 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Automatic Post-editing for Arabic-Japanese Machine Translation
Jul 14, 2019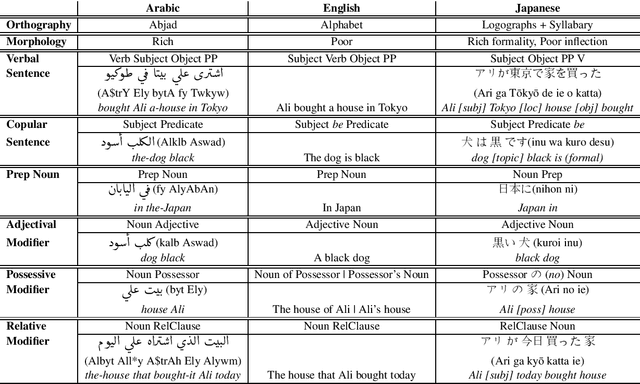


A common bottleneck for developing machine translation (MT) systems for some language pairs is the lack of direct parallel translation data sets, in general and in certain domains. Alternative solutions such as zero-shot models or pivoting techniques are successful in getting a strong baseline, but are often below the more supported language-pair systems. In this paper, we focus on Arabic-Japanese machine translation, a less studied language pair; and we work with a unique parallel corpus of Arabic news articles that were manually translated to Japanese. We use this parallel corpus to adapt a state-of-the-art domain/genre agnostic neural MT system via a simple automatic post-editing technique. Our results and detailed analysis suggest that this approach is quite viable for less supported language pairs in specific domains.
The Impact of Preprocessing on Arabic-English Statistical and Neural Machine Translation
Jun 27, 2019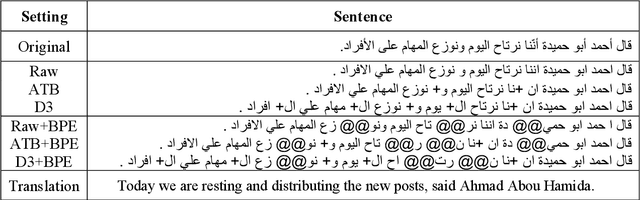
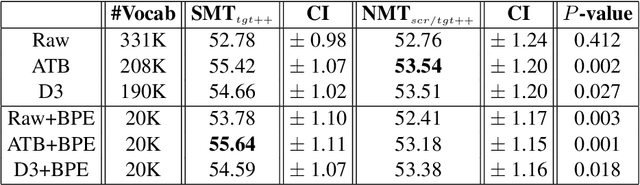
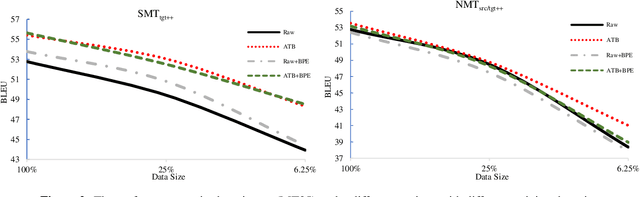

Neural networks have become the state-of-the-art approach for machine translation (MT) in many languages. While linguistically-motivated tokenization techniques were shown to have significant effects on the performance of statistical MT, it remains unclear if those techniques are well suited for neural MT. In this paper, we systematically compare neural and statistical MT models for Arabic-English translation on data preprecossed by various prominent tokenization schemes. Furthermore, we consider a range of data and vocabulary sizes and compare their effect on both approaches. Our empirical results show that the best choice of tokenization scheme is largely based on the type of model and the size of data. We also show that we can gain significant improvements using a system selection that combines the output from neural and statistical MT.