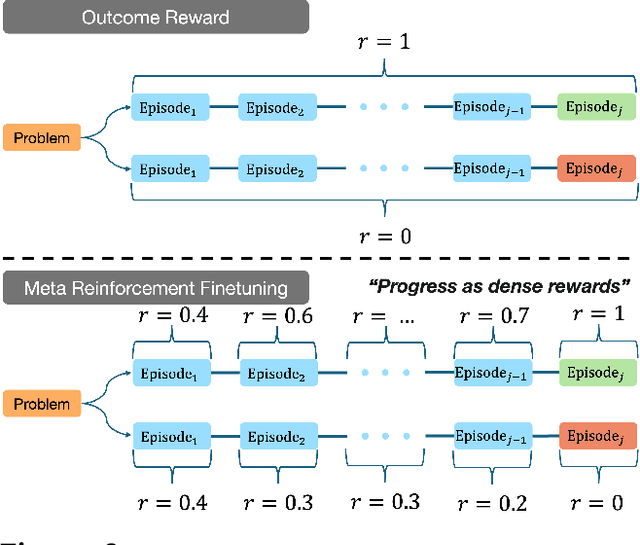
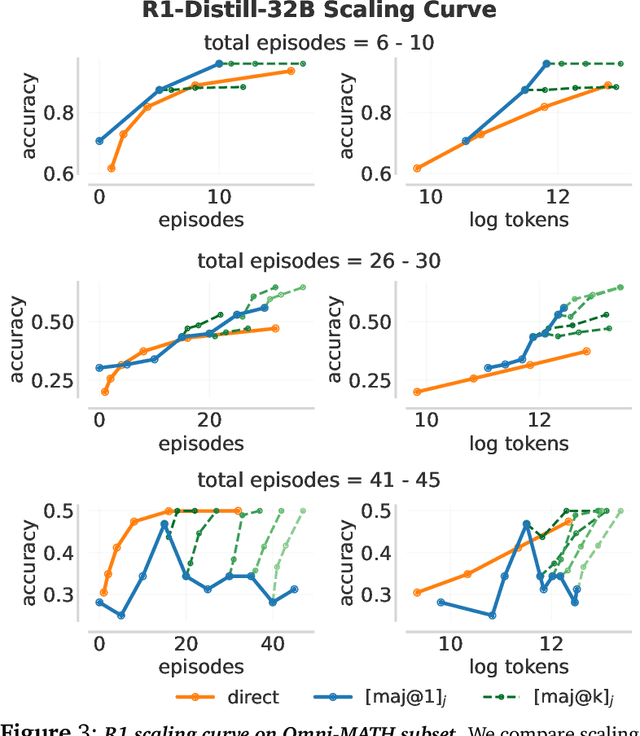
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.