 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-based graph network simulator
Dec 16, 2021
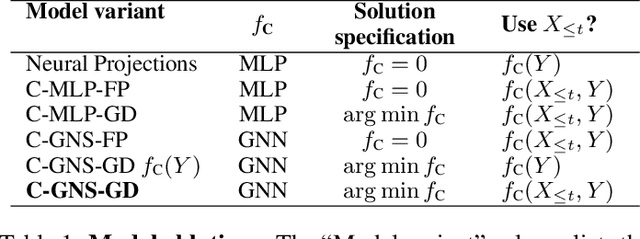

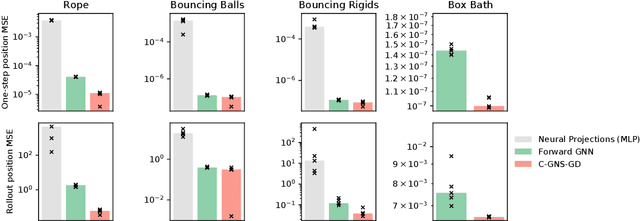
In the rapidly advancing area of learned physical simulators, nearly all methods train forward models that directly predict future states from input states. However, many traditional simulation engines use a constraint-based approach instead of direct prediction. Here we present a framework for constraint-based learned simulation, where a scalar constraint function is implemented as a neural network, and future predictions are computed as the solutions to optimization problems under these learned constraints. We implement our method using a graph neural network as the constraint function and gradient descent as the constraint solver. The architecture can be trained by standard backpropagation. We test the model on a variety of challenging physical domains, including simulated ropes, bouncing balls, colliding irregular shapes and splashing fluids. Our model achieves better or comparable performance to top learned simulators. A key advantage of our model is the ability to generalize to more solver iterations at test time to improve the simulation accuracy. We also show how hand-designed constraints can be added at test time to satisfy objectives which were not present in the training data, which is not possible with forward approaches. Our constraint-based framework is applicable to any setting where forward learned simulators are used, and demonstrates how learned simulators can leverage additional inductive biases as well as the techniques from the field of numerical methods.
Learning ground states of quantum Hamiltonians with graph networks
Oct 12, 2021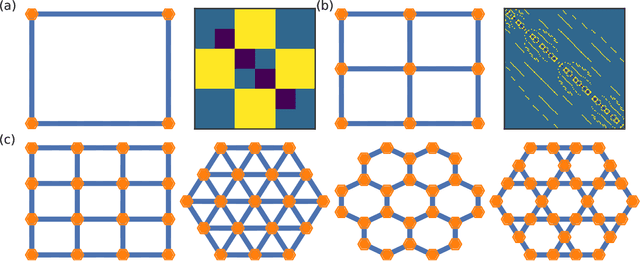
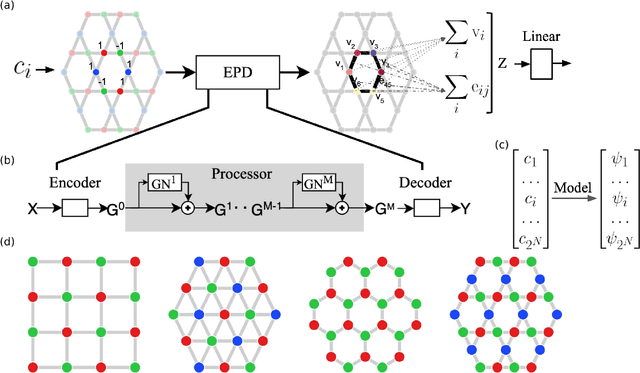
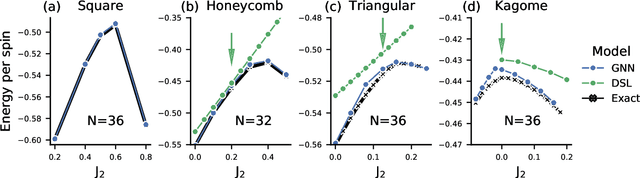
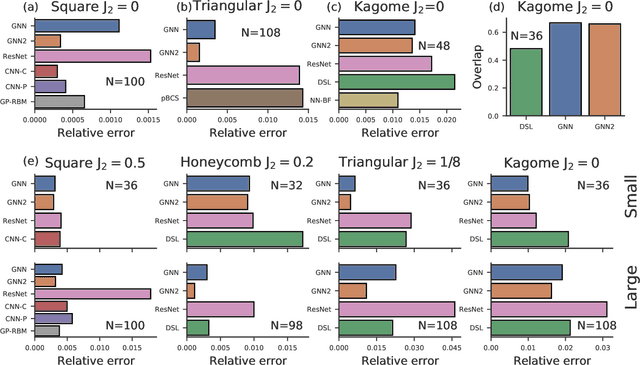
Solving for the lowest energy eigenstate of the many-body Schrodinger equation is a cornerstone problem that hinders understanding of a variety of quantum phenomena. The difficulty arises from the exponential nature of the Hilbert space which casts the governing equations as an eigenvalue problem of exponentially large, structured matrices. Variational methods approach this problem by searching for the best approximation within a lower-dimensional variational manifold. In this work we use graph neural networks to define a structured variational manifold and optimize its parameters to find high quality approximations of the lowest energy solutions on a diverse set of Heisenberg Hamiltonians. Using graph networks we learn distributed representations that by construction respect underlying physical symmetries of the problem and generalize to problems of larger size. Our approach achieves state-of-the-art results on a set of quantum many-body benchmark problems and works well on problems whose solutions are not positive-definite. The discussed techniques hold promise of being a useful tool for studying quantum many-body systems and providing insights into optimization and implicit modeling of exponentially-sized objects.
ETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021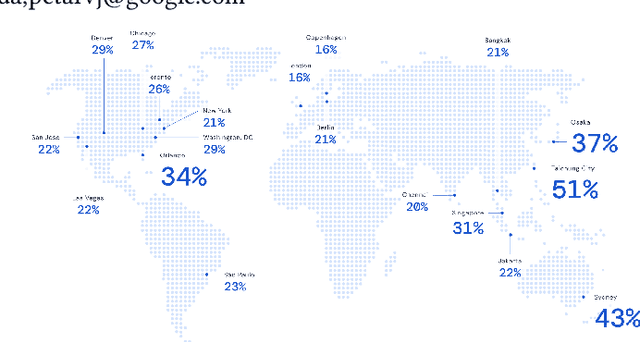


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
Large-scale graph representation learning with very deep GNNs and self-supervision
Jul 20, 2021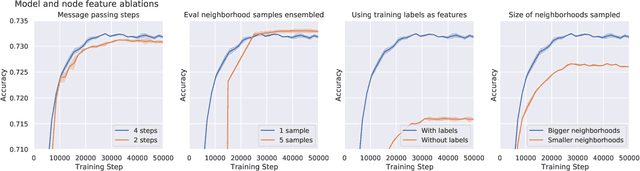
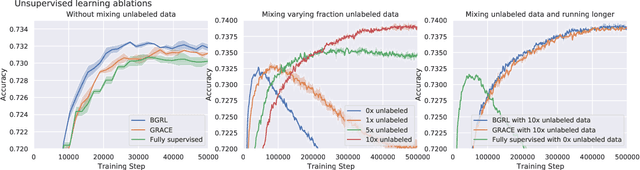
Effectively and efficiently deploying graph neural networks (GNNs) at scale remains one of the most challenging aspects of graph representation learning. Many powerful solutions have only ever been validated on comparatively small datasets, often with counter-intuitive outcomes -- a barrier which has been broken by the Open Graph Benchmark Large-Scale Challenge (OGB-LSC). We entered the OGB-LSC with two large-scale GNNs: a deep transductive node classifier powered by bootstrapping, and a very deep (up to 50-layer) inductive graph regressor regularised by denoising objectives. Our models achieved an award-level (top-3) performance on both the MAG240M and PCQM4M benchmarks. In doing so, we demonstrate evidence of scalable self-supervised graph representation learning, and utility of very deep GNNs -- both very important open issues. Our code is publicly available at: https://github.com/deepmind/deepmind-research/tree/master/ogb_lsc.
Very Deep Graph Neural Networks Via Noise Regularisation
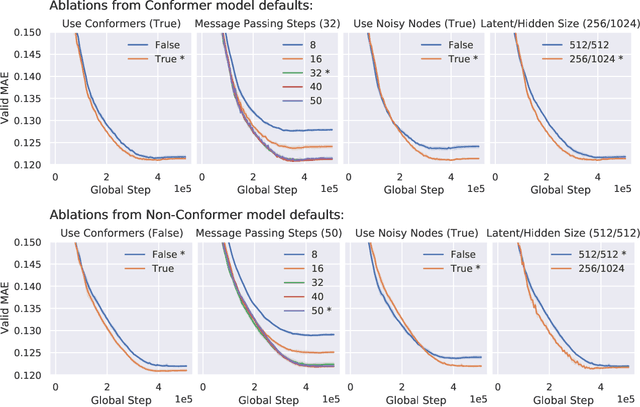
Jun 15, 2021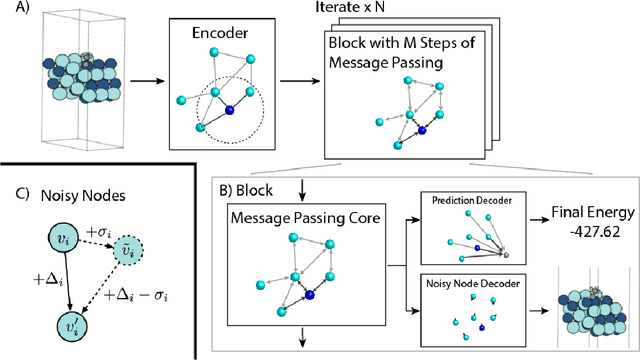
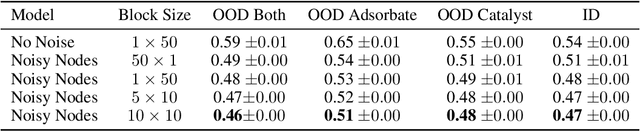
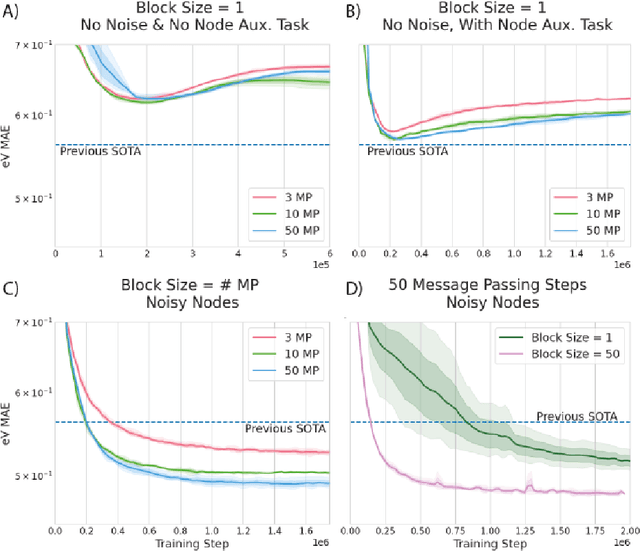
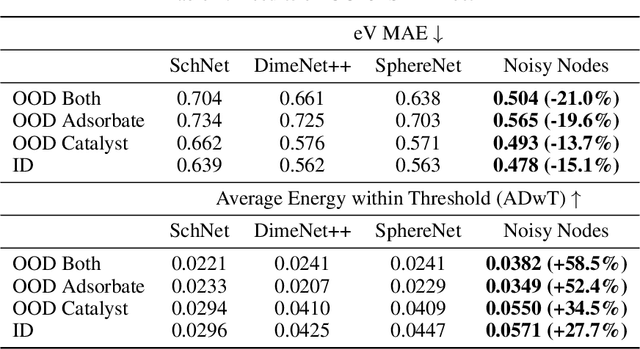
Graph Neural Networks (GNNs) perform learned message passing over an input graph, but conventional wisdom says performing more than handful of steps makes training difficult and does not yield improved performance. Here we show the contrary. We train a deep GNN with up to 100 message passing steps and achieve several state-of-the-art results on two challenging molecular property prediction benchmarks, Open Catalyst 2020 IS2RE and QM9. Our approach depends crucially on a novel but simple regularisation method, which we call ``Noisy Nodes'', in which we corrupt the input graph with noise and add an auxiliary node autoencoder loss if the task is graph property prediction. Our results show this regularisation method allows the model to monotonically improve in performance with increased message passing steps. Our work opens new opportunities for reaping the benefits of deep neural networks in the space of graph and other structured prediction problems.
Learning Mesh-Based Simulation with Graph Networks
Oct 07, 2020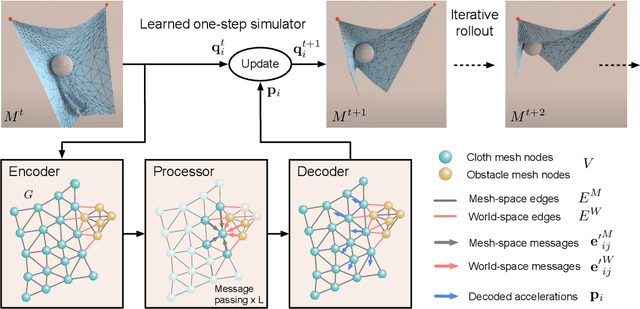
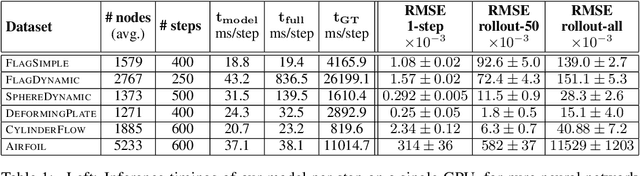
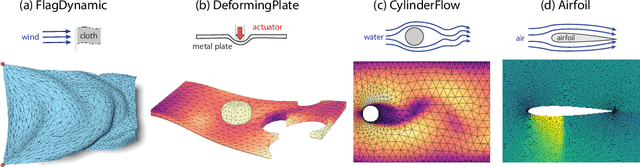
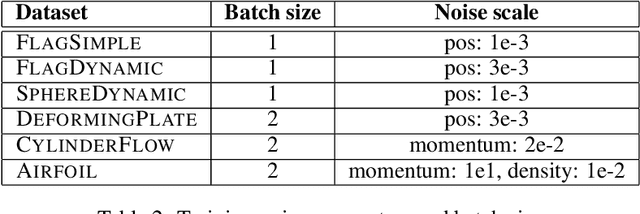
Mesh-based simulations are central to modeling complex physical systems in many disciplines across science and engineering. Mesh representations support powerful numerical integration methods and their resolution can be adapted to strike favorable trade-offs between accuracy and efficiency. However, high-dimensional scientific simulations are very expensive to run, and solvers and parameters must often be tuned individually to each system studied. Here we introduce MeshGraphNets, a framework for learning mesh-based simulations using graph neural networks. Our model can be trained to pass messages on a mesh graph and to adapt the mesh discretization during forward simulation. Our results show it can accurately predict the dynamics of a wide range of physical systems, including aerodynamics, structural mechanics, and cloth. The model's adaptivity supports learning resolution-independent dynamics and can scale to more complex state spaces at test time. Our method is also highly efficient, running 1-2 orders of magnitude faster than the simulation on which it is trained. Our approach broadens the range of problems on which neural network simulators can operate and promises to improve the efficiency of complex, scientific modeling tasks.
Discovering Symbolic Models from Deep Learning with Inductive Biases
Jun 19, 2020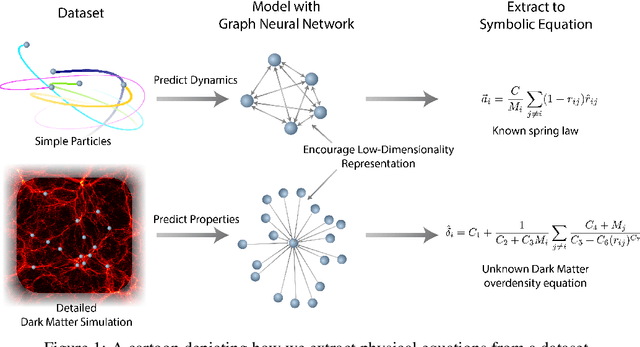

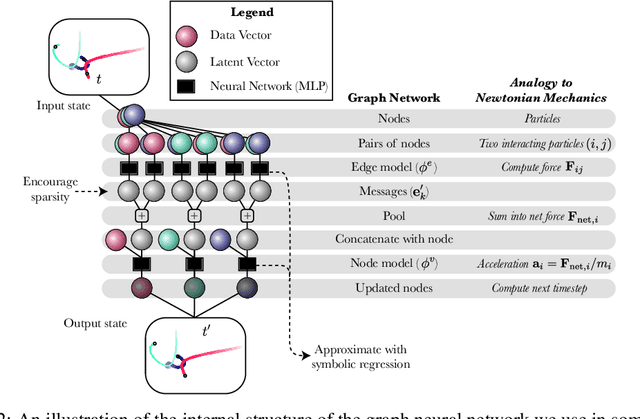

We develop a general approach to distill symbolic representations of a learned deep model by introducing strong inductive biases. We focus on Graph Neural Networks (GNNs). The technique works as follows: we first encourage sparse latent representations when we train a GNN in a supervised setting, then we apply symbolic regression to components of the learned model to extract explicit physical relations. We find the correct known equations, including force laws and Hamiltonians, can be extracted from the neural network. We then apply our method to a non-trivial cosmology example-a detailed dark matter simulation-and discover a new analytic formula which can predict the concentration of dark matter from the mass distribution of nearby cosmic structures. The symbolic expressions extracted from the GNN using our technique also generalized to out-of-distribution data better than the GNN itself. Our approach offers alternative directions for interpreting neural networks and discovering novel physical principles from the representations they learn.
Learning to Simulate Complex Physics with Graph Networks
Feb 21, 2020
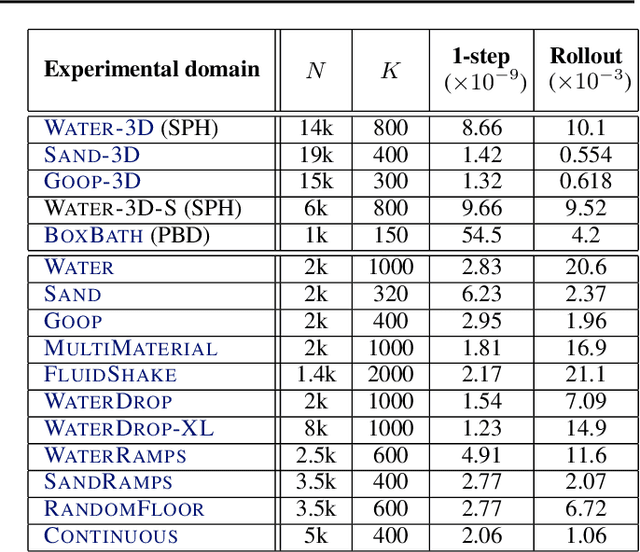
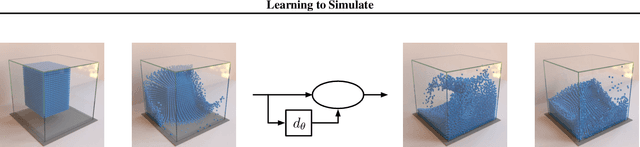
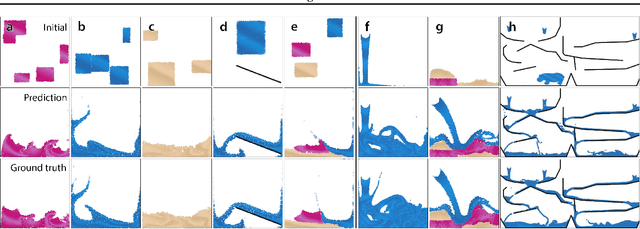
Here we present a general framework for learning simulation, and provide a single model implementation that yields state-of-the-art performance across a variety of challenging physical domains, involving fluids, rigid solids, and deformable materials interacting with one another. Our framework---which we term "Graph Network-based Simulators" (GNS)---represents the state of a physical system with particles, expressed as nodes in a graph, and computes dynamics via learned message-passing. Our results show that our model can generalize from single-timestep predictions with thousands of particles during training, to different initial conditions, thousands of timesteps, and at least an order of magnitude more particles at test time. Our model was robust to hyperparameter choices across various evaluation metrics: the main determinants of long-term performance were the number of message-passing steps, and mitigating the accumulation of error by corrupting the training data with noise. Our GNS framework is the most accurate general-purpose learned physics simulator to date, and holds promise for solving a wide range of complex forward and inverse problems.
Combining Q-Learning and Search with Amortized Value Estimates
Jan 10, 2020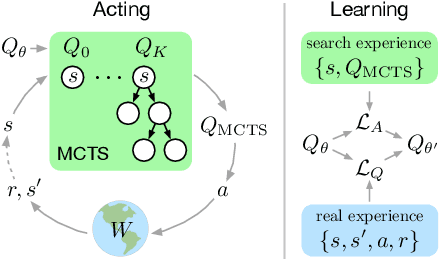
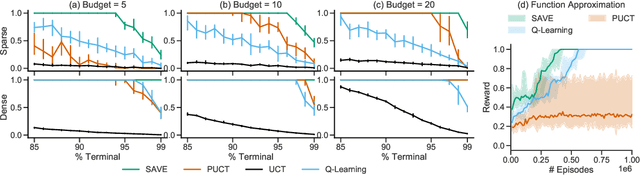
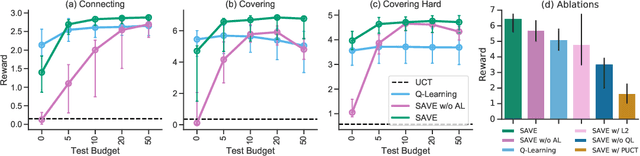
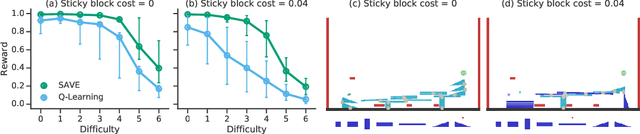
We introduce "Search with Amortized Value Estimates" (SAVE), an approach for combining model-free Q-learning with model-based Monte-Carlo Tree Search (MCTS). In SAVE, a learned prior over state-action values is used to guide MCTS, which estimates an improved set of state-action values. The new Q-estimates are then used in combination with real experience to update the prior. This effectively amortizes the value computation performed by MCTS, resulting in a cooperative relationship between model-free learning and model-based search. SAVE can be implemented on top of any Q-learning agent with access to a model, which we demonstrate by incorporating it into agents that perform challenging physical reasoning tasks and Atari. SAVE consistently achieves higher rewards with fewer training steps, and---in contrast to typical model-based search approaches---yields strong performance with very small search budgets. By combining real experience with information computed during search, SAVE demonstrates that it is possible to improve on both the performance of model-free learning and the computational cost of planning.
Object-oriented state editing for HRL
Oct 31, 2019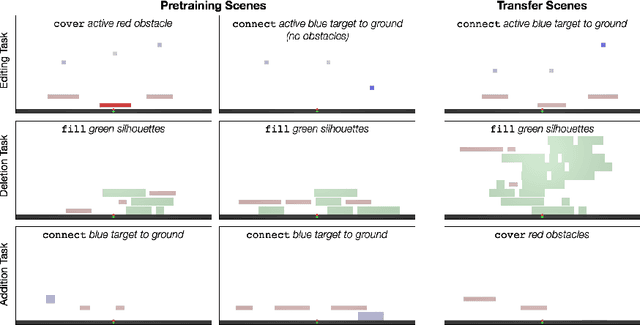
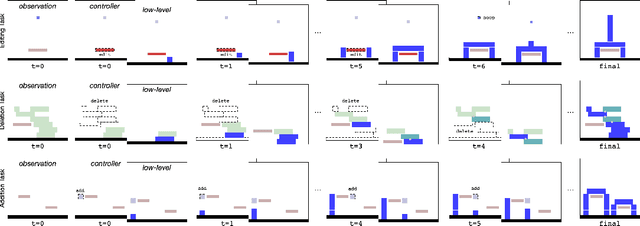
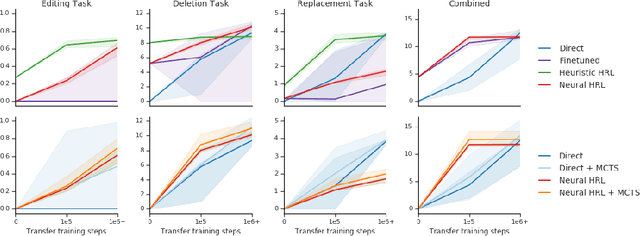

We introduce agents that use object-oriented reasoning to consider alternate states of the world in order to more quickly find solutions to problems. Specifically, a hierarchical controller directs a low-level agent to behave as if objects in the scene were added, deleted, or modified. The actions taken by the controller are defined over a graph-based representation of the scene, with actions corresponding to adding, deleting, or editing the nodes of a graph. We present preliminary results on three environments, demonstrating that our approach can achieve similar levels of reward as non-hierarchical agents, but with better data efficiency.