 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020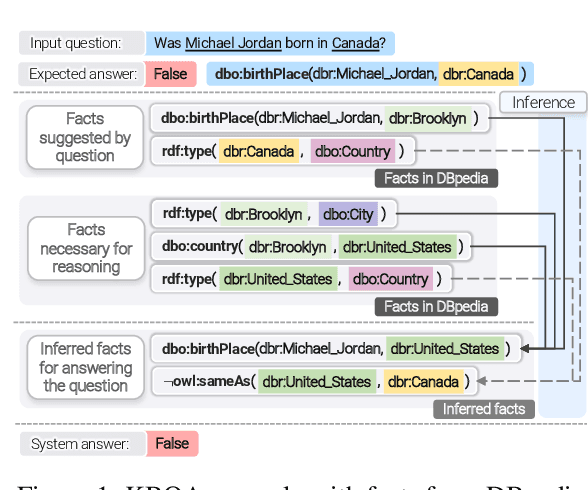
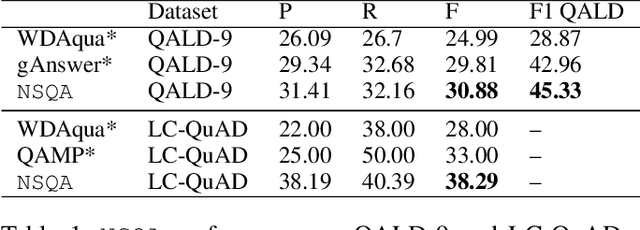
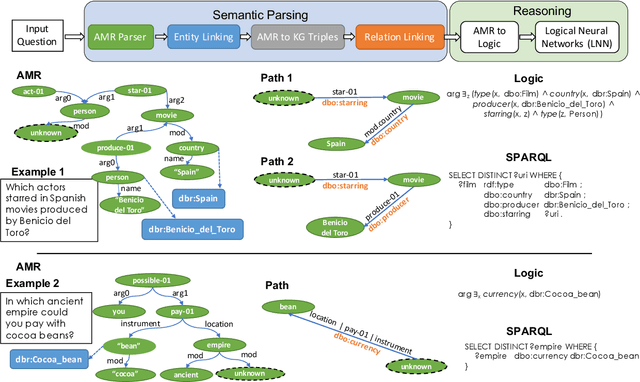

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Leveraging Semantic Parsing for Relation Linking over Knowledge Bases
Sep 16, 2020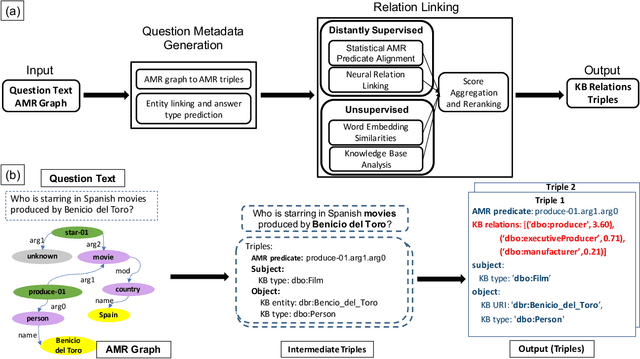

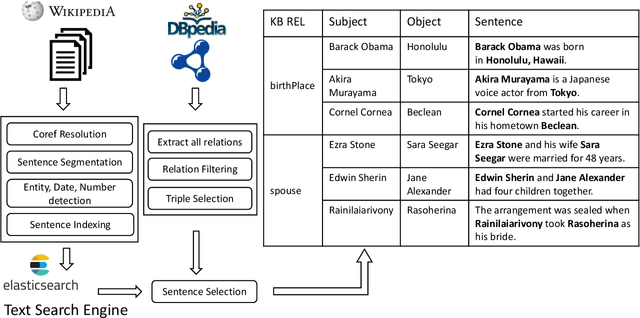
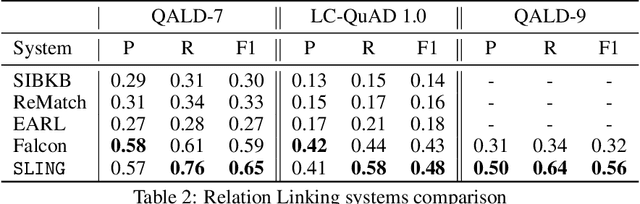
Knowledgebase question answering systems are heavily dependent on relation extraction and linking modules. However, the task of extracting and linking relations from text to knowledgebases faces two primary challenges; the ambiguity of natural language and lack of training data. To overcome these challenges, we present SLING, a relation linking framework which leverages semantic parsing using Abstract Meaning Representation (AMR) and distant supervision. SLING integrates multiple relation linking approaches that capture complementary signals such as linguistic cues, rich semantic representation, and information from the knowledgebase. The experiments on relation linking using three KBQA datasets; QALD-7, QALD-9, and LC-QuAD 1.0 demonstrate that the proposed approach achieves state-of-the-art performance on all benchmarks.
Foundations of Reasoning with Uncertainty via Real-valued Logics
Aug 06, 2020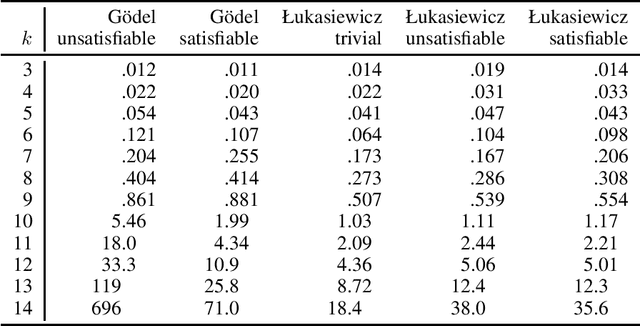
Real-valued logics underlie an increasing number of neuro-symbolic approaches, though typically their logical inference capabilities are characterized only qualitatively. We provide foundations for establishing the correctness and power of such systems. For the first time, we give a sound and complete axiomatization for a broad class containing all the common real-valued logics. This axiomatization allows us to derive exactly what information can be inferred about the combinations of real values of a collection of formulas given information about the combinations of real values of several other collections of formulas. We then extend the axiomatization to deal with weighted subformulas. Finally, we give a decision procedure based on linear programming for deciding, under certain natural assumptions, whether a set of our sentences logically implies another of our sentences.
Logical Neural Networks
Jun 23, 2020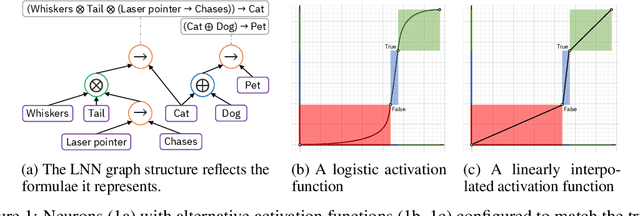

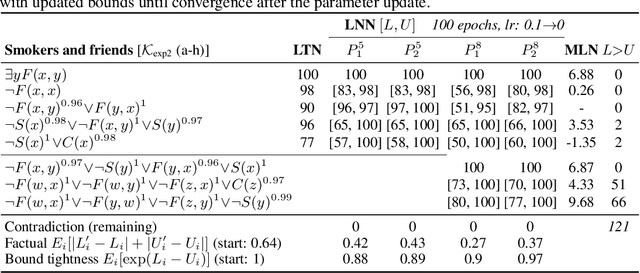
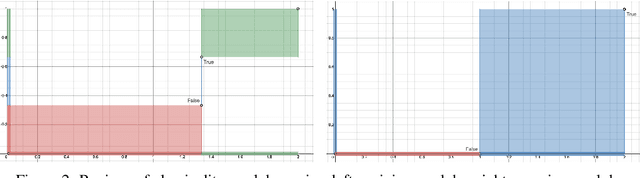
We propose a novel framework seamlessly providing key properties of both neural nets (learning) and symbolic logic (knowledge and reasoning). Every neuron has a meaning as a component of a formula in a weighted real-valued logic, yielding a highly intepretable disentangled representation. Inference is omnidirectional rather than focused on predefined target variables, and corresponds to logical reasoning, including classical first-order logic theorem proving as a special case. The model is end-to-end differentiable, and learning minimizes a novel loss function capturing logical contradiction, yielding resilience to inconsistent knowledge. It also enables the open-world assumption by maintaining bounds on truth values which can have probabilistic semantics, yielding resilience to incomplete knowledge.
AutoAIViz: Opening the Blackbox of Automated Artificial Intelligence with Conditional Parallel Coordinates
Jan 17, 2020
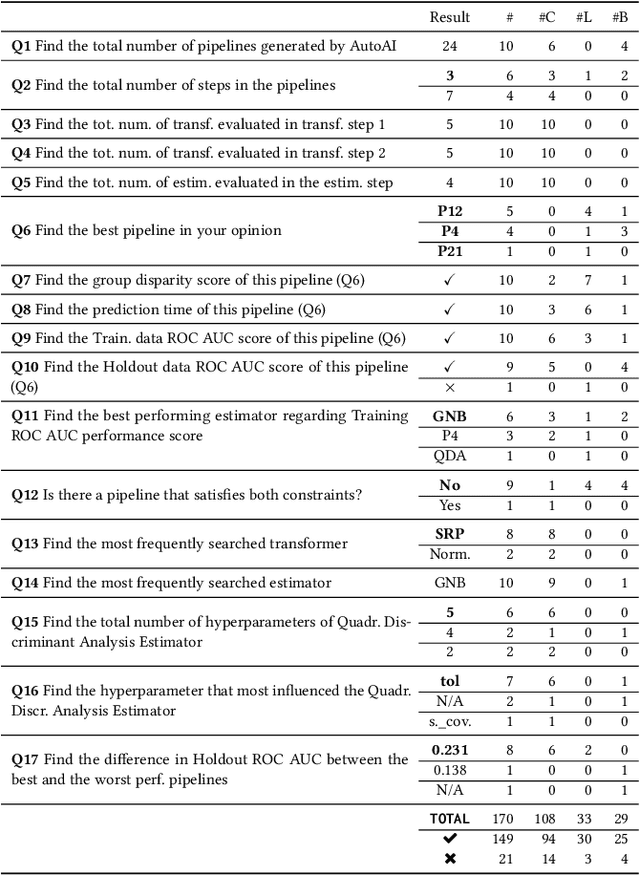
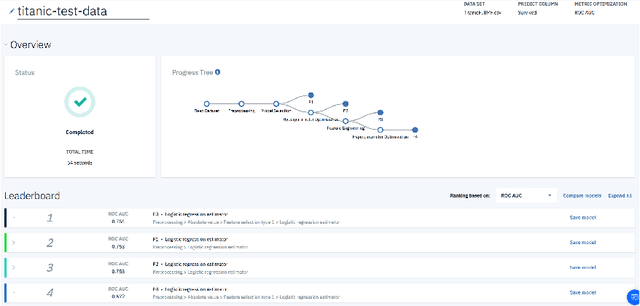
Artificial Intelligence (AI) can now automate the algorithm selection, feature engineering, and hyperparameter tuning steps in a machine learning workflow. Commonly known as AutoML or AutoAI, these technologies aim to relieve data scientists from the tedious manual work. However, today's AutoAI systems often present only limited to no information about the process of how they select and generate model results. Thus, users often do not understand the process, neither do they trust the outputs. In this short paper, we provide a first user evaluation by 10 data scientists of an experimental system, AutoAIViz, that aims to visualize AutoAI's model generation process. We find that the proposed system helps users to complete the data science tasks, and increases their understanding, toward the goal of increasing trust in the AutoAI system.
How can AI Automate End-to-End Data Science?
Oct 22, 2019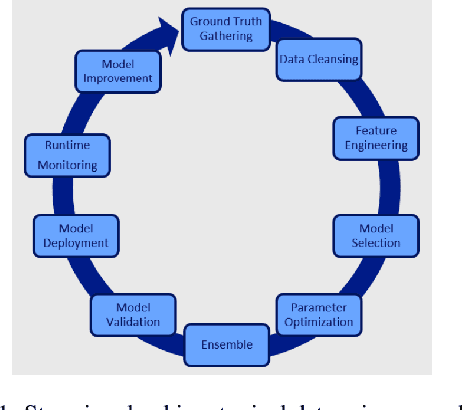
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.
Human-AI Collaboration in Data Science: Exploring Data Scientists' Perceptions of Automated AI
Sep 05, 2019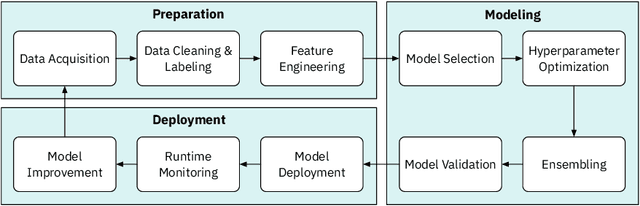
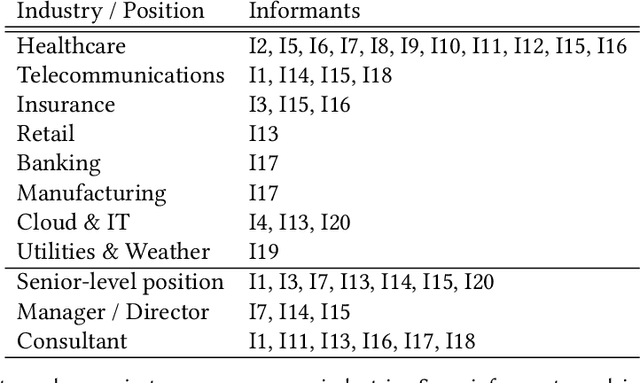
The rapid advancement of artificial intelligence (AI) is changing our lives in many ways. One application domain is data science. New techniques in automating the creation of AI, known as AutoAI or AutoML, aim to automate the work practices of data scientists. AutoAI systems are capable of autonomously ingesting and pre-processing data, engineering new features, and creating and scoring models based on a target objectives (e.g. accuracy or run-time efficiency). Though not yet widely adopted, we are interested in understanding how AutoAI will impact the practice of data science. We conducted interviews with 20 data scientists who work at a large, multinational technology company and practice data science in various business settings. Our goal is to understand their current work practices and how these practices might change with AutoAI. Reactions were mixed: while informants expressed concerns about the trend of automating their jobs, they also strongly felt it was inevitable. Despite these concerns, they remained optimistic about their future job security due to a view that the future of data science work will be a collaboration between humans and AI systems, in which both automation and human expertise are indispensable.
Automated Machine Learning via ADMM
May 01, 2019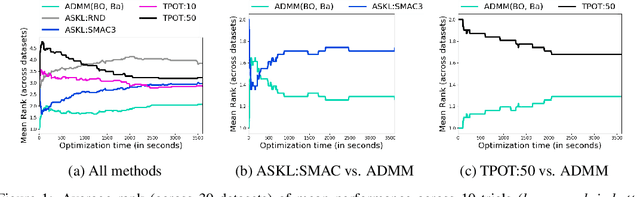
We study the automated machine learning (AutoML) problem of jointly selecting appropriate algorithms from an algorithm portfolio as well as optimizing their hyper-parameters for certain learning tasks. The main challenges include a) the coupling between algorithm selection and hyper-parameter optimization (HPO), and b) the black-box optimization nature of the problem where the optimizer cannot access the gradients of the loss function but may query function values. To circumvent these difficulties, we propose a new AutoML framework by leveraging the alternating direction method of multipliers (ADMM) scheme. Due to the splitting properties of ADMM, algorithm selection and HPO can be decomposed through the augmented Lagrangian function. As a result, HPO with mixed continuous and integer constraints are efficiently handled through a query-efficient Bayesian optimization approach and Euclidean projection operator that yields a closed-form solution. Algorithm selection in ADMM is naturally interpreted as a combinatorial bandit problem. The effectiveness of our proposed methodology is compared to state-of-the-art AutoML schemes such as TPOT and Auto-sklearn on numerous benchmark data sets.
Local Support Vector Machines:Formulation and Analysis
Sep 14, 2013We provide a formulation for Local Support Vector Machines (LSVMs) that generalizes previous formulations, and brings out the explicit connections to local polynomial learning used in nonparametric estimation literature. We investigate the simplest type of LSVMs called Local Linear Support Vector Machines (LLSVMs). For the first time we establish conditions under which LLSVMs make Bayes consistent predictions at each test point $x_0$. We also establish rates at which the local risk of LLSVMs converges to the minimum value of expected local risk at each point $x_0$. Using stability arguments we establish generalization error bounds for LLSVMs.
Stochastic ADMM for Nonsmooth Optimization
Jan 22, 2013We present a stochastic setting for optimization problems with nonsmooth convex separable objective functions over linear equality constraints. To solve such problems, we propose a stochastic Alternating Direction Method of Multipliers (ADMM) algorithm. Our algorithm applies to a more general class of nonsmooth convex functions that does not necessarily have a closed-form solution by minimizing the augmented function directly. We also demonstrate the rates of convergence for our algorithm under various structural assumptions of the stochastic functions: $O(1/\sqrt{t})$ for convex functions and $O(\log t/t)$ for strongly convex functions. Compared to previous literature, we establish the convergence rate of ADMM algorithm, for the first time, in terms of both the objective value and the feasibility violation.