 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoHAS: Differentiable Hyper-parameter and Architecture Search
Jun 05, 2020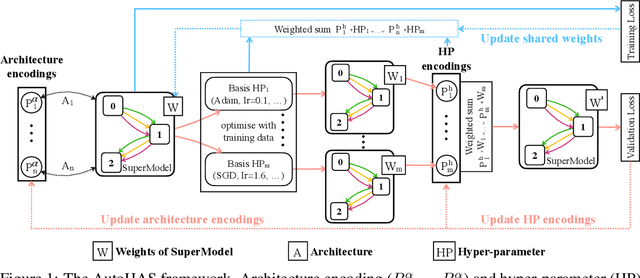
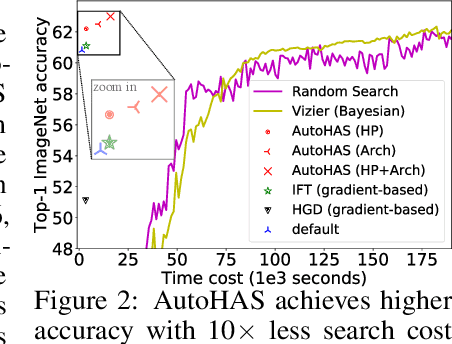
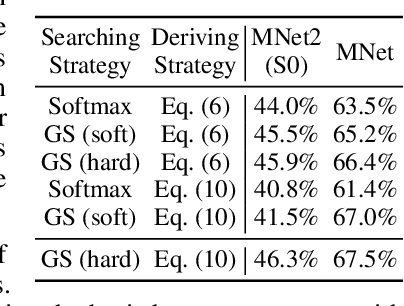
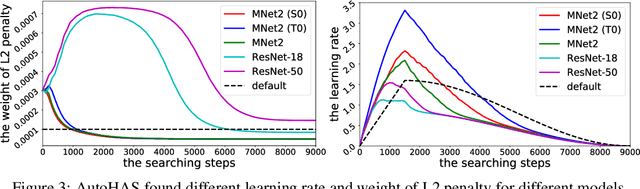
Neural Architecture Search (NAS) has achieved significant progress in pushing state-of-the-art performance. While previous NAS methods search for different network architectures with the same hyper-parameters, we argue that such search would lead to sub-optimal results. We empirically observe that different architectures tend to favor their own hyper-parameters. In this work, we extend NAS to a broader and more practical space by combining hyper-parameter and architecture search. As architecture choices are often categorical whereas hyper-parameter choices are often continuous, a critical challenge here is how to handle these two types of values in a joint search space. To tackle this challenge, we propose AutoHAS, a differentiable hyper-parameter and architecture search approach, with the idea of discretizing the continuous space into a linear combination of multiple categorical basis. A key element of AutoHAS is the use of weight sharing across all architectures and hyper-parameters which enables efficient search over the large joint search space. Experimental results on MobileNet/ResNet/EfficientNet/BERT show that AutoHAS significantly improves accuracy up to 2% on ImageNet and F1 score up to 0.4 on SQuAD 1.1, with search cost comparable to training a single model. Compared to other AutoML methods, such as random search or Bayesian methods, AutoHAS can achieve better accuracy with 10x less compute cost.
Detecting Nonlinear Causality in Multivariate Time Series with Sparse Additive Models
Apr 26, 2018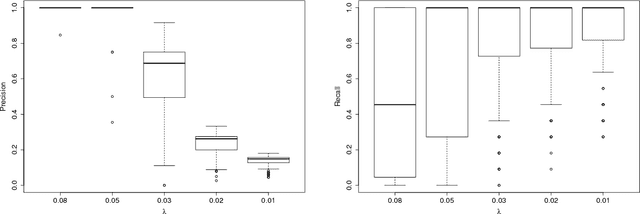
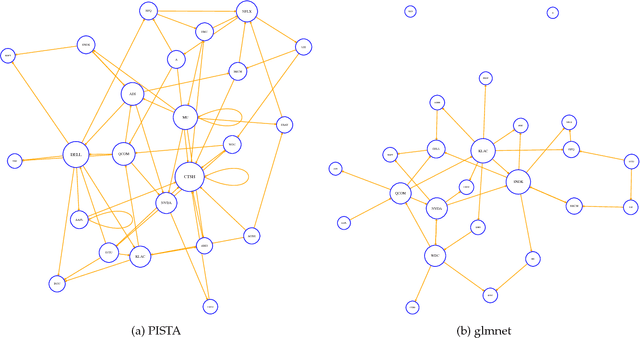
We propose a nonparametric method for detecting nonlinear causal relationship within a set of multidimensional discrete time series, by using sparse additive models (SpAMs). We show that, when the input to the SpAM is a $\beta$-mixing time series, the model can be fitted by first approximating each unknown function with a linear combination of a set of B-spline bases, and then solving a group-lasso-type optimization problem with nonconvex regularization. Theoretically, we characterize the oracle statistical properties of the proposed sparse estimator in function estimation and model selection. Numerically, we propose an efficient pathwise iterative shrinkage thresholding algorithm (PISTA), which tames the nonconvexity and guarantees linear convergence towards the desired sparse estimator with high probability.
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
Apr 23, 2018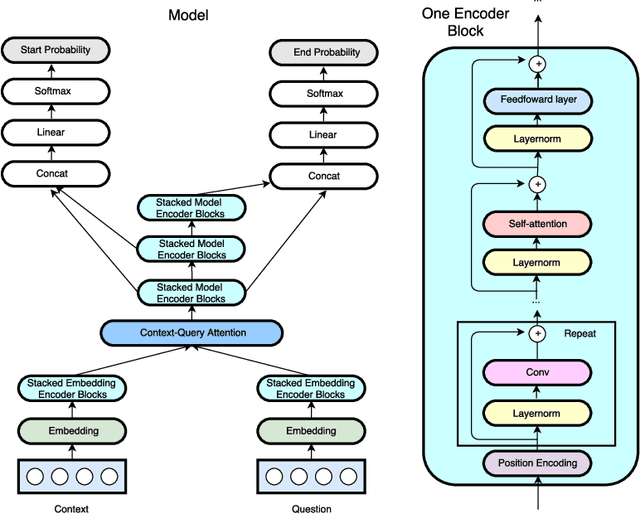

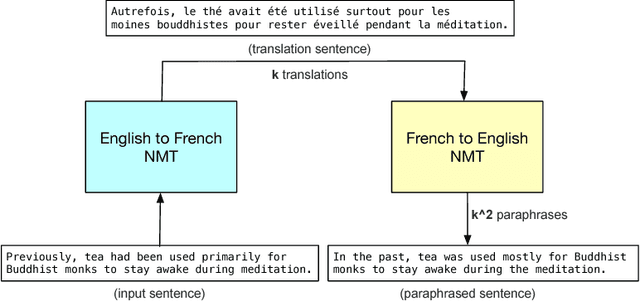
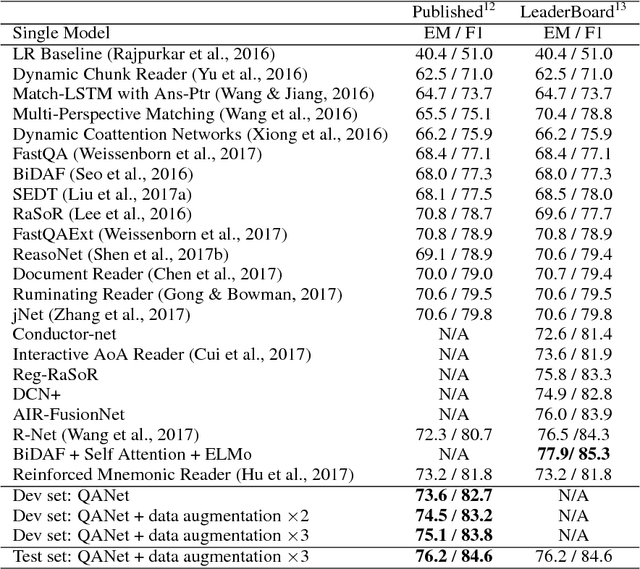
Current end-to-end machine reading and question answering (Q\&A) models are primarily based on recurrent neural networks (RNNs) with attention. Despite their success, these models are often slow for both training and inference due to the sequential nature of RNNs. We propose a new Q\&A architecture called QANet, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions. On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models. The speed-up gain allows us to train the model with much more data. We hence combine our model with data generated by backtranslation from a neural machine translation model. On the SQuAD dataset, our single model, trained with augmented data, achieves 84.6 F1 score on the test set, which is significantly better than the best published F1 score of 81.8.
Block-Normalized Gradient Method: An Empirical Study for Training Deep Neural Network
Apr 23, 2018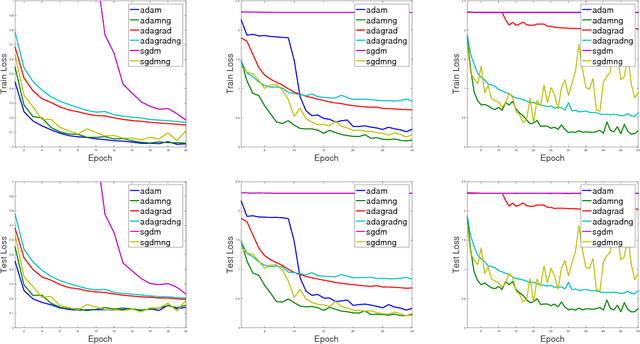
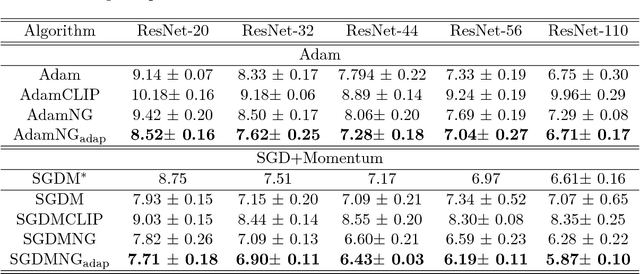
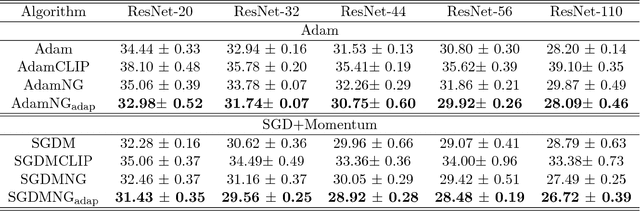
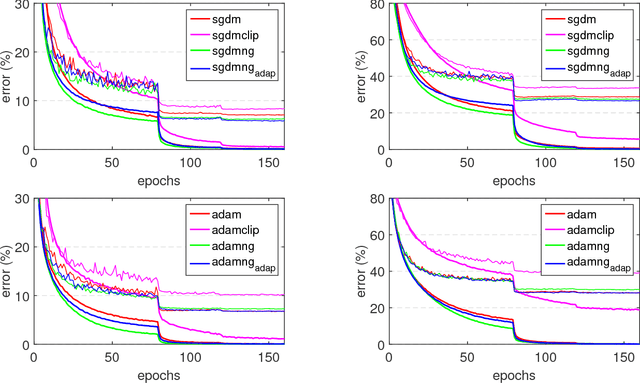
In this paper, we propose a generic and simple strategy for utilizing stochastic gradient information in optimization. The technique essentially contains two consecutive steps in each iteration: 1) computing and normalizing each block (layer) of the mini-batch stochastic gradient; 2) selecting appropriate step size to update the decision variable (parameter) towards the negative of the block-normalized gradient. We conduct extensive empirical studies on various non-convex neural network optimization problems, including multi-layer perceptron, convolution neural networks and recurrent neural networks. The results indicate the block-normalized gradient can help accelerate the training of neural networks. In particular, we observe that the normalized gradient methods having constant step size with occasionally decay, such as SGD with momentum, have better performance in the deep convolution neural networks, while those with adaptive step sizes, such as Adam, perform better in recurrent neural networks. Besides, we also observe this line of methods can lead to solutions with better generalization properties, which is confirmed by the performance improvement over strong baselines.
On Computationally Tractable Selection of Experiments in Measurement-Constrained Regression Models
Dec 20, 2017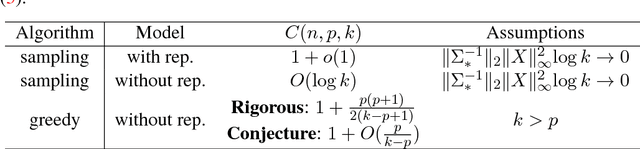
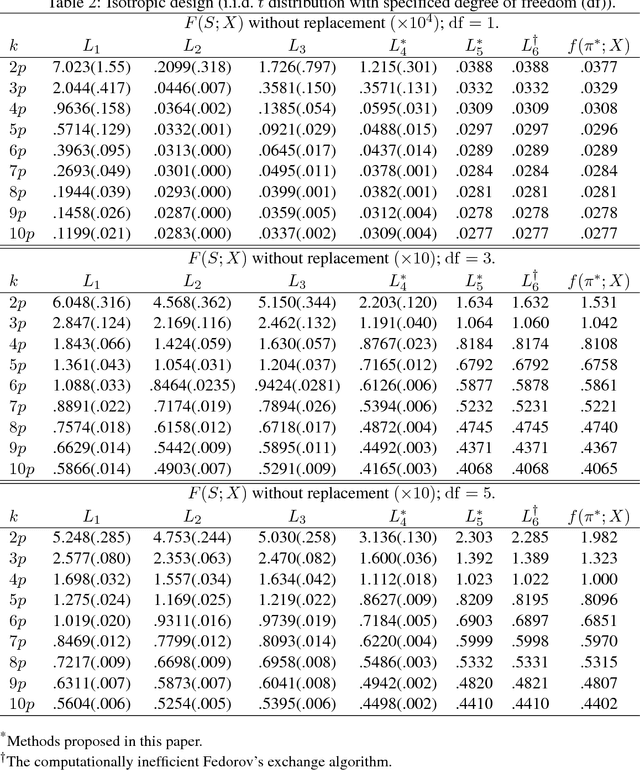
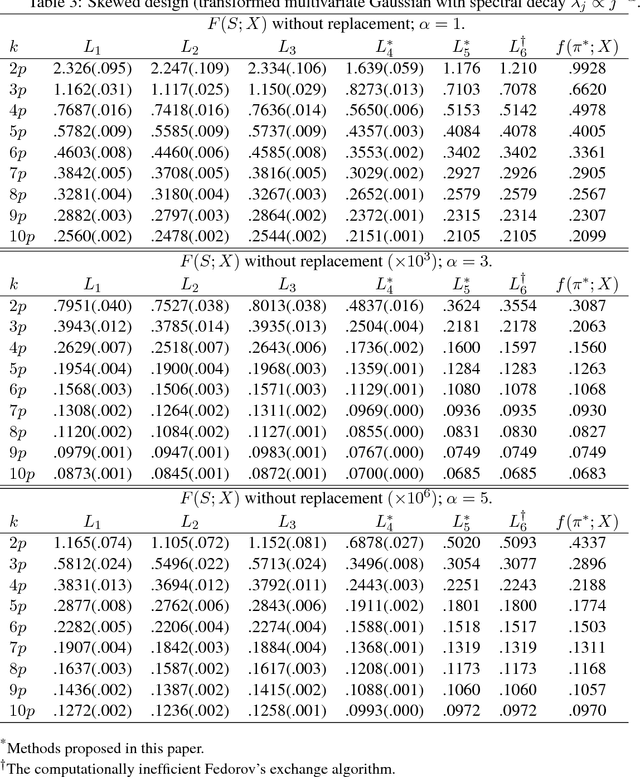
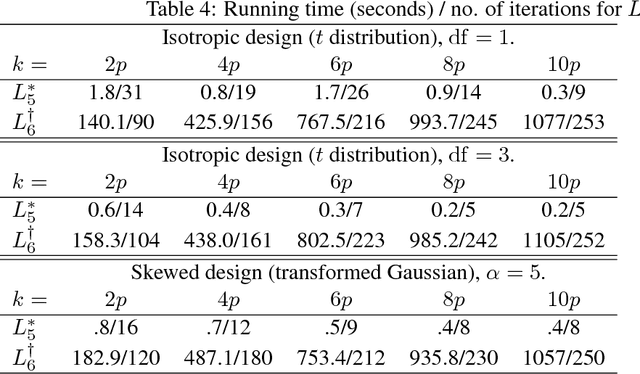
We derive computationally tractable methods to select a small subset of experiment settings from a large pool of given design points. The primary focus is on linear regression models, while the technique extends to generalized linear models and Delta's method (estimating functions of linear regression models) as well. The algorithms are based on a continuous relaxation of an otherwise intractable combinatorial optimization problem, with sampling or greedy procedures as post-processing steps. Formal approximation guarantees are established for both algorithms, and numerical results on both synthetic and real-world data confirm the effectiveness of the proposed methods.
Orthogonal Weight Normalization: Solution to Optimization over Multiple Dependent Stiefel Manifolds in Deep Neural Networks
Nov 21, 2017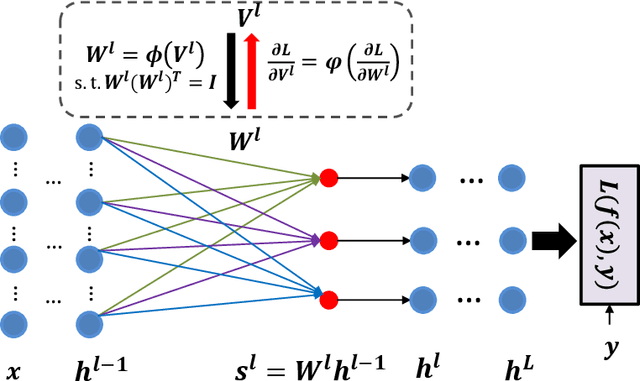
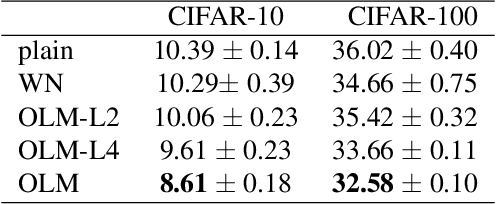


Orthogonal matrix has shown advantages in training Recurrent Neural Networks (RNNs), but such matrix is limited to be square for the hidden-to-hidden transformation in RNNs. In this paper, we generalize such square orthogonal matrix to orthogonal rectangular matrix and formulating this problem in feed-forward Neural Networks (FNNs) as Optimization over Multiple Dependent Stiefel Manifolds (OMDSM). We show that the rectangular orthogonal matrix can stabilize the distribution of network activations and regularize FNNs. We also propose a novel orthogonal weight normalization method to solve OMDSM. Particularly, it constructs orthogonal transformation over proxy parameters to ensure the weight matrix is orthogonal and back-propagates gradient information through the transformation during training. To guarantee stability, we minimize the distortions between proxy parameters and canonical weights over all tractable orthogonal transformations. In addition, we design an orthogonal linear module (OLM) to learn orthogonal filter banks in practice, which can be used as an alternative to standard linear module. Extensive experiments demonstrate that by simply substituting OLM for standard linear module without revising any experimental protocols, our method largely improves the performance of the state-of-the-art networks, including Inception and residual networks on CIFAR and ImageNet datasets. In particular, we have reduced the test error of wide residual network on CIFAR-100 from 20.04% to 18.61% with such simple substitution. Our code is available online for result reproduction.
DSCOVR: Randomized Primal-Dual Block Coordinate Algorithms for Asynchronous Distributed Optimization
Oct 13, 2017

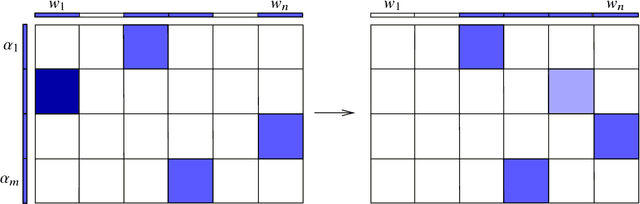

Machine learning with big data often involves large optimization models. For distributed optimization over a cluster of machines, frequent communication and synchronization of all model parameters (optimization variables) can be very costly. A promising solution is to use parameter servers to store different subsets of the model parameters, and update them asynchronously at different machines using local datasets. In this paper, we focus on distributed optimization of large linear models with convex loss functions, and propose a family of randomized primal-dual block coordinate algorithms that are especially suitable for asynchronous distributed implementation with parameter servers. In particular, we work with the saddle-point formulation of such problems which allows simultaneous data and model partitioning, and exploit its structure by doubly stochastic coordinate optimization with variance reduction (DSCOVR). Compared with other first-order distributed algorithms, we show that DSCOVR may require less amount of overall computation and communication, and less or no synchronization. We discuss the implementation details of the DSCOVR algorithms, and present numerical experiments on an industrial distributed computing system.
Learning to Skim Text
Apr 29, 2017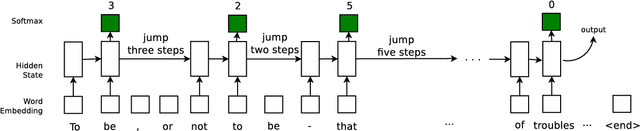



Recurrent Neural Networks are showing much promise in many sub-areas of natural language processing, ranging from document classification to machine translation to automatic question answering. Despite their promise, many recurrent models have to read the whole text word by word, making it slow to handle long documents. For example, it is difficult to use a recurrent network to read a book and answer questions about it. In this paper, we present an approach of reading text while skipping irrelevant information if needed. The underlying model is a recurrent network that learns how far to jump after reading a few words of the input text. We employ a standard policy gradient method to train the model to make discrete jumping decisions. In our benchmarks on four different tasks, including number prediction, sentiment analysis, news article classification and automatic Q\&A, our proposed model, a modified LSTM with jumping, is up to 6 times faster than the standard sequential LSTM, while maintaining the same or even better accuracy.
Doubly Stochastic Primal-Dual Coordinate Method for Bilinear Saddle-Point Problem
Apr 12, 2017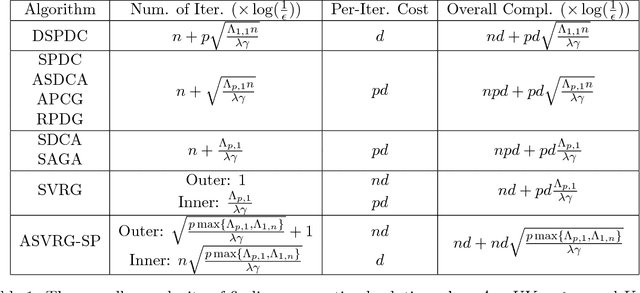
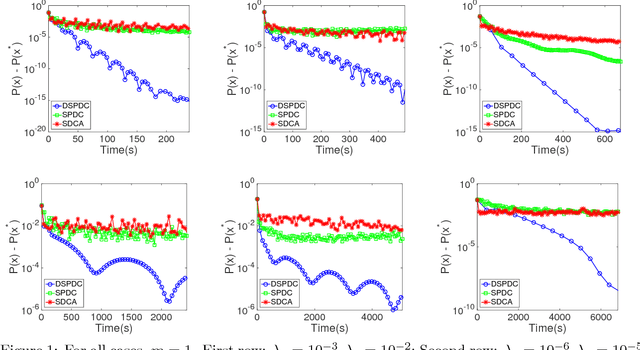

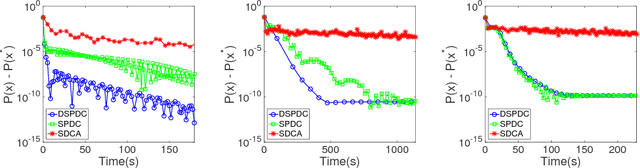
We propose a doubly stochastic primal-dual coordinate optimization algorithm for empirical risk minimization, which can be formulated as a bilinear saddle-point problem. In each iteration, our method randomly samples a block of coordinates of the primal and dual solutions to update. The linear convergence of our method could be established in terms of 1) the distance from the current iterate to the optimal solution and 2) the primal-dual objective gap. We show that the proposed method has a lower overall complexity than existing coordinate methods when either the data matrix has a factorized structure or the proximal mapping on each block is computationally expensive, e.g., involving an eigenvalue decomposition. The efficiency of the proposed method is confirmed by empirical studies on several real applications, such as the multi-task large margin nearest neighbor problem.
An Improved Gap-Dependency Analysis of the Noisy Power Method
Feb 23, 2016We consider the noisy power method algorithm, which has wide applications in machine learning and statistics, especially those related to principal component analysis (PCA) under resource (communication, memory or privacy) constraints. Existing analysis of the noisy power method shows an unsatisfactory dependency over the "consecutive" spectral gap $(\sigma_k-\sigma_{k+1})$ of an input data matrix, which could be very small and hence limits the algorithm's applicability. In this paper, we present a new analysis of the noisy power method that achieves improved gap dependency for both sample complexity and noise tolerance bounds. More specifically, we improve the dependency over $(\sigma_k-\sigma_{k+1})$ to dependency over $(\sigma_k-\sigma_{q+1})$, where $q$ is an intermediate algorithm parameter and could be much larger than the target rank $k$. Our proofs are built upon a novel characterization of proximity between two subspaces that differ from canonical angle characterizations analyzed in previous works. Finally, we apply our improved bounds to distributed private PCA and memory-efficient streaming PCA and obtain bounds that are superior to existing results in the literature.