 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunistic Episodic Reinforcement Learning
Oct 24, 2022



In this paper, we propose and study opportunistic reinforcement learning - a new variant of reinforcement learning problems where the regret of selecting a suboptimal action varies under an external environmental condition known as the variation factor. When the variation factor is low, so is the regret of selecting a suboptimal action and vice versa. Our intuition is to exploit more when the variation factor is high, and explore more when the variation factor is low. We demonstrate the benefit of this novel framework for finite-horizon episodic MDPs by designing and evaluating OppUCRL2 and OppPSRL algorithms. Our algorithms dynamically balance the exploration-exploitation trade-off for reinforcement learning by introducing variation factor-dependent optimism to guide exploration. We establish an $\tilde{O}(HS \sqrt{AT})$ regret bound for the OppUCRL2 algorithm and show through simulations that both OppUCRL2 and OppPSRL algorithm outperform their original corresponding algorithms.
ETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021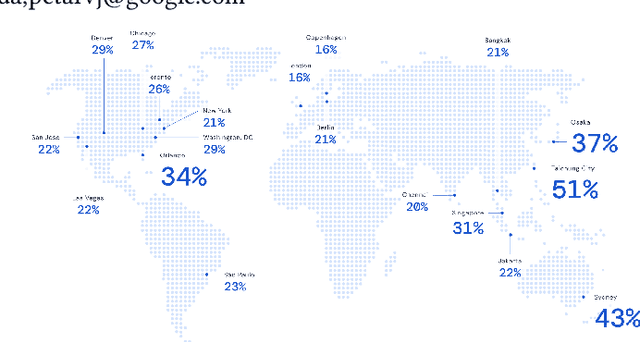


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
AdaLinUCB: Opportunistic Learning for Contextual Bandits
Feb 20, 2019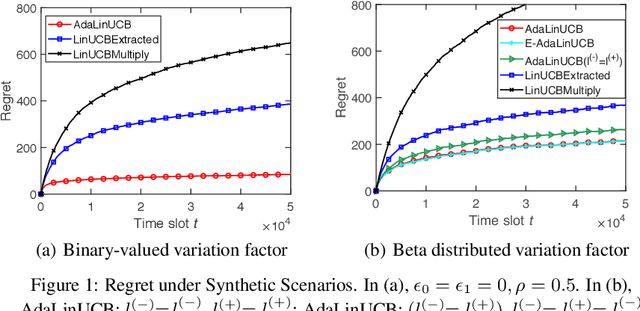
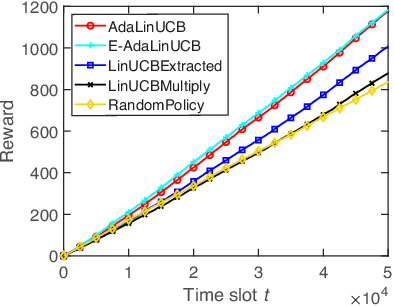
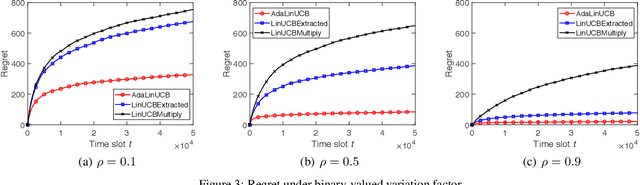
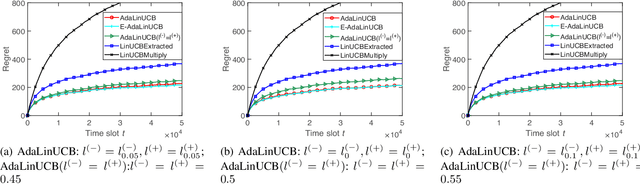
In this paper, we propose and study opportunistic contextual bandits - a special case of contextual bandits where the exploration cost varies under different environmental conditions, such as network load or return variation in recommendations. When the exploration cost is low, so is the actual regret of pulling a sub-optimal arm (e.g., trying a suboptimal recommendation). Therefore, intuitively, we could explore more when the exploration cost is relatively low and exploit more when the exploration cost is relatively high. Inspired by this intuition, for opportunistic contextual bandits with Linear payoffs, we propose an Adaptive Upper-Confidence-Bound algorithm (AdaLinUCB) to adaptively balance the exploration-exploitation trade-off for opportunistic learning. We prove that AdaLinUCB achieves O((log T)^2) problem-dependent regret upper bound, which has a smaller coefficient than that of the traditional LinUCB algorithm. Moreover, based on both synthetic and real-world dataset, we show that AdaLinUCB significantly outperforms other contextual bandit algorithms, under large exploration cost fluctuations.
Kernel-based Multi-Task Contextual Bandits in Cellular Network Configuration
Nov 27, 2018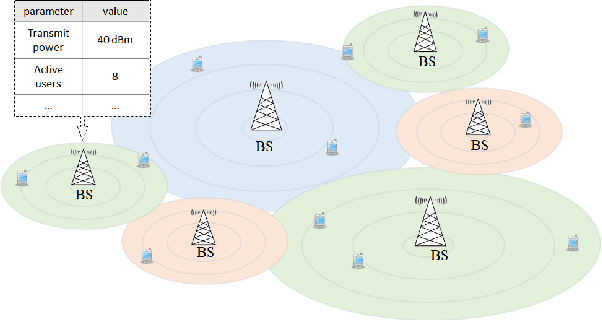

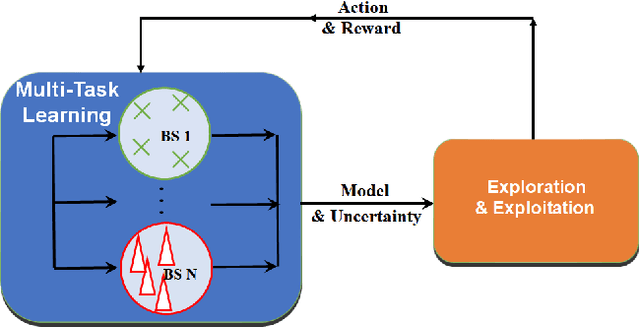
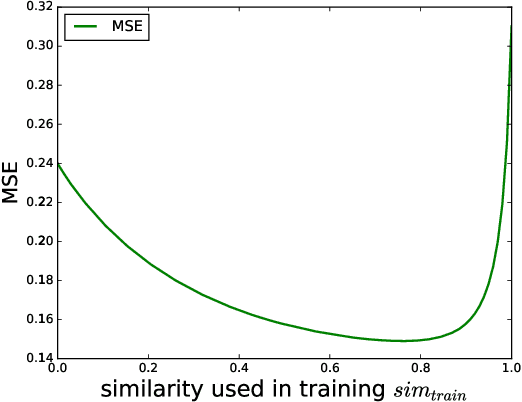
Cellular network configuration plays a critical role in network performance. In current practice, network configuration depends heavily on field experience of engineers and often remains static for a long period of time. This practice is far from optimal. To address this limitation, online-learning-based approaches have great potentials to automate and optimize network configuration. Learning-based approaches face the challenges of learning a highly complex function for each base station and balancing the fundamental exploration-exploitation tradeoff while minimizing the exploration cost. Fortunately, in cellular networks, base stations (BSs) often have similarities even though they are not identical. To leverage such similarities, we propose kernel-based multi-BS contextual bandit algorithm based on multi-task learning. In the algorithm, we leverage the similarity among different BSs defined by conditional kernel embedding. We present theoretical analysis of the proposed algorithm in terms of regret and multi-task-learning efficiency. We evaluate the effectiveness of our algorithm based on a simulator built by real traces.
Adaptive Exploration-Exploitation Tradeoff for Opportunistic Bandits
Sep 12, 2017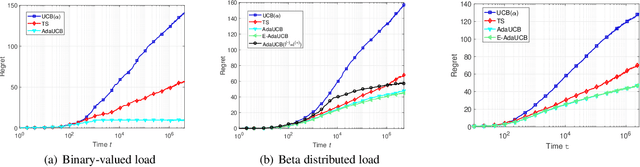
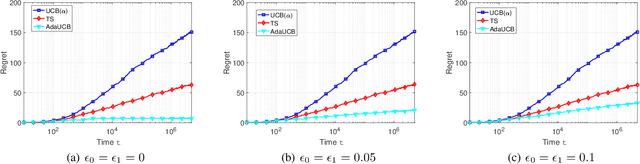
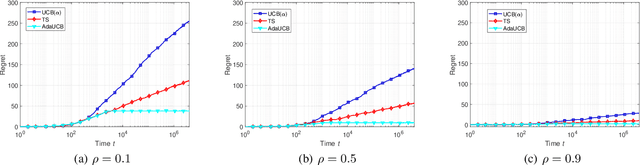
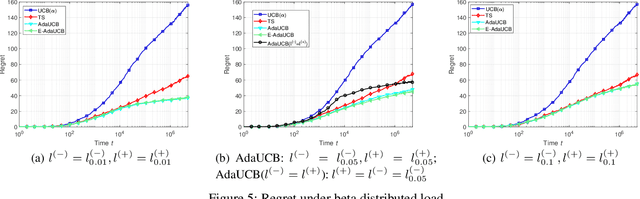
In this paper, we propose and study opportunistic bandits - a new variant of bandits where the regret of pulling a suboptimal arm varies under different environmental conditions, such as network load or produce price. When the load/price is low, so is the cost/regret of pulling a suboptimal arm (e.g., trying a suboptimal network configuration). Therefore, intuitively, we could explore more when the load is low and exploit more when the load is high. Inspired by this intuition, we propose an Adaptive Upper-Confidence-Bound (AdaUCB) algorithm to adaptively balance the exploration-exploitation tradeoff for opportunistic bandits. We prove that AdaUCB achieves $O(\log T)$ regret with a smaller coefficient than the traditional UCB algorithm. Furthermore, AdaUCB achieves $O(1)$ regret when the exploration cost is zero if the load level is below a certain threshold. Last, based on both synthetic data and real-world traces, experimental results show that AdaUCB significantly outperforms other bandit algorithms, such as UCB and TS (Thompson Sampling), under large load fluctuations.