 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Adapter Routing for Data-Efficient Fine-Tuning
Nov 07, 2022Parameter-efficient fine-tuning (PEFT) methods can adapt large language models to downstream tasks by training a small amount of newly added parameters. In multi-task settings, PEFT adapters typically train on each task independently, inhibiting transfer across tasks, or on the concatenation of all tasks, which can lead to negative interference. To address this, Polytropon (Ponti et al.) jointly learns an inventory of PEFT adapters and a routing function to share variable-size sets of adapters across tasks. Subsequently, adapters can be re-combined and fine-tuned on novel tasks even with limited data. In this paper, we investigate to what extent the ability to control which adapters are active for each task leads to sample-efficient generalization. Thus, we propose less expressive variants where we perform weighted averaging of the adapters before few-shot adaptation (Poly-mu) instead of learning a routing function. Moreover, we introduce more expressive variants where finer-grained task-adapter allocation is learned through a multi-head routing function (Poly-S). We test these variants on three separate benchmarks for multi-task learning. We find that Poly-S achieves gains on all three (up to 5.3 points on average) over strong baselines, while incurring a negligible additional cost in parameter count. In particular, we find that instruction tuning, where models are fully fine-tuned on natural language instructions for each task, is inferior to modular methods such as Polytropon and our proposed variants.
Expressiveness and Learnability: A Unifying View for Evaluating Self-Supervised Learning
Jun 02, 2022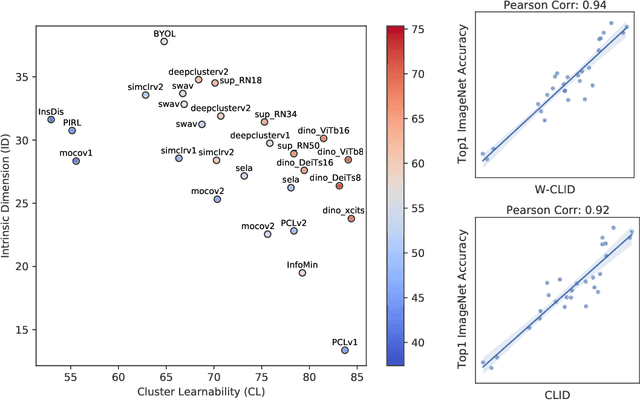
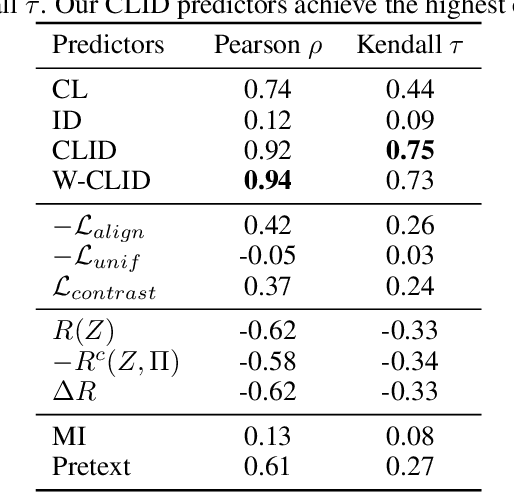
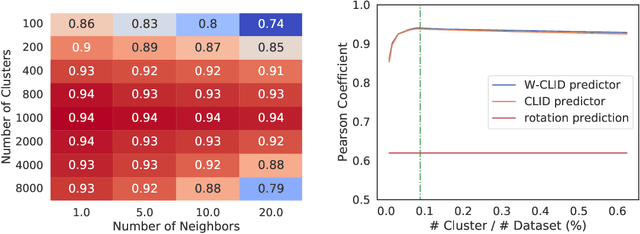
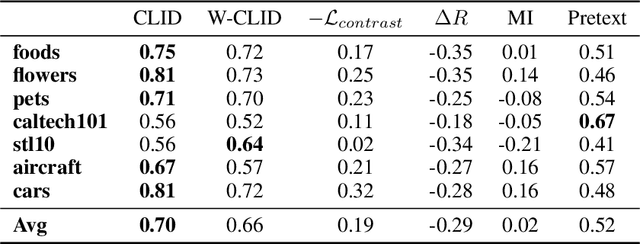
We propose a unifying view to analyze the representation quality of self-supervised learning (SSL) models without access to supervised labels, while being agnostic to the architecture, learning algorithm or data manipulation used during training. We argue that representations can be evaluated through the lens of expressiveness and learnability. We propose to use the Intrinsic Dimension (ID) to assess expressiveness and introduce Cluster Learnability (CL) to assess learnability. CL is measured as the learning speed of a KNN classifier trained to predict labels obtained by clustering the representations with K-means. We thus combine CL and ID into a single predictor: CLID. Through a large-scale empirical study with a diverse family of SSL algorithms, we find that CLID better correlates with in-distribution model performance than other competing recent evaluation schemes. We also benchmark CLID on out-of-domain generalization, where CLID serves as a predictor of the transfer performance of SSL models on several classification tasks, yielding improvements with respect to the competing baselines.
Evaluating Distributional Distortion in Neural Language Modeling
Mar 24, 2022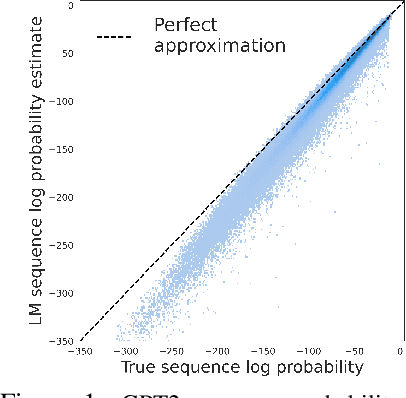


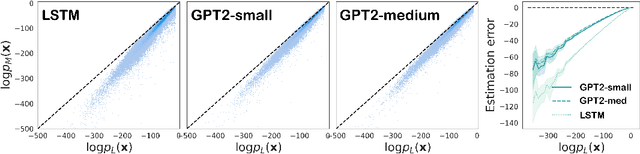
A fundamental characteristic of natural language is the high rate at which speakers produce novel expressions. Because of this novelty, a heavy-tail of rare events accounts for a significant amount of the total probability mass of distributions in language (Baayen, 2001). Standard language modeling metrics such as perplexity quantify the performance of language models (LM) in aggregate. As a result, we have relatively little understanding of whether neural LMs accurately estimate the probability of sequences in this heavy-tail of rare events. To address this gap, we develop a controlled evaluation scheme which uses generative models trained on natural data as artificial languages from which we can exactly compute sequence probabilities. Training LMs on generations from these artificial languages, we compare the sequence-level probability estimates given by LMs to the true probabilities in the target language. Our experiments reveal that LSTM and Transformer language models (i) systematically underestimate the probability of sequences drawn from the target language, and (ii) do so more severely for less-probable sequences. Investigating where this probability mass went, (iii) we find that LMs tend to overestimate the probability of ill formed (perturbed) sequences. In addition, we find that this underestimation behaviour (iv) is weakened, but not eliminated by greater amounts of training data, and (v) is exacerbated for target distributions with lower entropy.
Better Language Model with Hypernym Class Prediction
Mar 21, 2022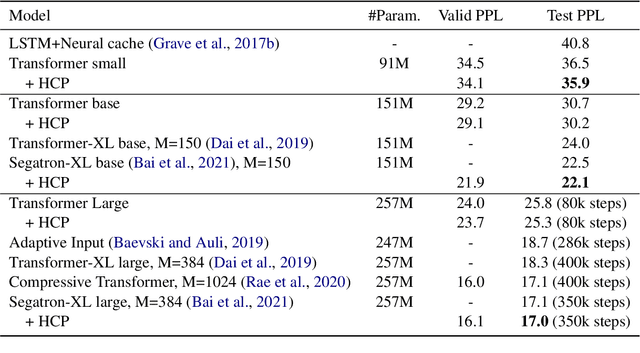
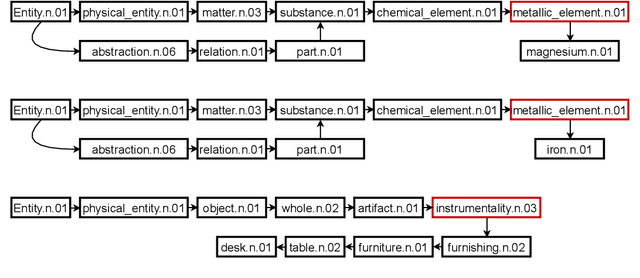
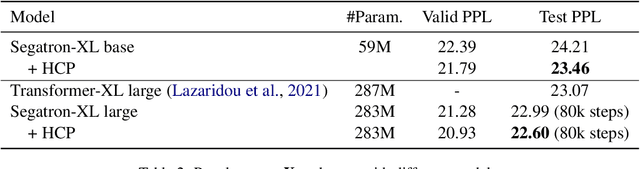
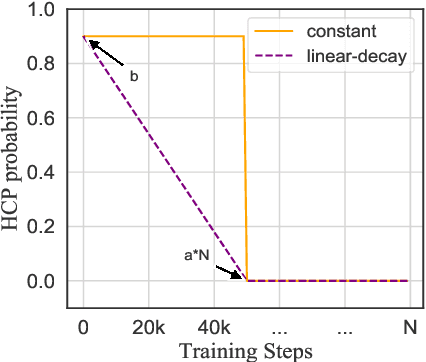
Class-based language models (LMs) have been long devised to address context sparsity in $n$-gram LMs. In this study, we revisit this approach in the context of neural LMs. We hypothesize that class-based prediction leads to an implicit context aggregation for similar words and thus can improve generalization for rare words. We map words that have a common WordNet hypernym to the same class and train large neural LMs by gradually annealing from predicting the class to token prediction during training. Empirically, this curriculum learning strategy consistently improves perplexity over various large, highly-performant state-of-the-art Transformer-based models on two datasets, WikiText-103 and Arxiv. Our analysis shows that the performance improvement is achieved without sacrificing performance on rare words. Finally, we document other attempts that failed to yield empirical gains, and discuss future directions for the adoption of class-based LMs on a larger scale.
Combining Modular Skills in Multitask Learning
Mar 01, 2022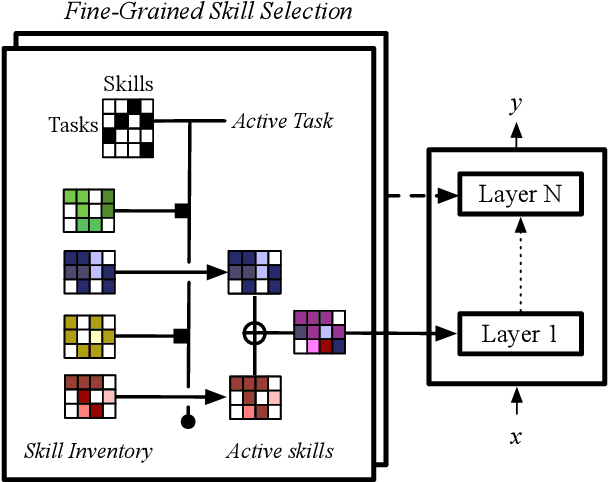
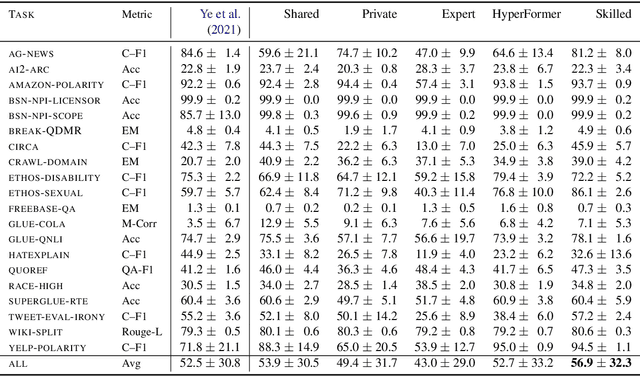
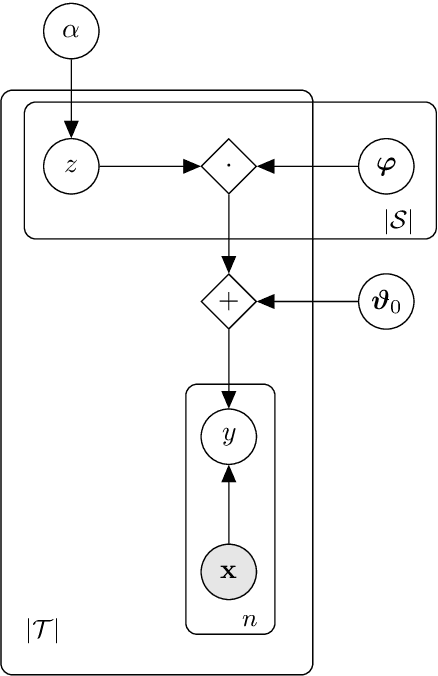
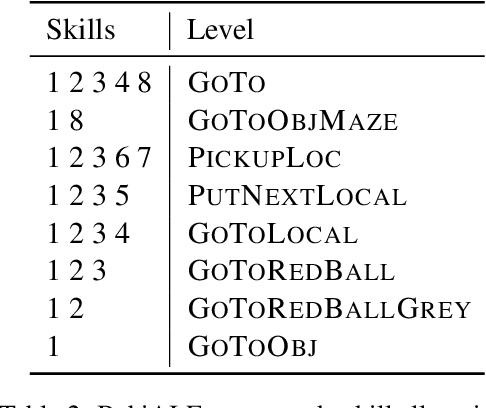
A modular design encourages neural models to disentangle and recombine different facets of knowledge to generalise more systematically to new tasks. In this work, we assume that each task is associated with a subset of latent discrete skills from a (potentially small) inventory. In turn, skills correspond to parameter-efficient (sparse / low-rank) model parameterisations. By jointly learning these and a task-skill allocation matrix, the network for each task is instantiated as the average of the parameters of active skills. To favour non-trivial soft partitions of skills across tasks, we experiment with a series of inductive biases, such as an Indian Buffet Process prior and a two-speed learning rate. We evaluate our latent-skill model on two main settings: 1) multitask reinforcement learning for grounded instruction following on 8 levels of the BabyAI platform; and 2) few-shot adaptation of pre-trained text-to-text generative models on CrossFit, a benchmark comprising 160 NLP tasks. We find that the modular design of a network significantly increases sample efficiency in reinforcement learning and few-shot generalisation in supervised learning, compared to baselines with fully shared, task-specific, or conditionally generated parameters where knowledge is entangled across tasks. In addition, we show how discrete skills help interpretability, as they yield an explicit hierarchy of tasks.
Does Pre-training Induce Systematic Inference? How Masked Language Models Acquire Commonsense Knowledge
Dec 16, 2021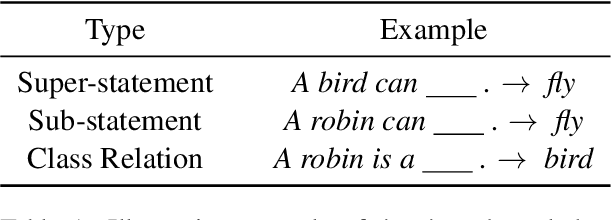
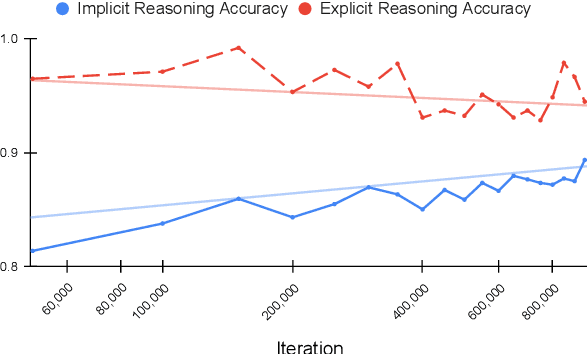
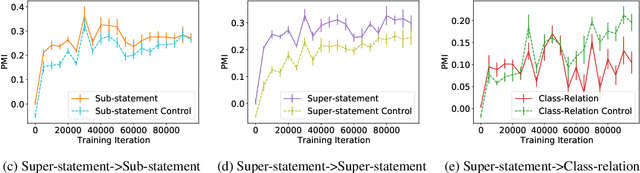
Transformer models pre-trained with a masked-language-modeling objective (e.g., BERT) encode commonsense knowledge as evidenced by behavioral probes; however, the extent to which this knowledge is acquired by systematic inference over the semantics of the pre-training corpora is an open question. To answer this question, we selectively inject verbalized knowledge into the minibatches of a BERT model during pre-training and evaluate how well the model generalizes to supported inferences. We find generalization does not improve over the course of pre-training, suggesting that commonsense knowledge is acquired from surface-level, co-occurrence patterns rather than induced, systematic reasoning.
Self-training with Few-shot Rationalization: Teacher Explanations Aid Student in Few-shot NLU
Sep 17, 2021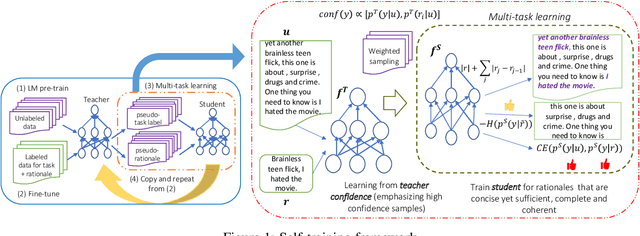
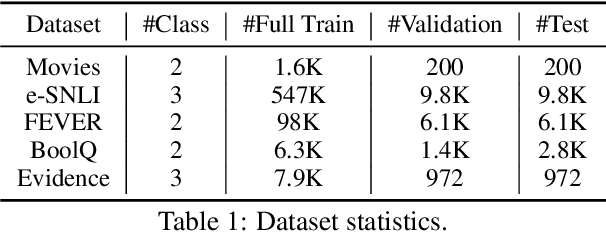
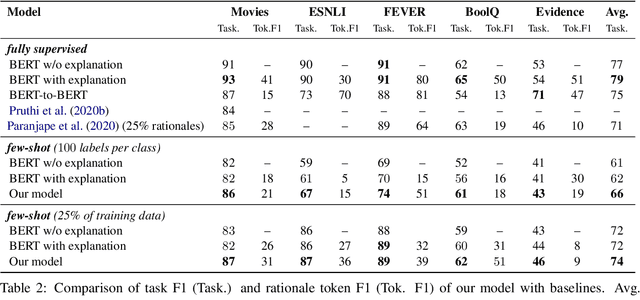

While pre-trained language models have obtained state-of-the-art performance for several natural language understanding tasks, they are quite opaque in terms of their decision-making process. While some recent works focus on rationalizing neural predictions by highlighting salient concepts in the text as justifications or rationales, they rely on thousands of labeled training examples for both task labels as well as an-notated rationales for every instance. Such extensive large-scale annotations are infeasible to obtain for many tasks. To this end, we develop a multi-task teacher-student framework based on self-training language models with limited task-specific labels and rationales, and judicious sample selection to learn from informative pseudo-labeled examples1. We study several characteristics of what constitutes a good rationale and demonstrate that the neural model performance can be significantly improved by making it aware of its rationalized predictions, particularly in low-resource settings. Extensive experiments in several bench-mark datasets demonstrate the effectiveness of our approach.
The Emergence of the Shape Bias Results from Communicative Efficiency
Sep 15, 2021
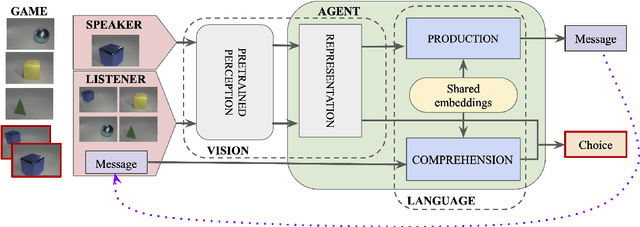
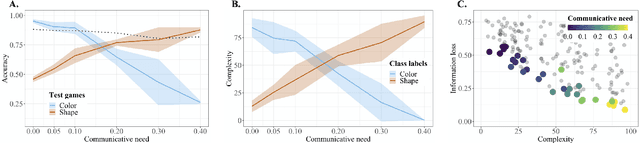
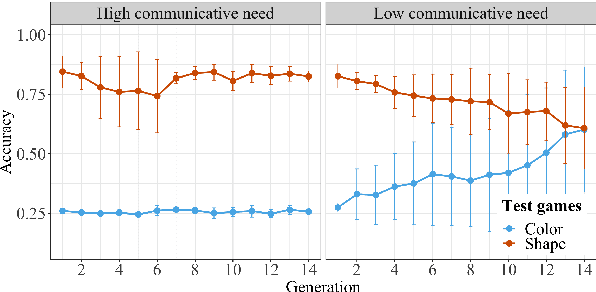
By the age of two, children tend to assume that new word categories are based on objects' shape, rather than their color or texture; this assumption is called the shape bias. They are thought to learn this bias by observing that their caregiver's language is biased towards shape based categories. This presents a chicken and egg problem: if the shape bias must be present in the language in order for children to learn it, how did it arise in language in the first place? In this paper, we propose that communicative efficiency explains both how the shape bias emerged and why it persists across generations. We model this process with neural emergent language agents that learn to communicate about raw pixelated images. First, we show that the shape bias emerges as a result of efficient communication strategies employed by agents. Second, we show that pressure brought on by communicative need is also necessary for it to persist across generations; simply having a shape bias in an agent's input language is insufficient. These results suggest that, over and above the operation of other learning strategies, the shape bias in human learners may emerge and be sustained by communicative pressures.
Decomposed Mutual Information Estimation for Contrastive Representation Learning
Jun 25, 2021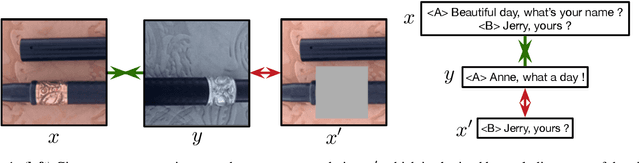

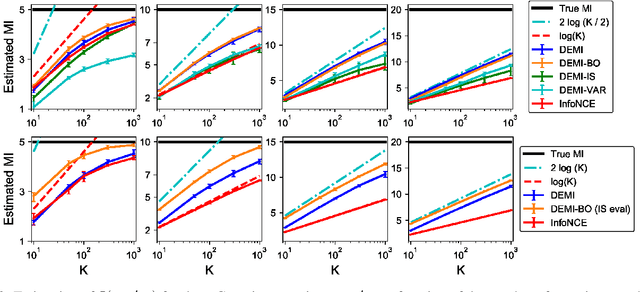
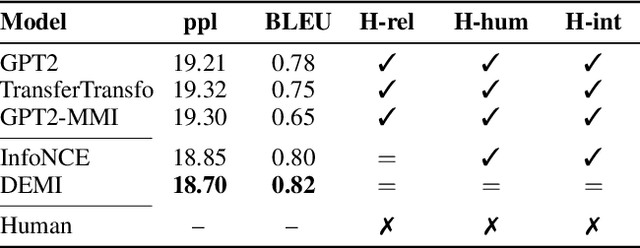
Recent contrastive representation learning methods rely on estimating mutual information (MI) between multiple views of an underlying context. E.g., we can derive multiple views of a given image by applying data augmentation, or we can split a sequence into views comprising the past and future of some step in the sequence. Contrastive lower bounds on MI are easy to optimize, but have a strong underestimation bias when estimating large amounts of MI. We propose decomposing the full MI estimation problem into a sum of smaller estimation problems by splitting one of the views into progressively more informed subviews and by applying the chain rule on MI between the decomposed views. This expression contains a sum of unconditional and conditional MI terms, each measuring modest chunks of the total MI, which facilitates approximation via contrastive bounds. To maximize the sum, we formulate a contrastive lower bound on the conditional MI which can be approximated efficiently. We refer to our general approach as Decomposed Estimation of Mutual Information (DEMI). We show that DEMI can capture a larger amount of MI than standard non-decomposed contrastive bounds in a synthetic setting, and learns better representations in a vision domain and for dialogue generation.
Understanding by Understanding Not: Modeling Negation in Language Models
May 07, 2021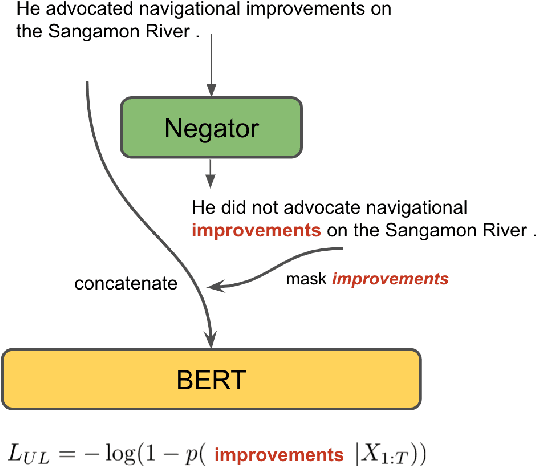



Negation is a core construction in natural language. Despite being very successful on many tasks, state-of-the-art pre-trained language models often handle negation incorrectly. To improve language models in this regard, we propose to augment the language modeling objective with an unlikelihood objective that is based on negated generic sentences from a raw text corpus. By training BERT with the resulting combined objective we reduce the mean top~1 error rate to 4% on the negated LAMA dataset. We also see some improvements on the negated NLI benchmarks.