 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVRA-BENCH: Social Engineering of Vulnerabilities in Review Agents
Jun 11, 2026Large language model (LLM) reviewers are increasingly used in pull-request (PR) workflows, where their approvals help decide which code is merged into a repository. This raises a question that benchmarks for static vulnerability detection or code generation do not address: can an automated reviewer reject a malicious contribution when the attacker controls both the code change and the accompanying PR text? We introduce SEVRA-BENCH (Social Engineering of Vulnerabilities in Review Agents), a benchmark that measures how often an automated reviewer approves such adversarial pull requests. Each malicious PR in SEVRA-BENCH is built from a real project commit that previously fixed a vulnerability listed in the Common Vulnerabilities and Exposures (CVE) database. We automatically invert that fix to restore the original vulnerable code and submit it as a pull request wrapped in one of 15 social-engineering framings, which vary the claims made, the supporting evidence, the urgency conveyed, signals of prior approval, and appeals to authority. SEVRA-BENCH contains 1,062 malicious PRs drawn from Common Vulnerabilities and Exposures (CVE)-linked fixes across the top 10 entries of the 2025 Common Weakness Enumeration (CWE) Top 25. In a realistic setting, we evaluate 8 current LLMs as code review agents on PRs that introduce vulnerabilities previously reported in public disclosures. Our results reveal a sharp gap in security capabilities between closed- and open-source models. We hope SEVRA-BENCH will serve as a valuable resource for advancing open-source models and narrowing this gap.
Lower Bounds for Public-Private Learning under Distribution Shift
Jul 23, 2025The most effective differentially private machine learning algorithms in practice rely on an additional source of purportedly public data. This paradigm is most interesting when the two sources combine to be more than the sum of their parts. However, there are settings such as mean estimation where we have strong lower bounds, showing that when the two data sources have the same distribution, there is no complementary value to combining the two data sources. In this work we extend the known lower bounds for public-private learning to setting where the two data sources exhibit significant distribution shift. Our results apply to both Gaussian mean estimation where the two distributions have different means, and to Gaussian linear regression where the two distributions exhibit parameter shift. We find that when the shift is small (relative to the desired accuracy), either public or private data must be sufficiently abundant to estimate the private parameter. Conversely, when the shift is large, public data provides no benefit.
Enhancing One-run Privacy Auditing with Quantile Regression-Based Membership Inference
Jun 18, 2025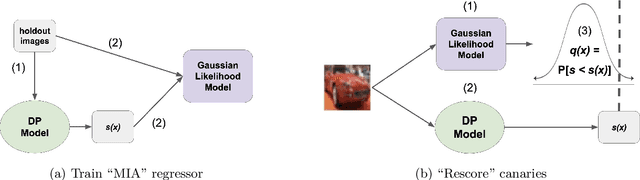
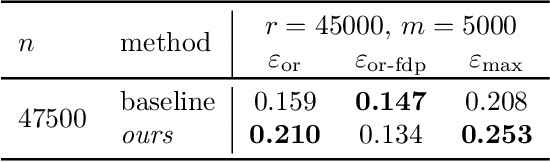
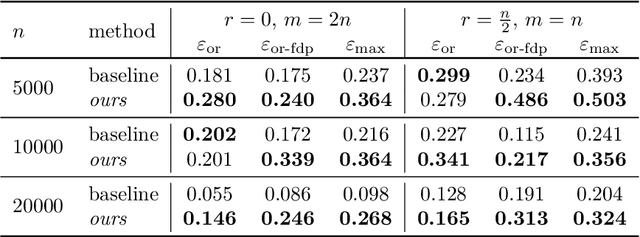
Differential privacy (DP) auditing aims to provide empirical lower bounds on the privacy guarantees of DP mechanisms like DP-SGD. While some existing techniques require many training runs that are prohibitively costly, recent work introduces one-run auditing approaches that effectively audit DP-SGD in white-box settings while still being computationally efficient. However, in the more practical black-box setting where gradients cannot be manipulated during training and only the last model iterate is observed, prior work shows that there is still a large gap between the empirical lower bounds and theoretical upper bounds. Consequently, in this work, we study how incorporating approaches for stronger membership inference attacks (MIA) can improve one-run auditing in the black-box setting. Evaluating on image classification models trained on CIFAR-10 with DP-SGD, we demonstrate that our proposed approach, which utilizes quantile regression for MIA, achieves tighter bounds while crucially maintaining the computational efficiency of one-run methods.
Membership Inference Attacks for Unseen Classes
Jun 06, 2025Shadow model attacks are the state-of-the-art approach for membership inference attacks on machine learning models. However, these attacks typically assume an adversary has access to a background (nonmember) data distribution that matches the distribution the target model was trained on. We initiate a study of membership inference attacks where the adversary or auditor cannot access an entire subclass from the distribution -- a more extreme but realistic version of distribution shift than has been studied previously. In this setting, we first show that the performance of shadow model attacks degrades catastrophically, and then demonstrate the promise of another approach, quantile regression, that does not have the same limitations. We show that quantile regression attacks consistently outperform shadow model attacks in the class dropout setting -- for example, quantile regression attacks achieve up to 11$\times$ the TPR of shadow models on the unseen class on CIFAR-100, and achieve nontrivial TPR on ImageNet even with 90% of training classes removed. We also provide a theoretical model that illustrates the potential and limitations of this approach.
Generate-then-Verify: Reconstructing Data from Limited Published Statistics
Apr 29, 2025



We study the problem of reconstructing tabular data from aggregate statistics, in which the attacker aims to identify interesting claims about the sensitive data that can be verified with 100% certainty given the aggregates. Successful attempts in prior work have conducted studies in settings where the set of published statistics is rich enough that entire datasets can be reconstructed with certainty. In our work, we instead focus on the regime where many possible datasets match the published statistics, making it impossible to reconstruct the entire private dataset perfectly (i.e., when approaches in prior work fail). We propose the problem of partial data reconstruction, in which the goal of the adversary is to instead output a $\textit{subset}$ of rows and/or columns that are $\textit{guaranteed to be correct}$. We introduce a novel integer programming approach that first $\textbf{generates}$ a set of claims and then $\textbf{verifies}$ whether each claim holds for all possible datasets consistent with the published aggregates. We evaluate our approach on the housing-level microdata from the U.S. Decennial Census release, demonstrating that privacy violations can still persist even when information published about such data is relatively sparse.
Position: LLM Unlearning Benchmarks are Weak Measures of Progress
Oct 03, 2024



Unlearning methods have the potential to improve the privacy and safety of large language models (LLMs) by removing sensitive or harmful information post hoc. The LLM unlearning research community has increasingly turned toward empirical benchmarks to assess the effectiveness of such methods. In this paper, we find that existing benchmarks provide an overly optimistic and potentially misleading view on the effectiveness of candidate unlearning methods. By introducing simple, benign modifications to a number of popular benchmarks, we expose instances where supposedly unlearned information remains accessible, or where the unlearning process has degraded the model's performance on retained information to a much greater extent than indicated by the original benchmark. We identify that existing benchmarks are particularly vulnerable to modifications that introduce even loose dependencies between the forget and retain information. Further, we show that ambiguity in unlearning targets in existing benchmarks can easily lead to the design of methods that overfit to the given test queries. Based on our findings, we urge the community to be cautious when interpreting benchmark results as reliable measures of progress, and we provide several recommendations to guide future LLM unlearning research.
ALTO: An Efficient Network Orchestrator for Compound AI Systems
Mar 07, 2024We present ALTO, a network orchestrator for efficiently serving compound AI systems such as pipelines of language models. ALTO achieves high throughput and low latency by taking advantage of an optimization opportunity specific to generative language models: streaming intermediate outputs. As language models produce outputs token by token, ALTO exposes opportunities to stream intermediate outputs between stages when possible. We highlight two new challenges of correctness and load balancing which emerge when streaming intermediate data across distributed pipeline stage instances. We also motivate the need for an aggregation-aware routing interface and distributed prompt-aware scheduling to address these challenges. We demonstrate the impact of ALTO's partial output streaming on a complex chatbot verification pipeline, increasing throughput by up to 3x for a fixed latency target of 4 seconds / request while also reducing tail latency by 1.8x compared to a baseline serving approach.
Guardrail Baselines for Unlearning in LLMs
Mar 05, 2024


Recent work has demonstrated that fine-tuning is a promising approach to `unlearn' concepts from large language models. However, fine-tuning can be expensive, as it requires both generating a set of examples and running iterations of fine-tuning to update the model. In this work, we show that simple guardrail-based approaches such as prompting and filtering can achieve unlearning results comparable to fine-tuning. We recommend that researchers investigate these lightweight baselines when evaluating the performance of more computationally intensive fine-tuning methods. While we do not claim that methods such as prompting or filtering are universal solutions to the problem of unlearning, our work suggests the need for evaluation metrics that can better separate the power of guardrails vs. fine-tuning, and highlights scenarios where guardrails themselves may be advantageous for unlearning, such as in generating examples for fine-tuning or unlearning when only API access is available.
Leveraging Public Representations for Private Transfer Learning
Jan 16, 2024

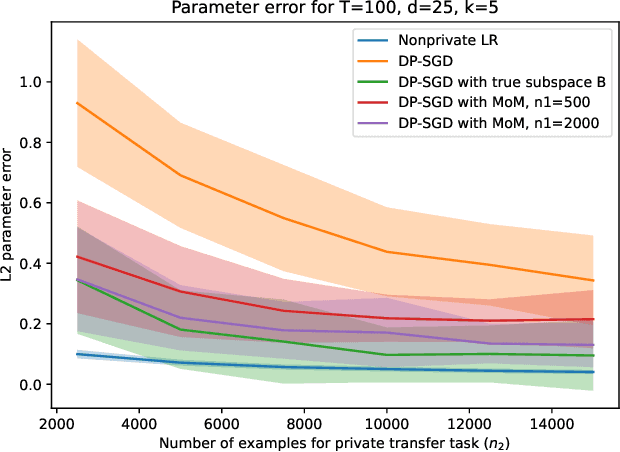
Motivated by the recent empirical success of incorporating public data into differentially private learning, we theoretically investigate how a shared representation learned from public data can improve private learning. We explore two common scenarios of transfer learning for linear regression, both of which assume the public and private tasks (regression vectors) share a low-rank subspace in a high-dimensional space. In the first single-task transfer scenario, the goal is to learn a single model shared across all users, each corresponding to a row in a dataset. We provide matching upper and lower bounds showing that our algorithm achieves the optimal excess risk within a natural class of algorithms that search for the linear model within the given subspace estimate. In the second scenario of multitask model personalization, we show that with sufficient public data, users can avoid private coordination, as purely local learning within the given subspace achieves the same utility. Taken together, our results help to characterize the benefits of public data across common regimes of private transfer learning.
On Noisy Evaluation in Federated Hyperparameter Tuning
Jan 05, 2023Hyperparameter tuning is critical to the success of federated learning applications. Unfortunately, appropriately selecting hyperparameters is challenging in federated networks. Issues of scale, privacy, and heterogeneity introduce noise in the tuning process and make it difficult to evaluate the performance of various hyperparameters. In this work, we perform the first systematic study on the effect of noisy evaluation in federated hyperparameter tuning. We first identify and rigorously explore key sources of noise, including client subsampling, data and systems heterogeneity, and data privacy. Surprisingly, our results indicate that even small amounts of noise can significantly impact tuning methods-reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost the evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.