 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation
Feb 04, 2021
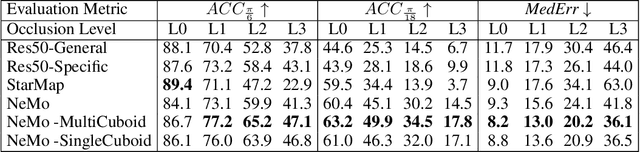
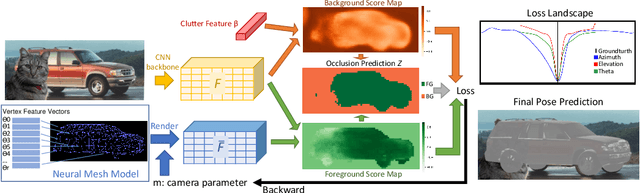

3D pose estimation is a challenging but important task in computer vision. In this work, we show that standard deep learning approaches to 3D pose estimation are not robust when objects are partially occluded or viewed from a previously unseen pose. Inspired by the robustness of generative vision models to partial occlusion, we propose to integrate deep neural networks with 3D generative representations of objects into a unified neural architecture that we term NeMo. In particular, NeMo learns a generative model of neural feature activations at each vertex on a dense 3D mesh. Using differentiable rendering we estimate the 3D object pose by minimizing the reconstruction error between NeMo and the feature representation of the target image. To avoid local optima in the reconstruction loss, we train the feature extractor to maximize the distance between the individual feature representations on the mesh using contrastive learning. Our extensive experiments on PASCAL3D+, occluded-PASCAL3D+ and ObjectNet3D show that NeMo is much more robust to partial occlusion and unseen pose compared to standard deep networks, while retaining competitive performance on regular data. Interestingly, our experiments also show that NeMo performs reasonably well even when the mesh representation only crudely approximates the true object geometry with a cuboid, hence revealing that the detailed 3D geometry is not needed for accurate 3D pose estimation. The code is publicly available at https://github.com/Angtian/NeMo.
COMPAS: Representation Learning with Compositional Part Sharing for Few-Shot Classification
Jan 28, 2021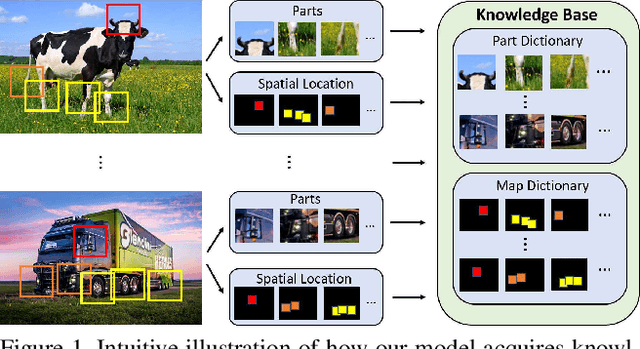
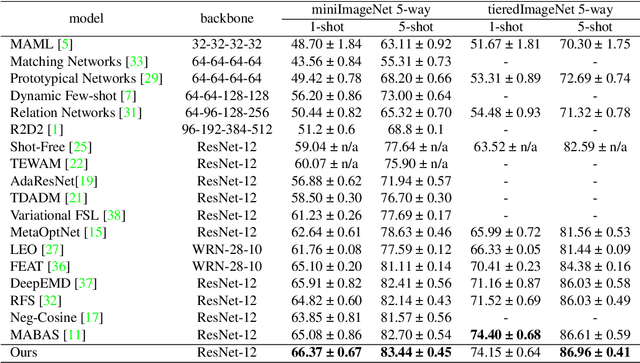
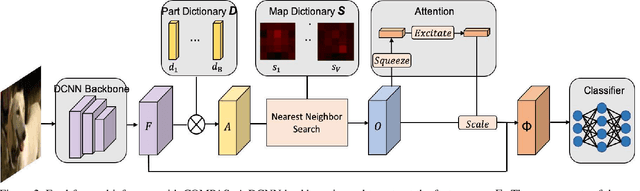
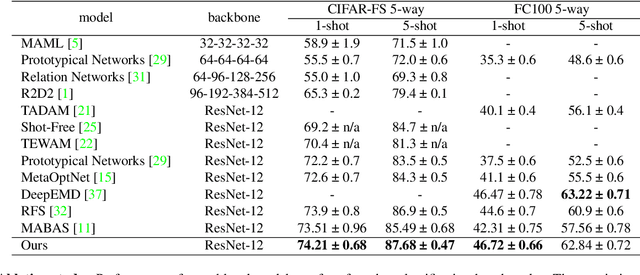
Few-shot image classification consists of two consecutive learning processes: 1) In the meta-learning stage, the model acquires a knowledge base from a set of training classes. 2) During meta-testing, the acquired knowledge is used to recognize unseen classes from very few examples. Inspired by the compositional representation of objects in humans, we train a neural network architecture that explicitly represents objects as a set of parts and their spatial composition. In particular, during meta-learning, we train a knowledge base that consists of a dictionary of part representations and a dictionary of part activation maps that encode frequent spatial activation patterns of parts. The elements of both dictionaries are shared among the training classes. During meta-testing, the representation of unseen classes is learned using the part representations and the part activation maps from the knowledge base. Finally, an attention mechanism is used to strengthen those parts that are most important for each category. We demonstrate the value of our compositional learning framework for a few-shot classification using miniImageNet, tieredImageNet, CIFAR-FS, and FC100, where we achieve state-of-the-art performance.
Meticulous Object Segmentation
Dec 13, 2020Compared with common image segmentation tasks targeted at low-resolution images, higher resolution detailed image segmentation receives much less attention. In this paper, we propose and study a task named Meticulous Object Segmentation (MOS), which is focused on segmenting well-defined foreground objects with elaborate shapes in high resolution images (e.g. 2k - 4k). To this end, we propose the MeticulousNet which leverages a dedicated decoder to capture the object boundary details. Specifically, we design a Hierarchical Point-wise Refining (HierPR) block to better delineate object boundaries, and reformulate the decoding process as a recursive coarse to fine refinement of the object mask. To evaluate segmentation quality near object boundaries, we propose the Meticulosity Quality (MQ) score considering both the mask coverage and boundary precision. In addition, we collect a MOS benchmark dataset including 600 high quality images with complex objects. We provide comprehensive empirical evidence showing that MeticulousNet can reveal pixel-accurate segmentation boundaries and is superior to state-of-the-art methods for high resolution object segmentation tasks.
Mask Guided Matting via Progressive Refinement Network
Dec 12, 2020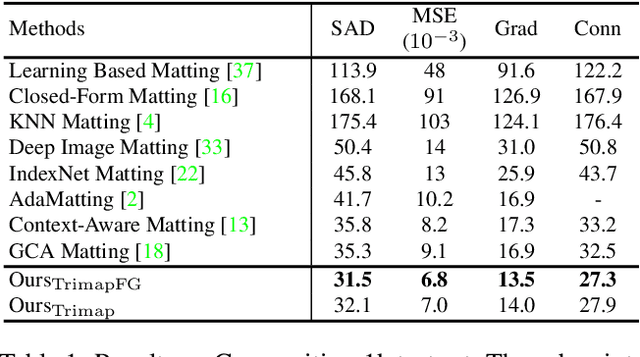
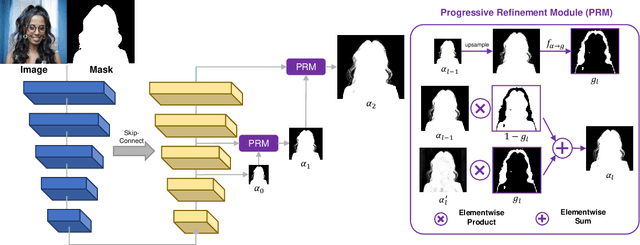
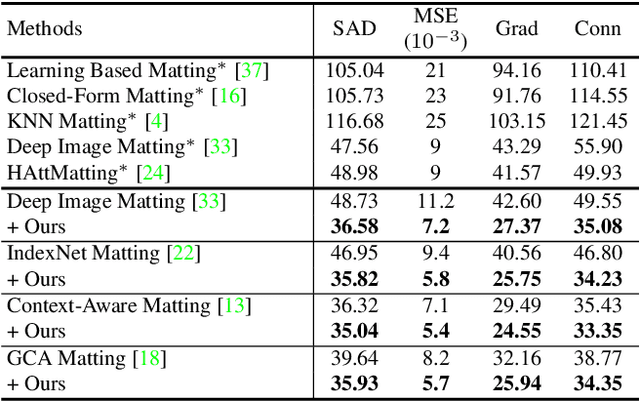

We propose Mask Guided (MG) Matting, a robust matting framework that takes a general coarse mask as guidance. MG Matting leverages a network (PRN) design which encourages the matting model to provide self-guidance to progressively refine the uncertain regions through the decoding process. A series of guidance mask perturbation operations are also introduced in the training to further enhance its robustness to external guidance. We show that PRN can generalize to unseen types of guidance masks such as trimap and low-quality alpha matte, making it suitable for various application pipelines. In addition, we revisit the foreground color prediction problem for matting and propose a surprisingly simple improvement to address the dataset issue. Evaluation on real and synthetic benchmarks shows that MG Matting achieves state-of-the-art performance using various types of guidance inputs. Code and models will be available at https://github.com/yucornetto/MGMatting
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
Dec 09, 2020
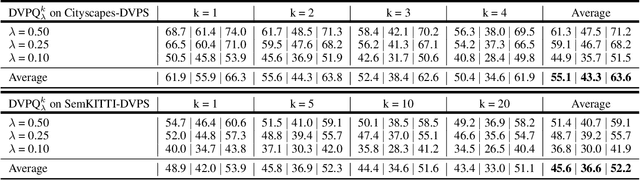
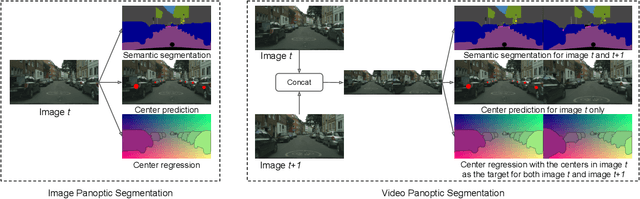
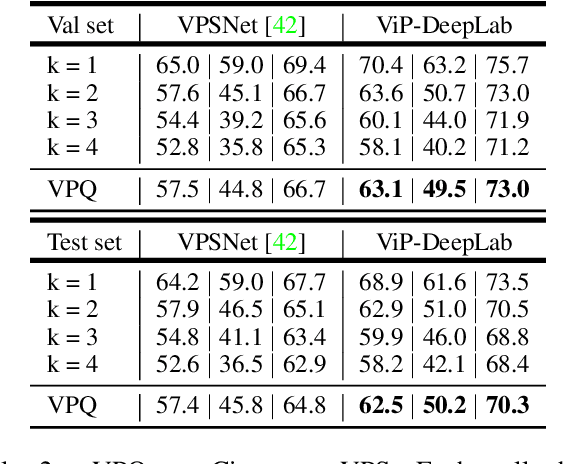
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
Robust Instance Segmentation through Reasoning about Multi-Object Occlusion
Dec 03, 2020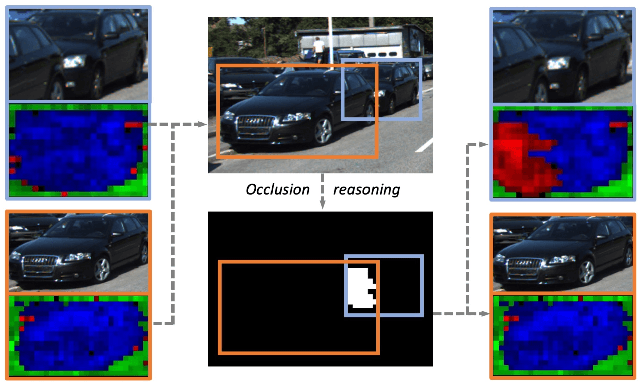
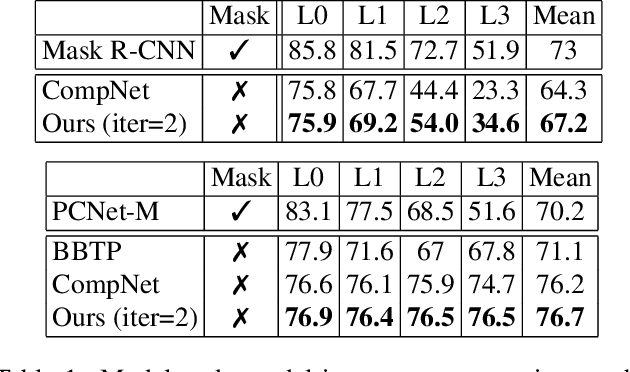
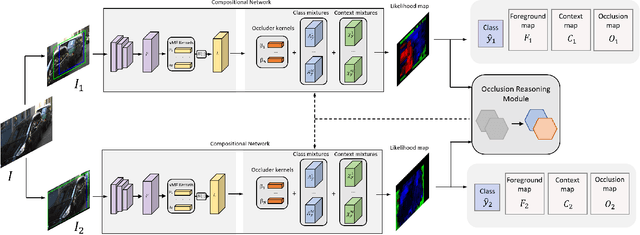
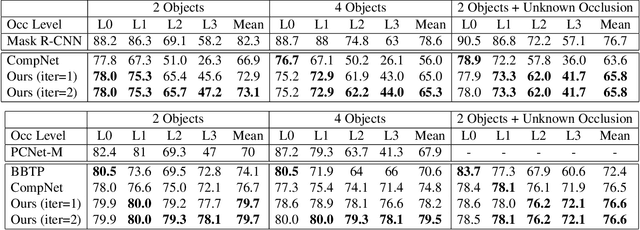
Analyzing complex scenes with Deep Neural Networks is a challenging task, particularly when images contain multiple objects that partially occlude each other. Existing approaches to image analysis mostly process objects independently and do not take into account the relative occlusion of nearby objects. In this paper, we propose a deep network for multi-object instance segmentation that is robust to occlusion and can be trained from bounding box supervision only. Our work builds on Compositional Networks, which learn a generative model of neural feature activations to locate occluders and to classify objects based on their non-occluded parts. We extend their generative model to include multiple objects and introduce a framework for the efficient inference in challenging occlusion scenarios. In particular, we obtain feed-forward predictions of the object classes and their instance and occluder segmentations. We introduce an Occlusion Reasoning Module (ORM) that locates erroneous segmentations and estimates the occlusion ordering to correct them. The improved segmentation masks are, in turn, integrated into the network in a top-down manner to improve the image classification. Our experiments on the KITTI INStance dataset (KINS) and a synthetic occlusion dataset demonstrate the effectiveness and robustness of our model at multi-object instance segmentation under occlusion.
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
Dec 01, 2020
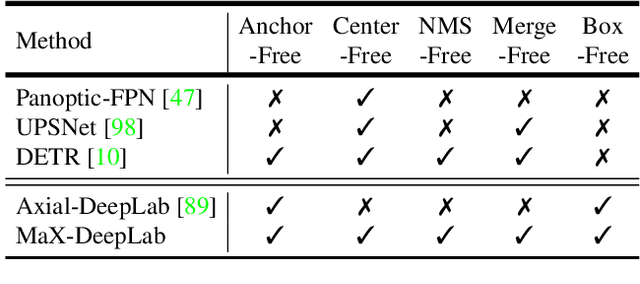

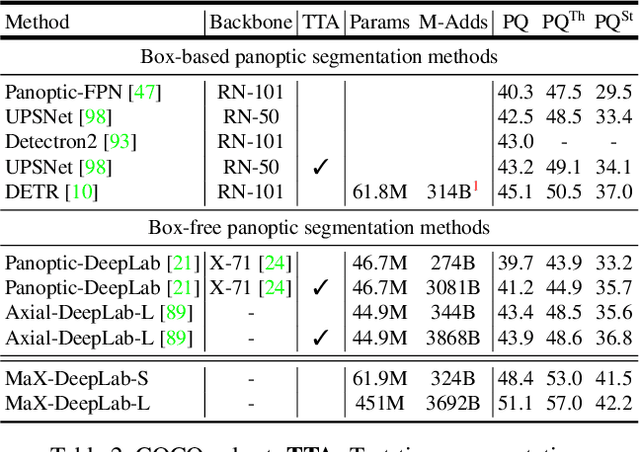
We present MaX-DeepLab, the first end-to-end model for panoptic segmentation. Our approach simplifies the current pipeline that depends heavily on surrogate sub-tasks and hand-designed components, such as box detection, non-maximum suppression, thing-stuff merging, etc. Although these sub-tasks are tackled by area experts, they fail to comprehensively solve the target task. By contrast, our MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching. Our mask transformer employs a dual-path architecture that introduces a global memory path in addition to a CNN path, allowing direct communication with any CNN layers. As a result, MaX-DeepLab shows a significant 7.1% PQ gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. A small variant of MaX-DeepLab improves 3.0% PQ over DETR with similar parameters and M-Adds. Furthermore, MaX-DeepLab, without test time augmentation, achieves new state-of-the-art 51.3% PQ on COCO test-dev set.
Robustness Out of the Box: Compositional Representations Naturally Defend Against Black-Box Patch Attacks
Dec 01, 2020
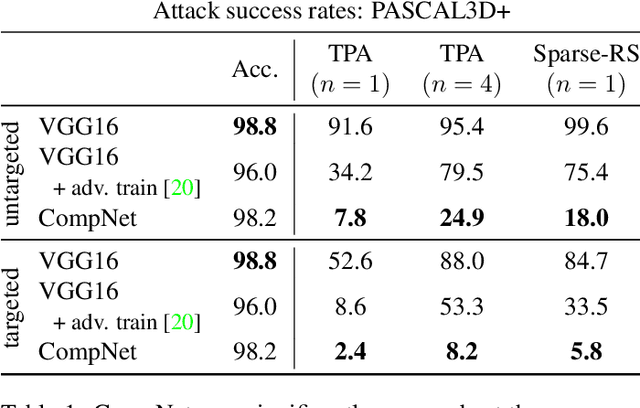

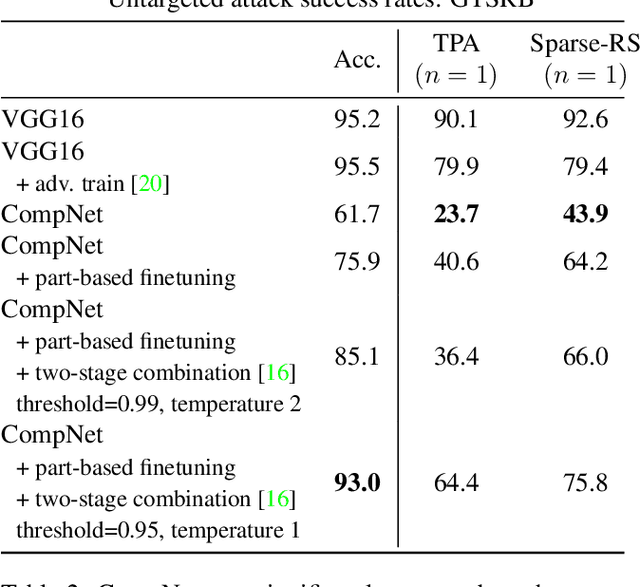
Patch-based adversarial attacks introduce a perceptible but localized change to the input that induces misclassification. While progress has been made in defending against imperceptible attacks, it remains unclear how patch-based attacks can be resisted. In this work, we study two different approaches for defending against black-box patch attacks. First, we show that adversarial training, which is successful against imperceptible attacks, has limited effectiveness against state-of-the-art location-optimized patch attacks. Second, we find that compositional deep networks, which have part-based representations that lead to innate robustness to natural occlusion, are robust to patch attacks on PASCAL3D+ and the German Traffic Sign Recognition Benchmark, without adversarial training. Moreover, the robustness of compositional models outperforms that of adversarially trained standard models by a large margin. However, on GTSRB, we observe that they have problems discriminating between similar traffic signs with fine-grained differences. We overcome this limitation by introducing part-based finetuning, which improves fine-grained recognition. By leveraging compositional representations, this is the first work that defends against black-box patch attacks without expensive adversarial training. This defense is more robust than adversarial training and more interpretable because it can locate and ignore adversarial patches.
Unsupervised Part Discovery via Feature Alignment
Dec 01, 2020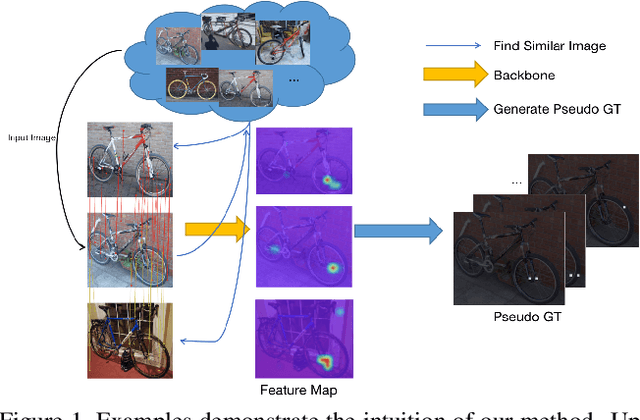
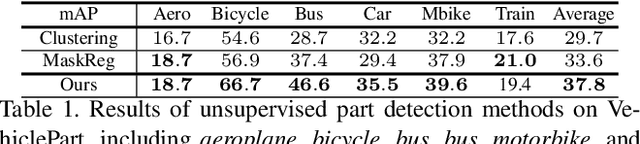
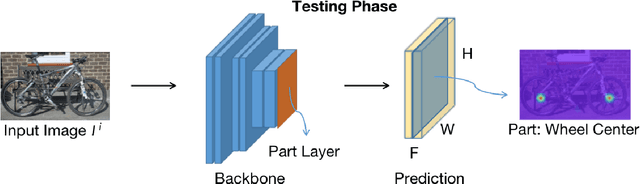

Understanding objects in terms of their individual parts is important, because it enables a precise understanding of the objects' geometrical structure, and enhances object recognition when the object is seen in a novel pose or under partial occlusion. However, the manual annotation of parts in large scale datasets is time consuming and expensive. In this paper, we aim at discovering object parts in an unsupervised manner, i.e., without ground-truth part or keypoint annotations. Our approach builds on the intuition that objects of the same class in a similar pose should have their parts aligned at similar spatial locations. We exploit the property that neural network features are largely invariant to nuisance variables and the main remaining source of variations between images of the same object category is the object pose. Specifically, given a training image, we find a set of similar images that show instances of the same object category in the same pose, through an affine alignment of their corresponding feature maps. The average of the aligned feature maps serves as pseudo ground-truth annotation for a supervised training of the deep network backbone. During inference, part detection is simple and fast, without any extra modules or overheads other than a feed-forward neural network. Our experiments on several datasets from different domains verify the effectiveness of the proposed method. For example, we achieve 37.8 mAP on VehiclePart, which is at least 4.2 better than previous methods.
Batch Normalization with Enhanced Linear Transformation
Nov 28, 2020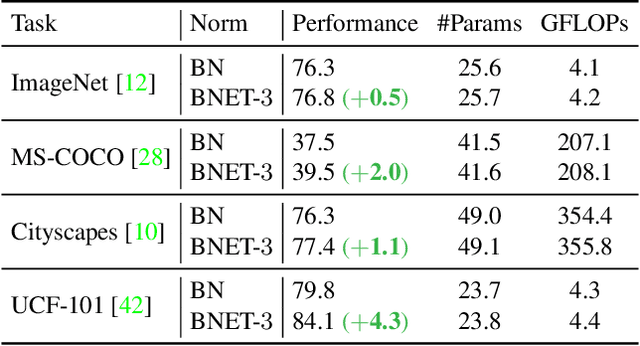
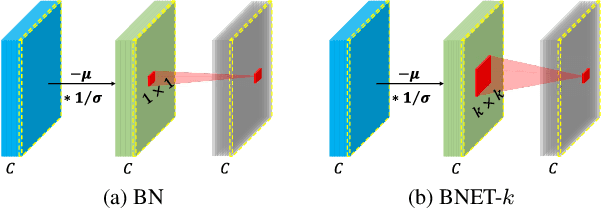
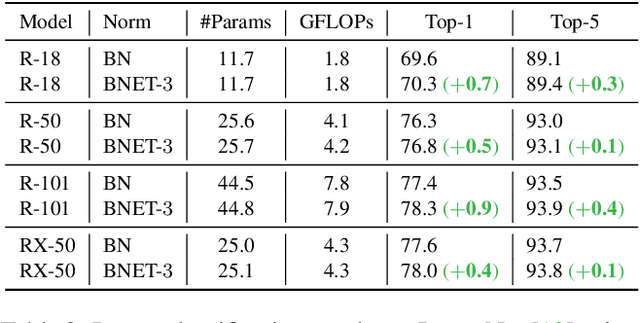
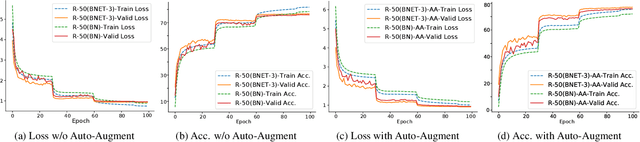
Batch normalization (BN) is a fundamental unit in modern deep networks, in which a linear transformation module was designed for improving BN's flexibility of fitting complex data distributions. In this paper, we demonstrate properly enhancing this linear transformation module can effectively improve the ability of BN. Specifically, rather than using a single neuron, we propose to additionally consider each neuron's neighborhood for calculating the outputs of the linear transformation. Our method, named BNET, can be implemented with 2-3 lines of code in most deep learning libraries. Despite the simplicity, BNET brings consistent performance gains over a wide range of backbones and visual benchmarks. Moreover, we verify that BNET accelerates the convergence of network training and enhances spatial information by assigning the important neurons with larger weights accordingly. The code is available at https://github.com/yuhuixu1993/BNET.