 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mar 10, 2022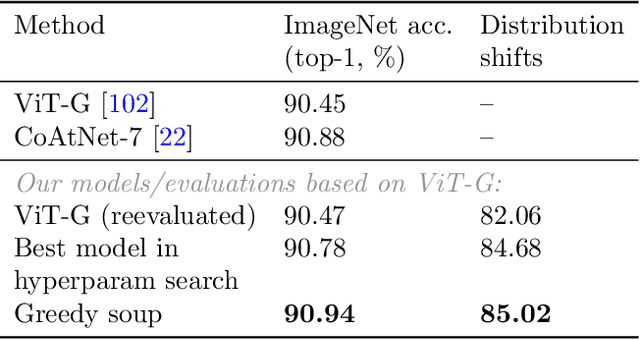
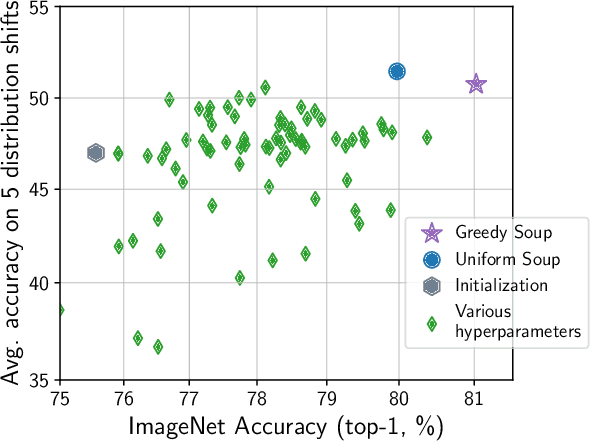

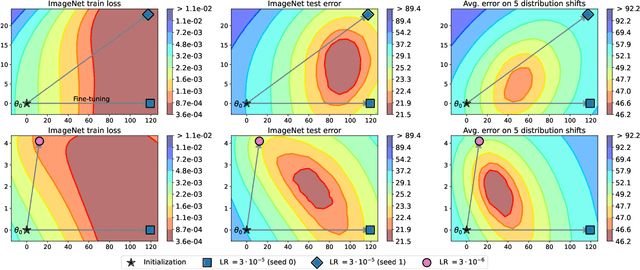
The conventional recipe for maximizing model accuracy is to (1) train multiple models with various hyperparameters and (2) pick the individual model which performs best on a held-out validation set, discarding the remainder. In this paper, we revisit the second step of this procedure in the context of fine-tuning large pre-trained models, where fine-tuned models often appear to lie in a single low error basin. We show that averaging the weights of multiple models fine-tuned with different hyperparameter configurations often improves accuracy and robustness. Unlike a conventional ensemble, we may average many models without incurring any additional inference or memory costs -- we call the results "model soups." When fine-tuning large pre-trained models such as CLIP, ALIGN, and a ViT-G pre-trained on JFT, our soup recipe provides significant improvements over the best model in a hyperparameter sweep on ImageNet. As a highlight, the resulting ViT-G model attains 90.94% top-1 accuracy on ImageNet, a new state of the art. Furthermore, we show that the model soup approach extends to multiple image classification and natural language processing tasks, improves out-of-distribution performance, and improves zero-shot performance on new downstream tasks. Finally, we analytically relate the performance similarity of weight-averaging and logit-ensembling to flatness of the loss and confidence of the predictions, and validate this relation empirically.
MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Jan 07, 2022
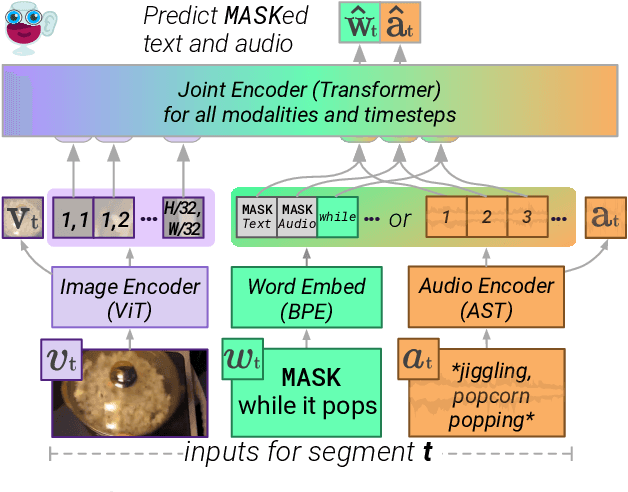

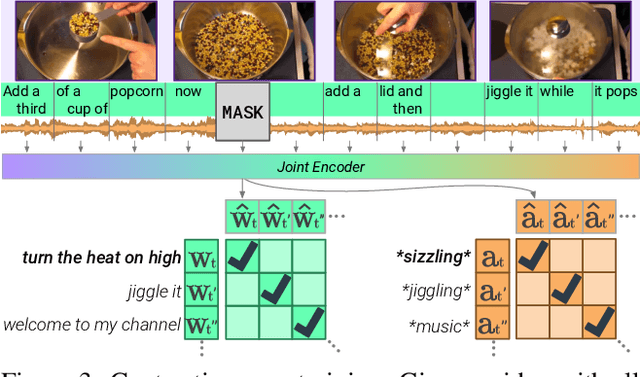
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.
The Introspective Agent: Interdependence of Strategy, Physiology, and Sensing for Embodied Agents
Jan 02, 2022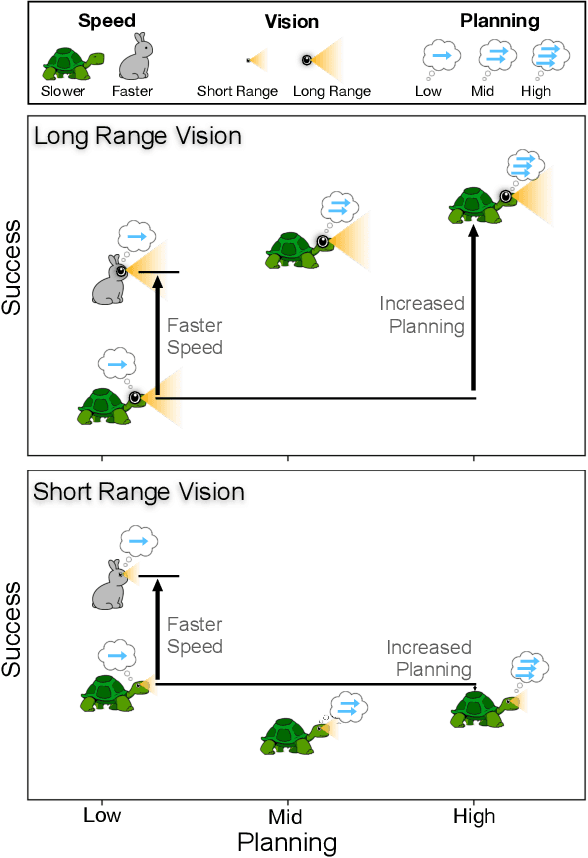
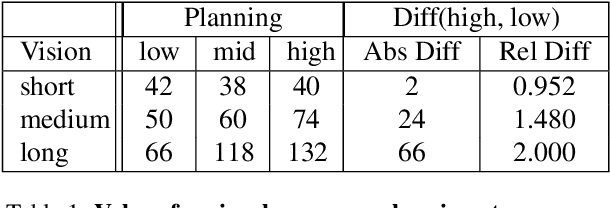
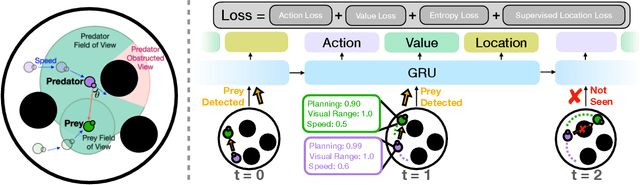

The last few years have witnessed substantial progress in the field of embodied AI where artificial agents, mirroring biological counterparts, are now able to learn from interaction to accomplish complex tasks. Despite this success, biological organisms still hold one large advantage over these simulated agents: adaptation. While both living and simulated agents make decisions to achieve goals (strategy), biological organisms have evolved to understand their environment (sensing) and respond to it (physiology). The net gain of these factors depends on the environment, and organisms have adapted accordingly. For example, in a low vision aquatic environment some fish have evolved specific neurons which offer a predictable, but incredibly rapid, strategy to escape from predators. Mammals have lost these reactive systems, but they have a much larger fields of view and brain circuitry capable of understanding many future possibilities. While traditional embodied agents manipulate an environment to best achieve a goal, we argue for an introspective agent, which considers its own abilities in the context of its environment. We show that different environments yield vastly different optimal designs, and increasing long-term planning is often far less beneficial than other improvements, such as increased physical ability. We present these findings to broaden the definition of improvement in embodied AI passed increasingly complex models. Just as in nature, we hope to reframe strategy as one tool, among many, to succeed in an environment. Code is available at: https://github.com/sarahpratt/introspective.
Forward Compatible Training for Representation Learning
Dec 06, 2021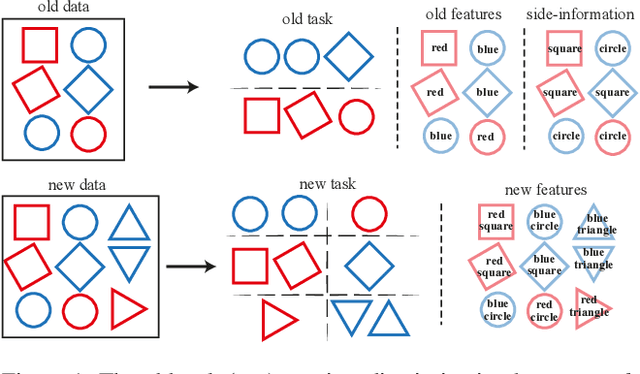
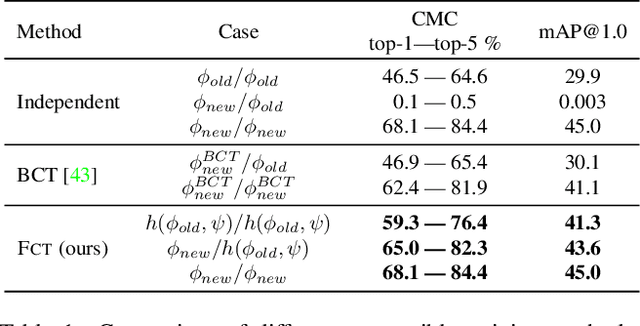

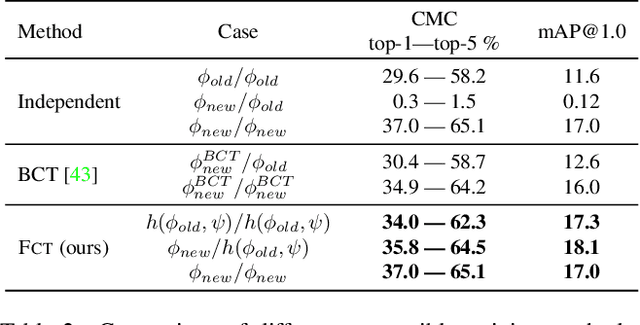
In visual retrieval systems, updating the embedding model requires recomputing features for every piece of data. This expensive process is referred to as backfilling. Recently, the idea of backward compatible training (BCT) was proposed. To avoid the cost of backfilling, BCT modifies training of the new model to make its representations compatible with those of the old model. However, BCT can significantly hinder the performance of the new model. In this work, we propose a new learning paradigm for representation learning: forward compatible training (FCT). In FCT, when the old model is trained, we also prepare for a future unknown version of the model. We propose learning side-information, an auxiliary feature for each sample which facilitates future updates of the model. To develop a powerful and flexible framework for model compatibility, we combine side-information with a forward transformation from old to new embeddings. Training of the new model is not modified, hence, its accuracy is not degraded. We demonstrate significant retrieval accuracy improvement compared to BCT for various datasets: ImageNet-1k (+18.1%), Places-365 (+5.4%), and VGG-Face2 (+8.3%). FCT obtains model compatibility when the new and old models are trained across different datasets, losses, and architectures.
Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text
Dec 01, 2021Communicating with humans is challenging for AIs because it requires a shared understanding of the world, complex semantics (e.g., metaphors or analogies), and at times multi-modal gestures (e.g., pointing with a finger, or an arrow in a diagram). We investigate these challenges in the context of Iconary, a collaborative game of drawing and guessing based on Pictionary, that poses a novel challenge for the research community. In Iconary, a Guesser tries to identify a phrase that a Drawer is drawing by composing icons, and the Drawer iteratively revises the drawing to help the Guesser in response. This back-and-forth often uses canonical scenes, visual metaphor, or icon compositions to express challenging words, making it an ideal test for mixing language and visual/symbolic communication in AI. We propose models to play Iconary and train them on over 55,000 games between human players. Our models are skillful players and are able to employ world knowledge in language models to play with words unseen during training. Elite human players outperform our models, particularly at the drawing task, leaving an important gap for future research to address. We release our dataset, code, and evaluation setup as a challenge to the community at http://www.github.com/allenai/iconary.
LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time
Oct 08, 2021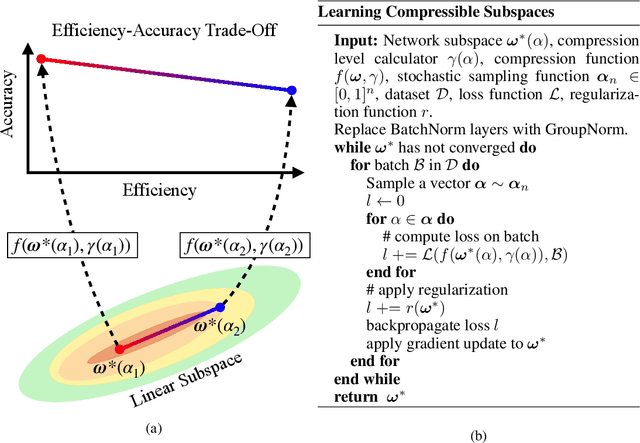

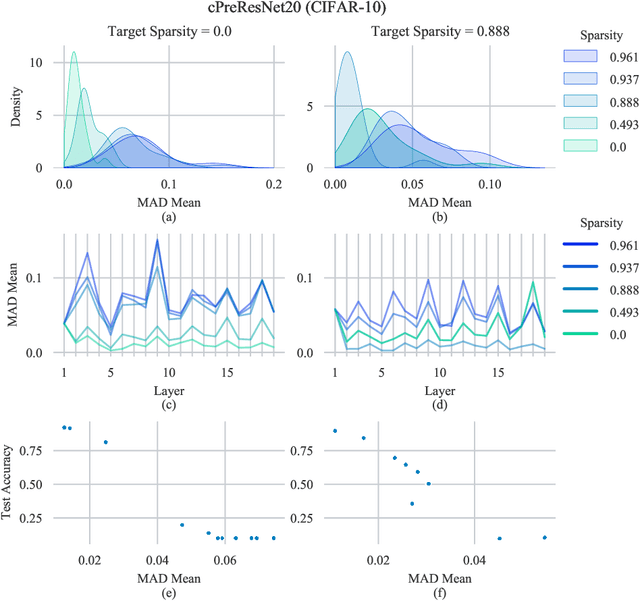
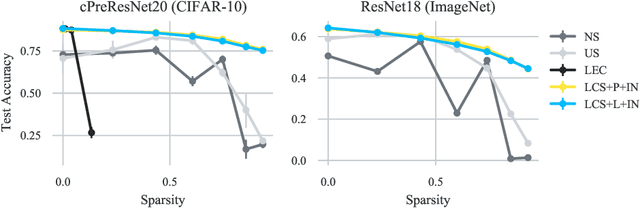
When deploying deep learning models to a device, it is traditionally assumed that available computational resources (compute, memory, and power) remain static. However, real-world computing systems do not always provide stable resource guarantees. Computational resources need to be conserved when load from other processes is high or battery power is low. Inspired by recent works on neural network subspaces, we propose a method for training a "compressible subspace" of neural networks that contains a fine-grained spectrum of models that range from highly efficient to highly accurate. Our models require no retraining, thus our subspace of models can be deployed entirely on-device to allow adaptive network compression at inference time. We present results for achieving arbitrarily fine-grained accuracy-efficiency trade-offs at inference time for structured and unstructured sparsity. We achieve accuracies on-par with standard models when testing our uncompressed models, and maintain high accuracy for sparsity rates above 90% when testing our compressed models. We also demonstrate that our algorithm extends to quantization at variable bit widths, achieving accuracy on par with individually trained networks.
Robust fine-tuning of zero-shot models
Sep 04, 2021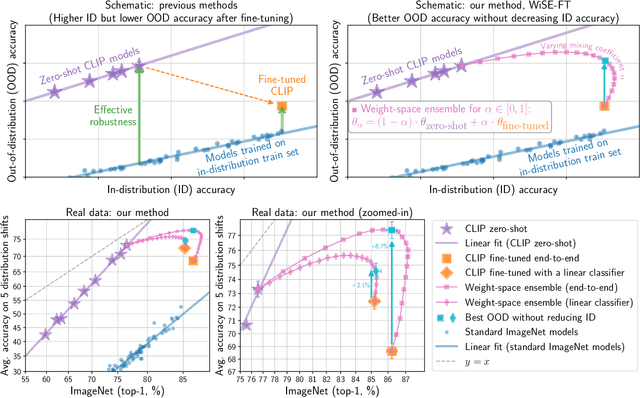
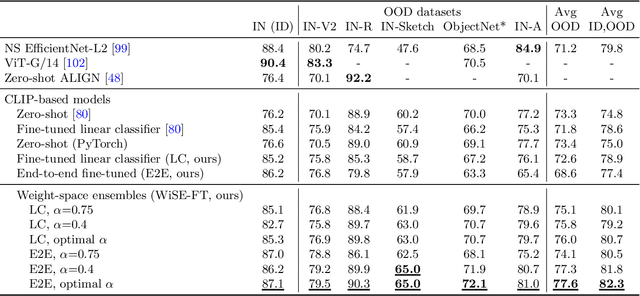

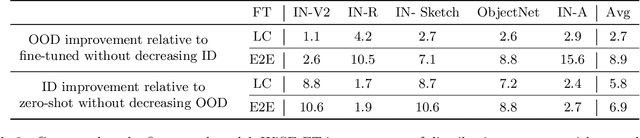
Large pre-trained models such as CLIP offer consistent accuracy across a range of data distributions when performing zero-shot inference (i.e., without fine-tuning on a specific dataset). Although existing fine-tuning approaches substantially improve accuracy in-distribution, they also reduce out-of-distribution robustness. We address this tension by introducing a simple and effective method for improving robustness: ensembling the weights of the zero-shot and fine-tuned models. Compared to standard fine-tuning, the resulting weight-space ensembles provide large accuracy improvements out-of-distribution, while matching or improving in-distribution accuracy. On ImageNet and five derived distribution shifts, weight-space ensembles improve out-of-distribution accuracy by 2 to 10 percentage points while increasing in-distribution accuracy by nearly 1 percentage point relative to standard fine-tuning. These improvements come at no additional computational cost during fine-tuning or inference.
LanguageRefer: Spatial-Language Model for 3D Visual Grounding
Jul 22, 2021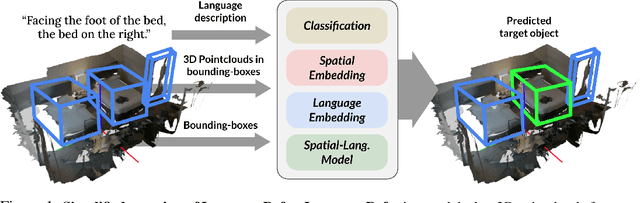
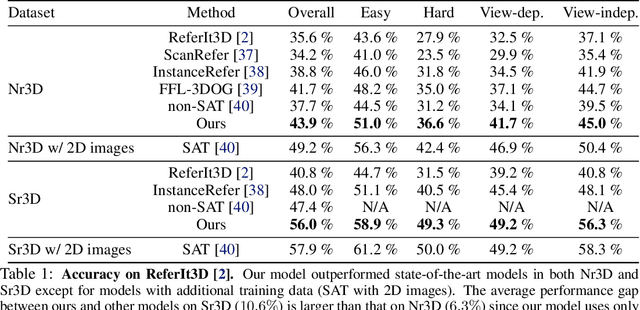
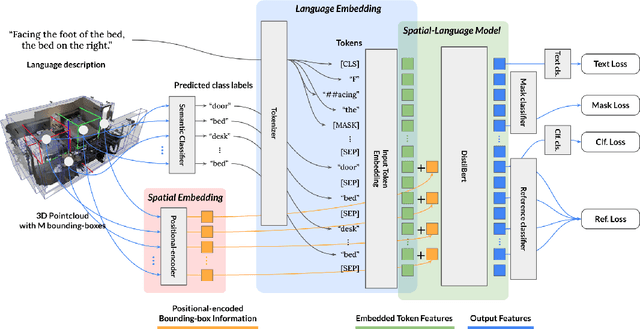
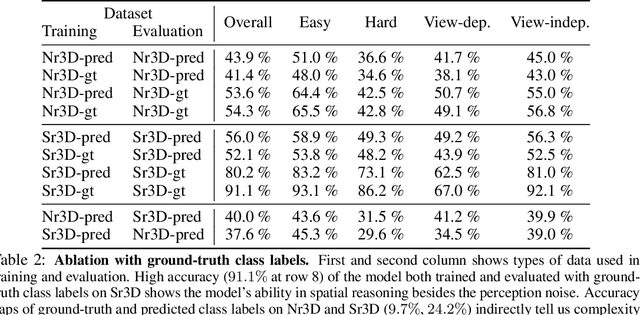
To realize robots that can understand human instructions and perform meaningful tasks in the near future, it is important to develop learned models that can understand referential language to identify common objects in real-world 3D scenes. In this paper, we develop a spatial-language model for a 3D visual grounding problem. Specifically, given a reconstructed 3D scene in the form of a point cloud with 3D bounding boxes of potential object candidates, and a language utterance referring to a target object in the scene, our model identifies the target object from a set of potential candidates. Our spatial-language model uses a transformer-based architecture that combines spatial embedding from bounding-box with a finetuned language embedding from DistilBert and reasons among the objects in the 3D scene to find the target object. We show that our model performs competitively on visio-linguistic datasets proposed by ReferIt3D. We provide additional analysis of performance in spatial reasoning tasks decoupled from perception noise, the effect of view-dependent utterances in terms of accuracy, and view-point annotations for potential robotics applications.
MERLOT: Multimodal Neural Script Knowledge Models
Jun 10, 2021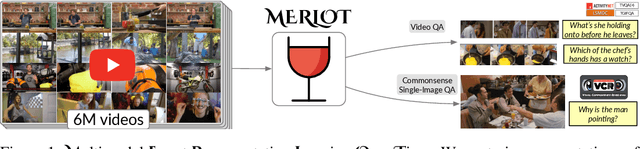
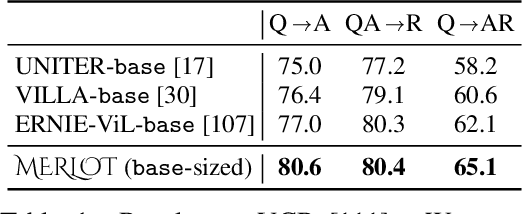
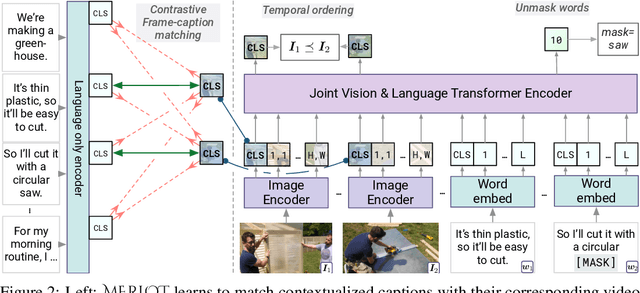
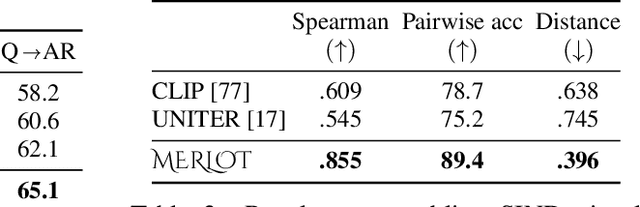
As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time. As a result, MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes). Ablation analyses demonstrate the complementary importance of: 1) training on videos versus static images; 2) scaling the magnitude and diversity of the pretraining video corpus; and 3) using diverse objectives that encourage full-stack multimodal reasoning, from the recognition to cognition level.
LLC: Accurate, Multi-purpose Learnt Low-dimensional Binary Codes
Jun 02, 2021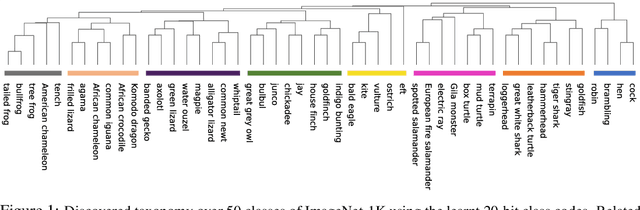

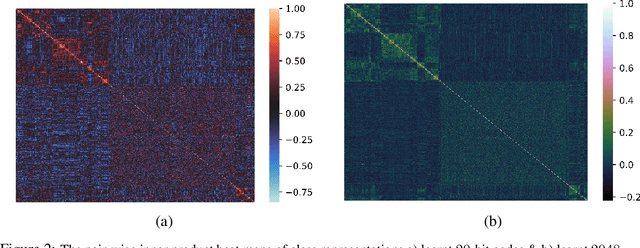

Learning binary representations of instances and classes is a classical problem with several high potential applications. In modern settings, the compression of high-dimensional neural representations to low-dimensional binary codes is a challenging task and often require large bit-codes to be accurate. In this work, we propose a novel method for Learning Low-dimensional binary Codes (LLC) for instances as well as classes. Our method does not require any side-information, like annotated attributes or label meta-data, and learns extremely low-dimensional binary codes (~20 bits for ImageNet-1K). The learnt codes are super-efficient while still ensuring nearly optimal classification accuracy for ResNet50 on ImageNet-1K. We demonstrate that the learnt codes capture intrinsically important features in the data, by discovering an intuitive taxonomy over classes. We further quantitatively measure the quality of our codes by applying it to the efficient image retrieval as well as out-of-distribution (OOD) detection problems. For ImageNet-100 retrieval problem, our learnt binary codes outperform 16 bit HashNet using only 10 bits and also are as accurate as 10 dimensional real representations. Finally, our learnt binary codes can perform OOD detection, out-of-the-box, as accurately as a baseline that needs ~3000 samples to tune its threshold, while we require none. Code and pre-trained models are available at https://github.com/RAIVNLab/LLC.