 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Preprocessing on Arabic-English Statistical and Neural Machine Translation
Jun 27, 2019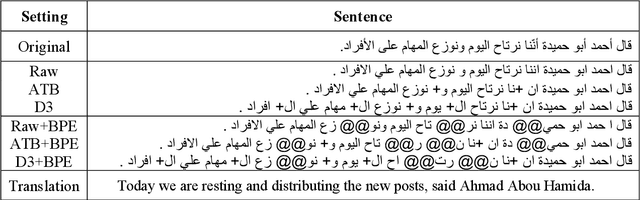
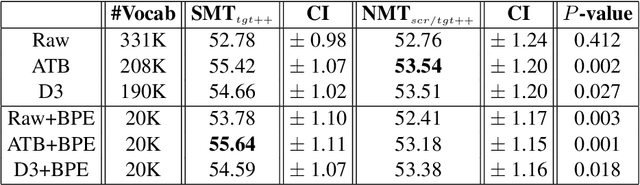
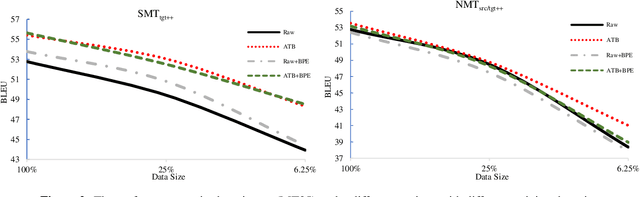

Neural networks have become the state-of-the-art approach for machine translation (MT) in many languages. While linguistically-motivated tokenization techniques were shown to have significant effects on the performance of statistical MT, it remains unclear if those techniques are well suited for neural MT. In this paper, we systematically compare neural and statistical MT models for Arabic-English translation on data preprecossed by various prominent tokenization schemes. Furthermore, we consider a range of data and vocabulary sizes and compare their effect on both approaches. Our empirical results show that the best choice of tokenization scheme is largely based on the type of model and the size of data. We also show that we can gain significant improvements using a system selection that combines the output from neural and statistical MT.
Adversarial Computation of Optimal Transport Maps
Jun 24, 2019
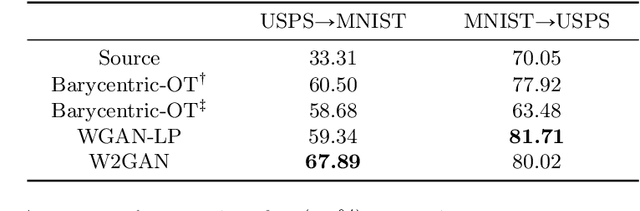
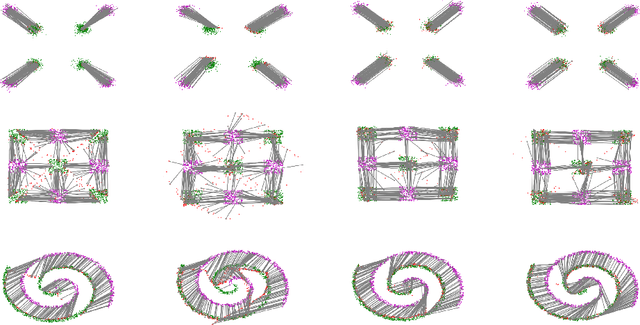
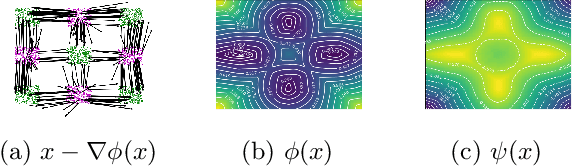
Computing optimal transport maps between high-dimensional and continuous distributions is a challenging problem in optimal transport (OT). Generative adversarial networks (GANs) are powerful generative models which have been successfully applied to learn maps across high-dimensional domains. However, little is known about the nature of the map learned with a GAN objective. To address this problem, we propose a generative adversarial model in which the discriminator's objective is the $2$-Wasserstein metric. We show that during training, our generator follows the $W_2$-geodesic between the initial and the target distributions. As a consequence, it reproduces an optimal map at the end of training. We validate our approach empirically in both low-dimensional and high-dimensional continuous settings, and show that it outperforms prior methods on image data.
A Closer Look at the Optimization Landscapes of Generative Adversarial Networks
Jun 11, 2019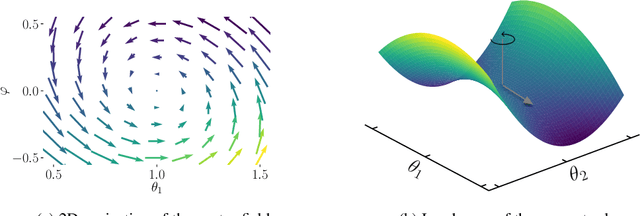
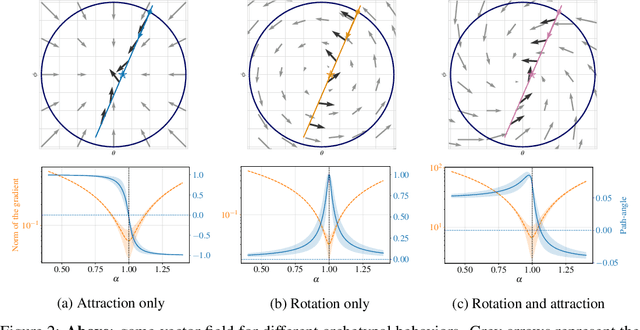
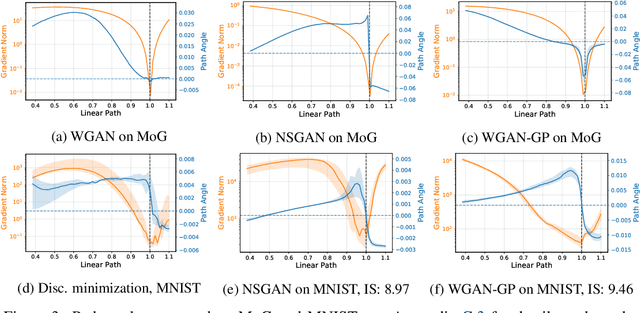
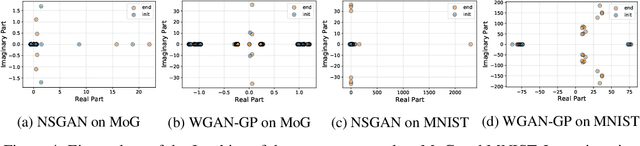
Generative adversarial networks have been very successful in generative modeling, however they remain relatively hard to optimize compared to standard deep neural networks. In this paper, we try to gain insight into the optimization of GANs by looking at the game vector field resulting from the concatenation of the gradient of both players. Based on this point of view, we propose visualization techniques that allow us to make the following empirical observations. First, the training of GANs suffers from rotational behavior around locally stable stationary points, which, as we show, corresponds to the presence of imaginary components in the eigenvalues of the Jacobian of the game. Secondly, GAN training seems to converge to a stable stationary point which is a saddle point for the generator loss, not a minimum, while still achieving excellent performance. This counter-intuitive yet persistent observation questions whether we actually need a Nash equilibrium to get good performance in GANs.
Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
Jun 18, 2018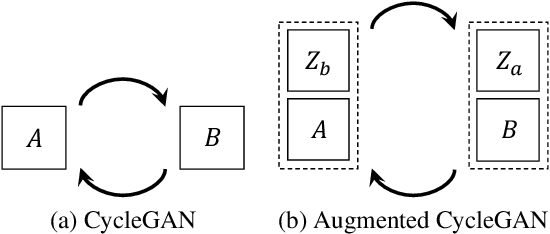

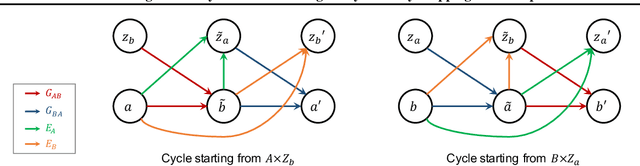

Learning inter-domain mappings from unpaired data can improve performance in structured prediction tasks, such as image segmentation, by reducing the need for paired data. CycleGAN was recently proposed for this problem, but critically assumes the underlying inter-domain mapping is approximately deterministic and one-to-one. This assumption renders the model ineffective for tasks requiring flexible, many-to-many mappings. We propose a new model, called Augmented CycleGAN, which learns many-to-many mappings between domains. We examine Augmented CycleGAN qualitatively and quantitatively on several image datasets.
Learning Distributed Representations from Reviews for Collaborative Filtering
Jun 18, 2018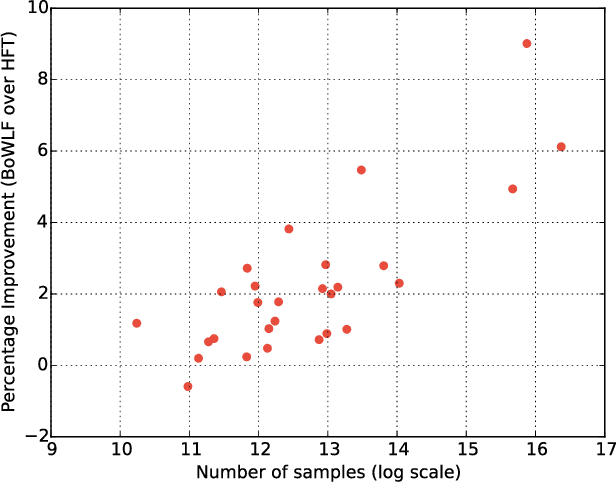
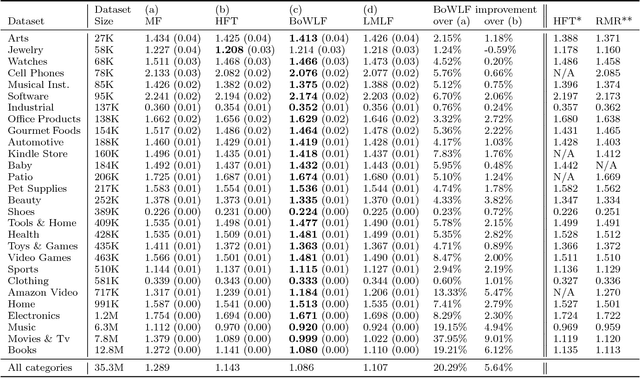
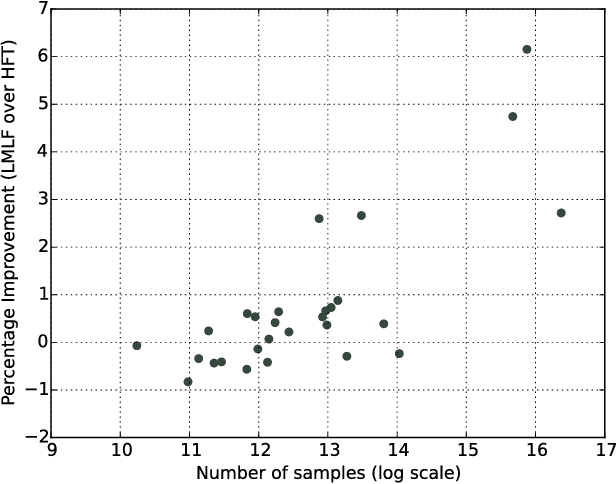
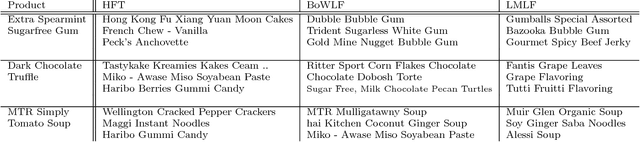
Recent work has shown that collaborative filter-based recommender systems can be improved by incorporating side information, such as natural language reviews, as a way of regularizing the derived product representations. Motivated by the success of this approach, we introduce two different models of reviews and study their effect on collaborative filtering performance. While the previous state-of-the-art approach is based on a latent Dirichlet allocation (LDA) model of reviews, the models we explore are neural network based: a bag-of-words product-of-experts model and a recurrent neural network. We demonstrate that the increased flexibility offered by the product-of-experts model allowed it to achieve state-of-the-art performance on the Amazon review dataset, outperforming the LDA-based approach. However, interestingly, the greater modeling power offered by the recurrent neural network appears to undermine the model's ability to act as a regularizer of the product representations.
Calibrating Energy-based Generative Adversarial Networks
Feb 24, 2017
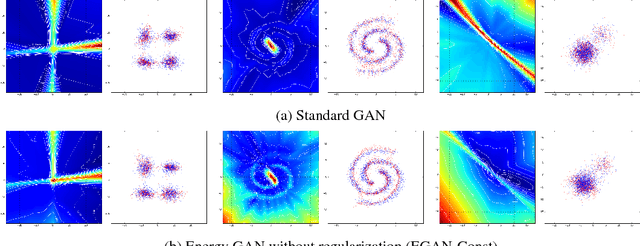
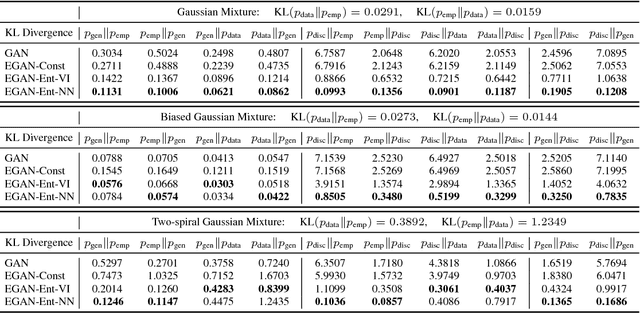
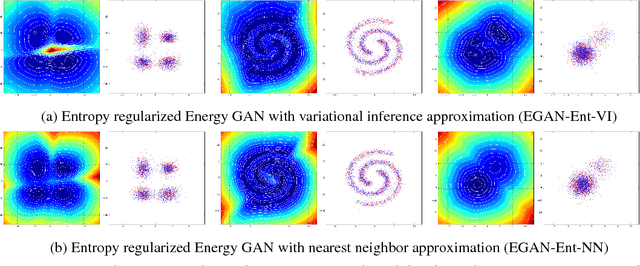
In this paper, we propose to equip Generative Adversarial Networks with the ability to produce direct energy estimates for samples.Specifically, we propose a flexible adversarial training framework, and prove this framework not only ensures the generator converges to the true data distribution, but also enables the discriminator to retain the density information at the global optimal. We derive the analytic form of the induced solution, and analyze the properties. In order to make the proposed framework trainable in practice, we introduce two effective approximation techniques. Empirically, the experiment results closely match our theoretical analysis, verifying the discriminator is able to recover the energy of data distribution.
First Result on Arabic Neural Machine Translation
Jun 08, 2016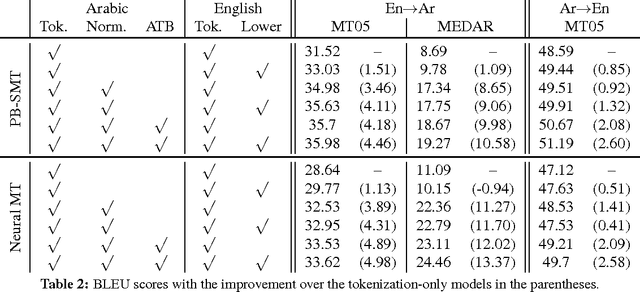
Neural machine translation has become a major alternative to widely used phrase-based statistical machine translation. We notice however that much of research on neural machine translation has focused on European languages despite its language agnostic nature. In this paper, we apply neural machine translation to the task of Arabic translation (Ar<->En) and compare it against a standard phrase-based translation system. We run extensive comparison using various configurations in preprocessing Arabic script and show that the phrase-based and neural translation systems perform comparably to each other and that proper preprocessing of Arabic script has a similar effect on both of the systems. We however observe that the neural machine translation significantly outperform the phrase-based system on an out-of-domain test set, making it attractive for real-world deployment.
Dynamic Capacity Networks
May 22, 2016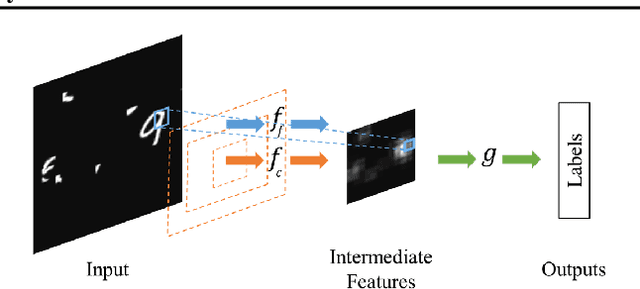
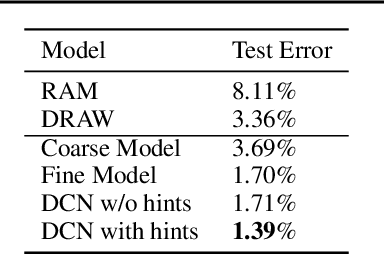
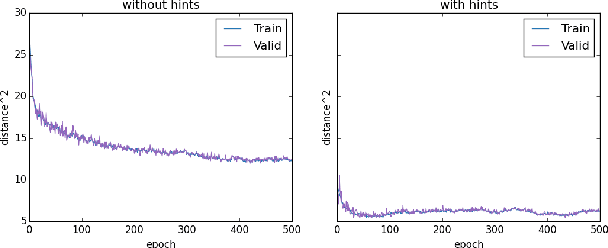
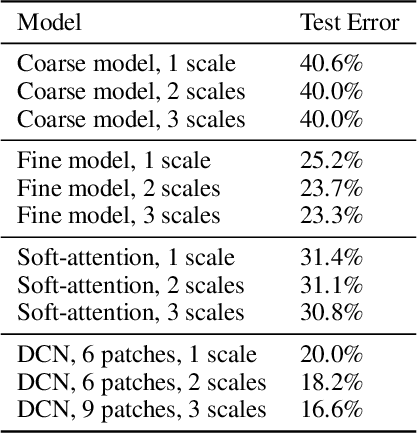
We introduce the Dynamic Capacity Network (DCN), a neural network that can adaptively assign its capacity across different portions of the input data. This is achieved by combining modules of two types: low-capacity sub-networks and high-capacity sub-networks. The low-capacity sub-networks are applied across most of the input, but also provide a guide to select a few portions of the input on which to apply the high-capacity sub-networks. The selection is made using a novel gradient-based attention mechanism, that efficiently identifies input regions for which the DCN's output is most sensitive and to which we should devote more capacity. We focus our empirical evaluation on the Cluttered MNIST and SVHN image datasets. Our findings indicate that DCNs are able to drastically reduce the number of computations, compared to traditional convolutional neural networks, while maintaining similar or even better performance.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.