 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Theory of Reinforcement Learning with Once-per-Episode Feedback
Jun 07, 2021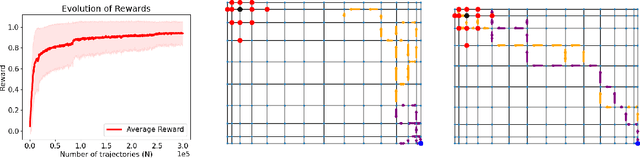
We study a theory of reinforcement learning (RL) in which the learner receives binary feedback only once at the end of an episode. While this is an extreme test case for theory, it is also arguably more representative of real-world applications than the traditional requirement in RL practice that the learner receive feedback at every time step. Indeed, in many real-world applications of reinforcement learning, such as self-driving cars and robotics, it is easier to evaluate whether a learner's complete trajectory was either "good" or "bad," but harder to provide a reward signal at each step. To show that learning is possible in this more challenging setting, we study the case where trajectory labels are generated by an unknown parametric model, and provide a statistically and computationally efficient algorithm that achieves sub-linear regret.
Parallelizing Contextual Linear Bandits
May 21, 2021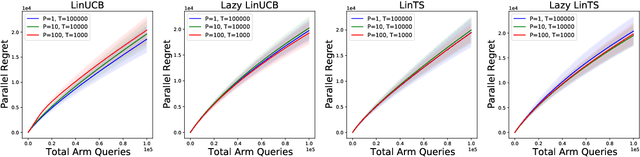
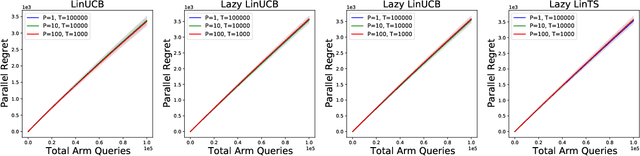

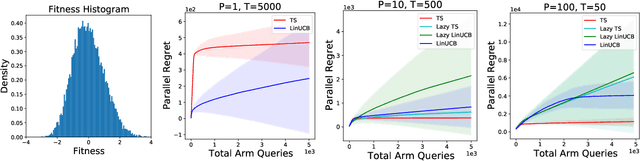
Standard approaches to decision-making under uncertainty focus on sequential exploration of the space of decisions. However, \textit{simultaneously} proposing a batch of decisions, which leverages available resources for parallel experimentation, has the potential to rapidly accelerate exploration. We present a family of (parallel) contextual linear bandit algorithms, whose regret is nearly identical to their perfectly sequential counterparts -- given access to the same total number of oracle queries -- up to a lower-order "burn-in" term that is dependent on the context-set geometry. We provide matching information-theoretic lower bounds on parallel regret performance to establish our algorithms are asymptotically optimal in the time horizon. Finally, we also present an empirical evaluation of these parallel algorithms in several domains, including materials discovery and biological sequence design problems, to demonstrate the utility of parallelized bandits in practical settings.
Near Optimal Policy Optimization via REPS
Mar 17, 2021Since its introduction a decade ago, \emph{relative entropy policy search} (REPS) has demonstrated successful policy learning on a number of simulated and real-world robotic domains, not to mention providing algorithmic components used by many recently proposed reinforcement learning (RL) algorithms. While REPS is commonly known in the community, there exist no guarantees on its performance when using stochastic and gradient-based solvers. In this paper we aim to fill this gap by providing guarantees and convergence rates for the sub-optimality of a policy learned using first-order optimization methods applied to the REPS objective. We first consider the setting in which we are given access to exact gradients and demonstrate how near-optimality of the objective translates to near-optimality of the policy. We then consider the practical setting of stochastic gradients, and introduce a technique that uses \emph{generative} access to the underlying Markov decision process to compute parameter updates that maintain favorable convergence to the optimal regularized policy.
Unlocking Pixels for Reinforcement Learning via Implicit Attention
Mar 04, 2021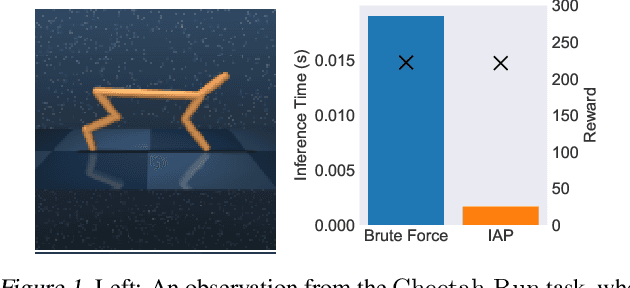
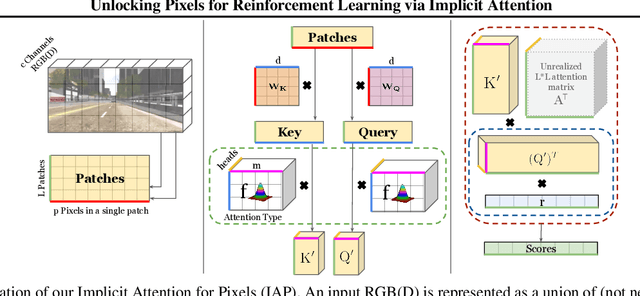

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.
Deep Reinforcement Learning with Dynamic Optimism
Feb 09, 2021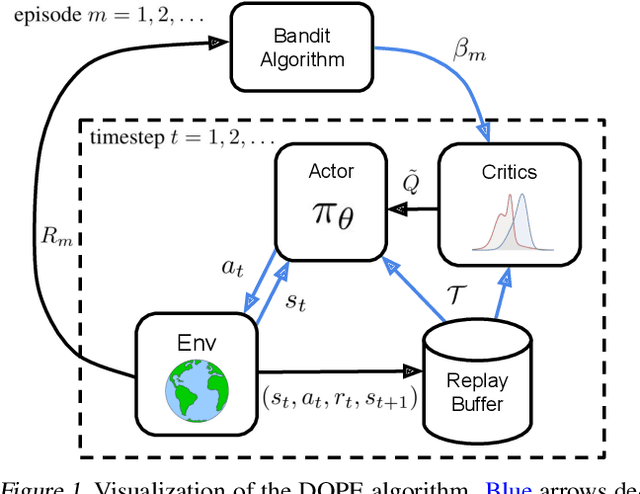
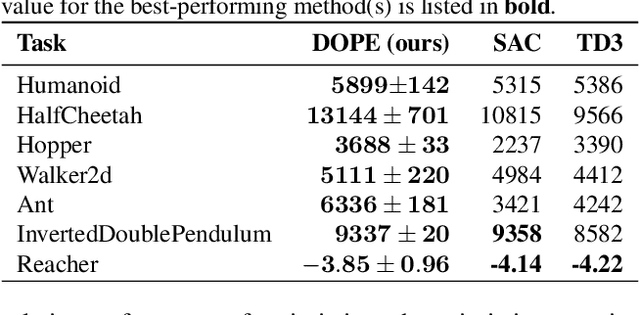
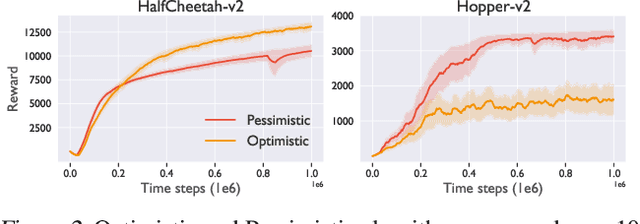
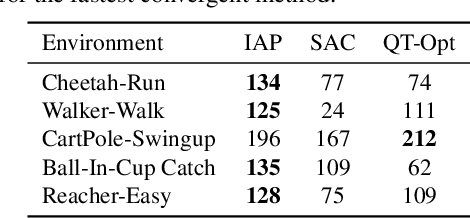
In recent years, deep off-policy actor-critic algorithms have become a dominant approach to reinforcement learning for continuous control. This comes after a series of breakthroughs to address function approximation errors, which previously led to poor performance. These insights encourage the use of pessimistic value updates. However, this discourages exploration and runs counter to theoretical support for the efficacy of optimism in the face of uncertainty. So which approach is best? In this work, we show that the optimal degree of optimism can vary both across tasks and over the course of learning. Inspired by this insight, we introduce a novel deep actor-critic algorithm, Dynamic Optimistic and Pessimistic Estimation (DOPE) to switch between optimistic and pessimistic value learning online by formulating the selection as a multi-arm bandit problem. We show in a series of challenging continuous control tasks that DOPE outperforms existing state-of-the-art methods, which rely on a fixed degree of optimism. Since our changes are simple to implement, we believe these insights can be extended to a number of off-policy algorithms.
ES-ENAS: Combining Evolution Strategies with Neural Architecture Search at No Extra Cost for Reinforcement Learning
Jan 19, 2021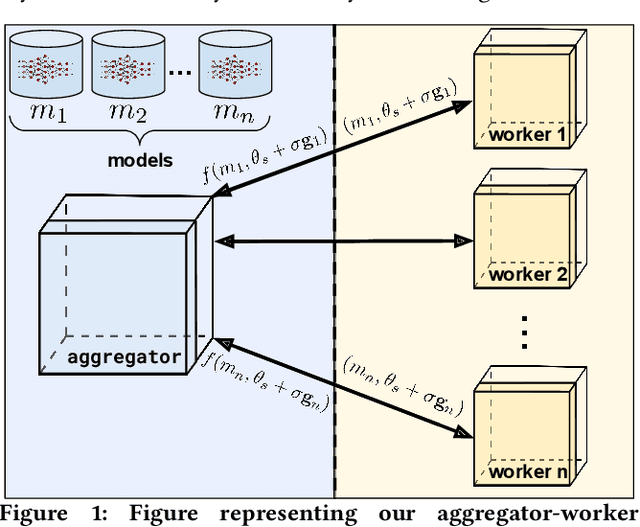

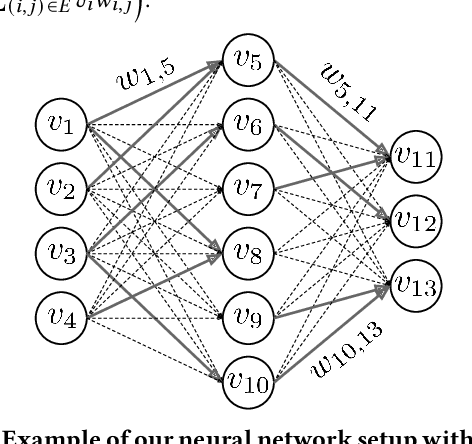
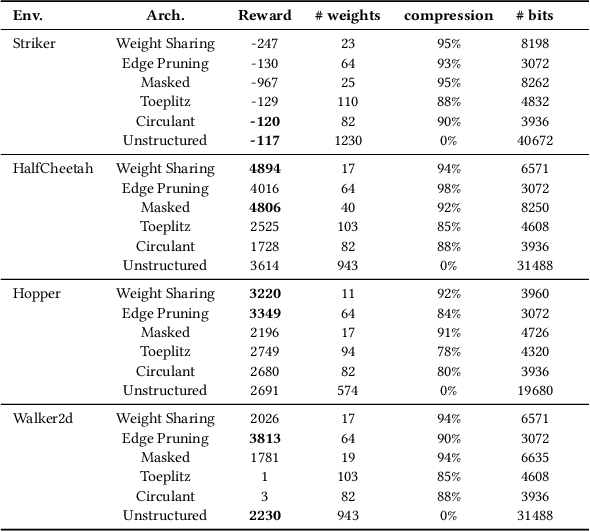
We introduce ES-ENAS, a simple neural architecture search (NAS) algorithm for the purpose of reinforcement learning (RL) policy design, by combining Evolutionary Strategies (ES) and Efficient NAS (ENAS) in a highly scalable and intuitive way. Our main insight is noticing that ES is already a distributed blackbox algorithm, and thus we may simply insert a model controller from ENAS into the central aggregator in ES and obtain weight sharing properties for free. By doing so, we bridge the gap from NAS research in supervised learning settings to the reinforcement learning scenario through this relatively simple marriage between two different lines of research, and are one of the first to apply controller-based NAS techniques to RL. We demonstrate the utility of our method by training combinatorial neural network architectures for RL problems in continuous control, via edge pruning and weight sharing. We also incorporate a wide variety of popular techniques from modern NAS literature, including multiobjective optimization and varying controller methods, to showcase their promise in the RL field and discuss possible extensions. We achieve >90% network compression for multiple tasks, which may be special interest in mobile robotics with limited storage and computational resources.
Fairness with Continuous Optimal Transport
Jan 06, 2021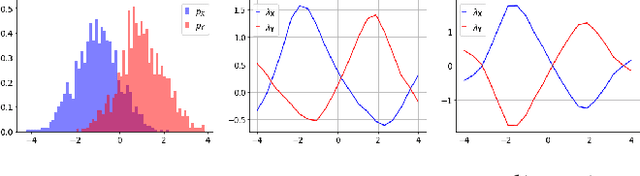

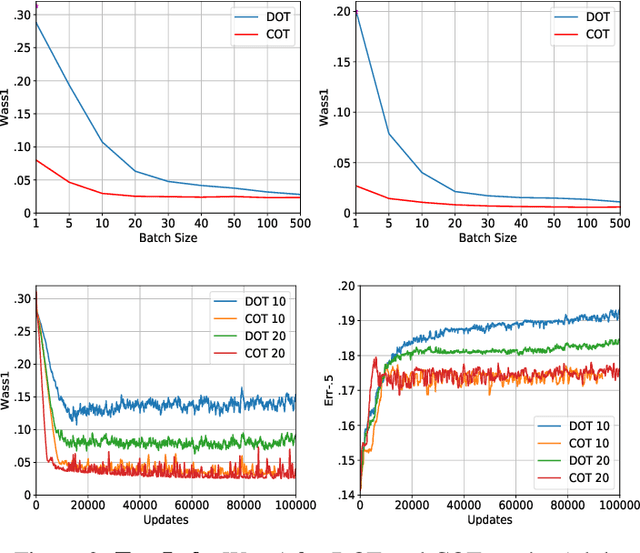
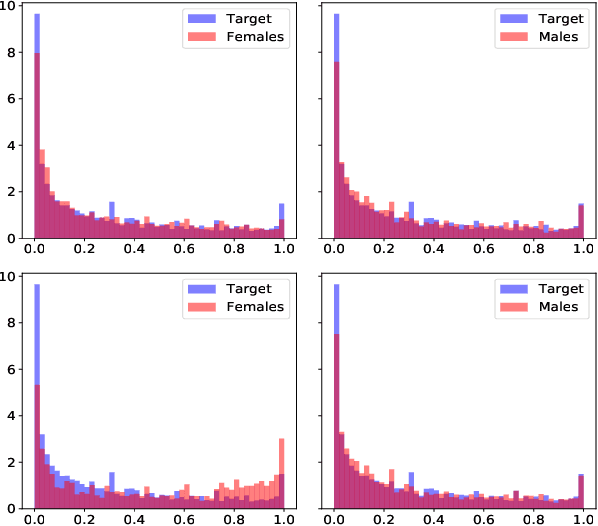
Whilst optimal transport (OT) is increasingly being recognized as a powerful and flexible approach for dealing with fairness issues, current OT fairness methods are confined to the use of discrete OT. In this paper, we leverage recent advances from the OT literature to introduce a stochastic-gradient fairness method based on a dual formulation of continuous OT. We show that this method gives superior performance to discrete OT methods when little data is available to solve the OT problem, and similar performance otherwise. We also show that both continuous and discrete OT methods are able to continually adjust the model parameters to adapt to different levels of unfairness that might occur in real-world applications of ML systems.
Regret Bound Balancing and Elimination for Model Selection in Bandits and RL
Dec 24, 2020

We propose a simple model selection approach for algorithms in stochastic bandit and reinforcement learning problems. As opposed to prior work that (implicitly) assumes knowledge of the optimal regret, we only require that each base algorithm comes with a candidate regret bound that may or may not hold during all rounds. In each round, our approach plays a base algorithm to keep the candidate regret bounds of all remaining base algorithms balanced, and eliminates algorithms that violate their candidate bound. We prove that the total regret of this approach is bounded by the best valid candidate regret bound times a multiplicative factor. This factor is reasonably small in several applications, including linear bandits and MDPs with nested function classes, linear bandits with unknown misspecification, and LinUCB applied to linear bandits with different confidence parameters. We further show that, under a suitable gap-assumption, this factor only scales with the number of base algorithms and not their complexity when the number of rounds is large enough. Finally, unlike recent efforts in model selection for linear stochastic bandits, our approach is versatile enough to also cover cases where the context information is generated by an adversarial environment, rather than a stochastic one.
Online Model Selection for Reinforcement Learning with Function Approximation
Nov 19, 2020
Deep reinforcement learning has achieved impressive successes yet often requires a very large amount of interaction data. This result is perhaps unsurprising, as using complicated function approximation often requires more data to fit, and early theoretical results on linear Markov decision processes provide regret bounds that scale with the dimension of the linear approximation. Ideally, we would like to automatically identify the minimal dimension of the approximation that is sufficient to encode an optimal policy. Towards this end, we consider the problem of model selection in RL with function approximation, given a set of candidate RL algorithms with known regret guarantees. The learner's goal is to adapt to the complexity of the optimal algorithm without knowing it \textit{a priori}. We present a meta-algorithm that successively rejects increasingly complex models using a simple statistical test. Given at least one candidate that satisfies realizability, we prove the meta-algorithm adapts to the optimal complexity with $\tilde{O}(L^{5/6} T^{2/3})$ regret compared to the optimal candidate's $\tilde{O}(\sqrt T)$ regret, where $T$ is the number of episodes and $L$ is the number of algorithms. The dimension and horizon dependencies remain optimal with respect to the best candidate, and our meta-algorithmic approach is flexible to incorporate multiple candidate algorithms and models. Finally, we show that the meta-algorithm automatically admits significantly improved instance-dependent regret bounds that depend on the gaps between the maximal values attainable by the candidates.
Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian
Nov 12, 2020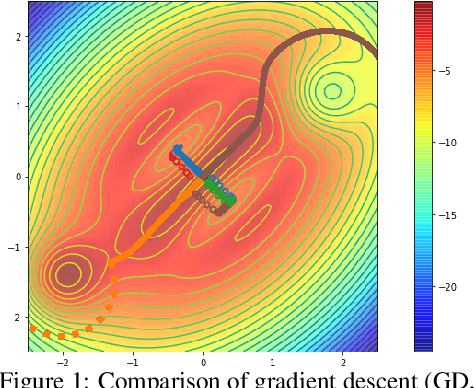
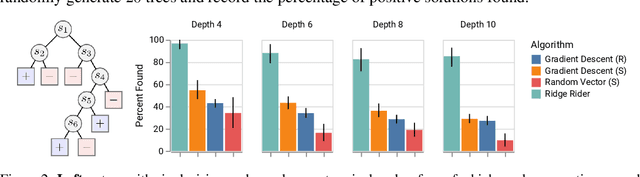
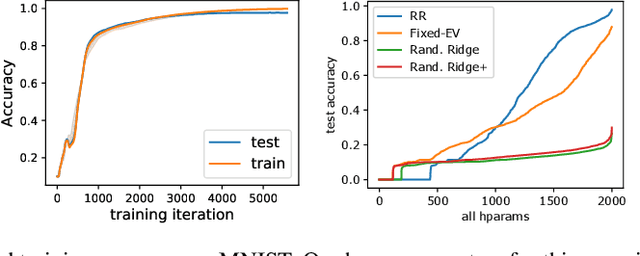
Over the last decade, a single algorithm has changed many facets of our lives - Stochastic Gradient Descent (SGD). In the era of ever decreasing loss functions, SGD and its various offspring have become the go-to optimization tool in machine learning and are a key component of the success of deep neural networks (DNNs). While SGD is guaranteed to converge to a local optimum (under loose assumptions), in some cases it may matter which local optimum is found, and this is often context-dependent. Examples frequently arise in machine learning, from shape-versus-texture-features to ensemble methods and zero-shot coordination. In these settings, there are desired solutions which SGD on 'standard' loss functions will not find, since it instead converges to the 'easy' solutions. In this paper, we present a different approach. Rather than following the gradient, which corresponds to a locally greedy direction, we instead follow the eigenvectors of the Hessian, which we call "ridges". By iteratively following and branching amongst the ridges, we effectively span the loss surface to find qualitatively different solutions. We show both theoretically and experimentally that our method, called Ridge Rider (RR), offers a promising direction for a variety of challenging problems.