 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROBIN : A Benchmark for Robustness to Individual Nuisances in Real-World Out-of-Distribution Shifts
Dec 02, 2021
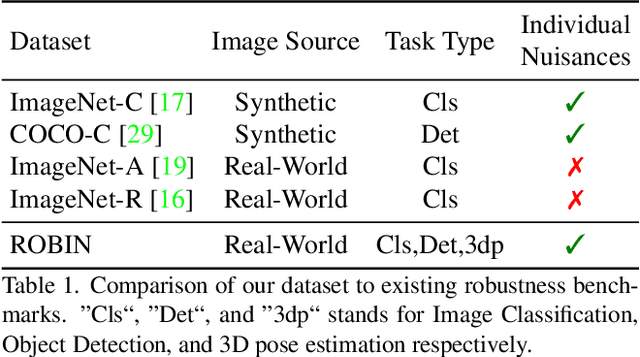

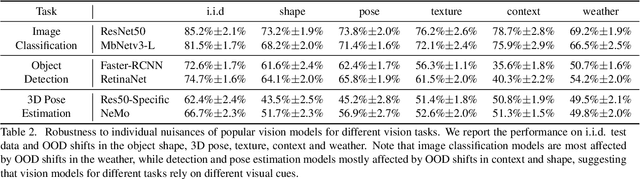
Enhancing the robustness in real-world scenarios has been proven very challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or they simply measure robustness as generalization between datasets and hence ignore the effects of individual nuisance factors. In this work, we introduce ROBIN, a benchmark dataset for diagnosing the robustness of vision algorithms to individual nuisances in real-world images. ROBIN builds on 10 rigid categories from the PASCAL VOC 2012 and ImageNet datasets and includes out-of-distribution examples of the objects 3D pose, shape, texture, context and weather conditions. ROBIN is richly annotated to enable benchmark models for image classification, object detection, and 3D pose estimation. We provide results for a number of popular baselines and make several interesting observations: 1. Some nuisance factors have a much stronger negative effect on the performance compared to others. Moreover, the negative effect of an OODnuisance depends on the downstream vision task. 2. Current approaches to enhance OOD robustness using strong data augmentation have only marginal effects in real-world OOD scenarios, and sometimes even reduce the OOD performance. 3. We do not observe any significant differences between convolutional and transformer architectures in terms of OOD robustness. We believe our dataset provides a rich testbed to study the OOD robustness of vision algorithms and will help to significantly push forward research in this area.
PartImageNet: A Large, High-Quality Dataset of Parts
Dec 02, 2021
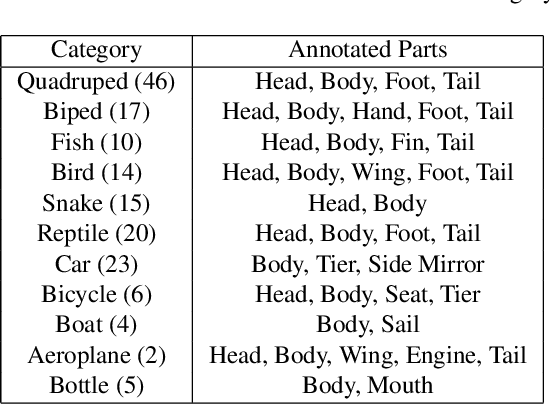

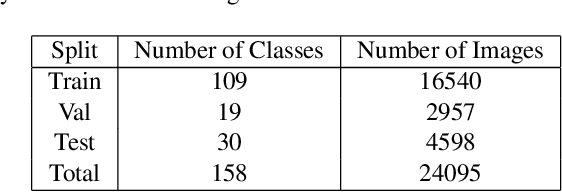
A part-based object understanding facilitates efficient compositional learning and knowledge transfer, robustness to occlusion, and has the potential to increase the performance on general recognition and localization tasks. However, research on part-based models is hindered due to the lack of datasets with part annotations, which is caused by the extreme difficulty and high cost of annotating object parts in images. In this paper, we propose PartImageNet, a large, high-quality dataset with part segmentation annotations. It consists of 158 classes from ImageNet with approximately 24000 images. PartImageNet is unique because it offers part-level annotations on a general set of classes with non-rigid, articulated objects, while having an order of magnitude larger size compared to existing datasets. It can be utilized in multiple vision tasks including but not limited to: Part Discovery, Semantic Segmentation, Few-shot Learning. Comprehensive experiments are conducted to set up a set of baselines on PartImageNet and we find that existing works on part discovery can not always produce satisfactory results during complex variations. The exploit of parts on downstream tasks also remains insufficient. We believe that our PartImageNet will greatly facilitate the research on part-based models and their applications. The dataset and scripts will soon be released at https://github.com/TACJu/PartImageNet.
Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose
Oct 27, 2021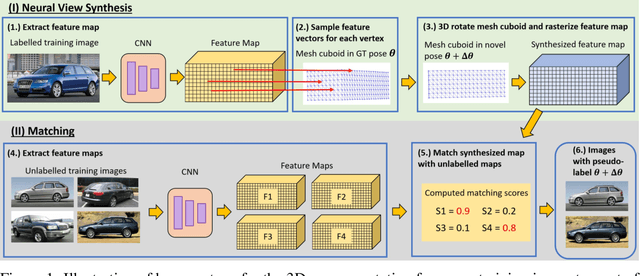
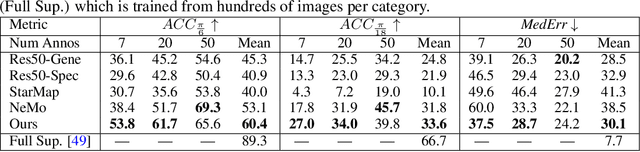

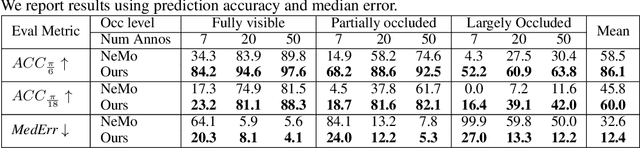
We study the problem of learning to estimate the 3D object pose from a few labelled examples and a collection of unlabelled data. Our main contribution is a learning framework, neural view synthesis and matching, that can transfer the 3D pose annotation from the labelled to unlabelled images reliably, despite unseen 3D views and nuisance variations such as the object shape, texture, illumination or scene context. In our approach, objects are represented as 3D cuboid meshes composed of feature vectors at each mesh vertex. The model is initialized from a few labelled images and is subsequently used to synthesize feature representations of unseen 3D views. The synthesized views are matched with the feature representations of unlabelled images to generate pseudo-labels of the 3D pose. The pseudo-labelled data is, in turn, used to train the feature extractor such that the features at each mesh vertex are more invariant across varying 3D views of the object. Our model is trained in an EM-type manner alternating between increasing the 3D pose invariance of the feature extractor and annotating unlabelled data through neural view synthesis and matching. We demonstrate the effectiveness of the proposed semi-supervised learning framework for 3D pose estimation on the PASCAL3D+ and KITTI datasets. We find that our approach outperforms all baselines by a wide margin, particularly in an extreme few-shot setting where only 7 annotated images are given. Remarkably, we observe that our model also achieves an exceptional robustness in out-of-distribution scenarios that involve partial occlusion.
A Light-weight Interpretable CompositionalNetwork for Nuclei Detection and Weakly-supervised Segmentation
Oct 26, 2021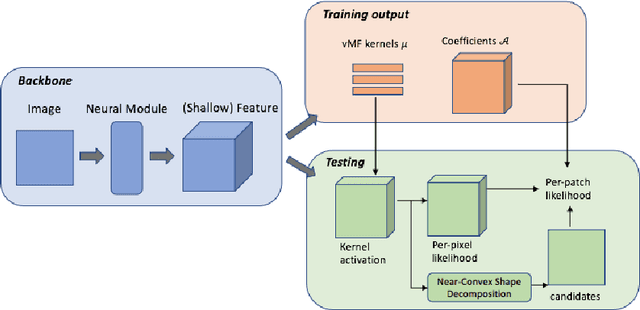
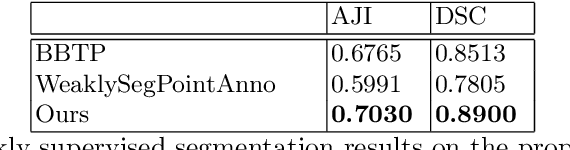
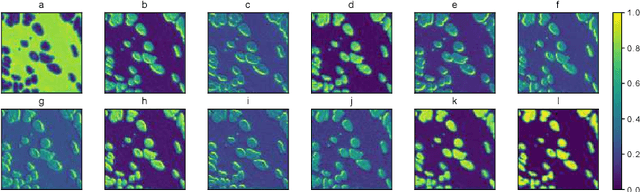
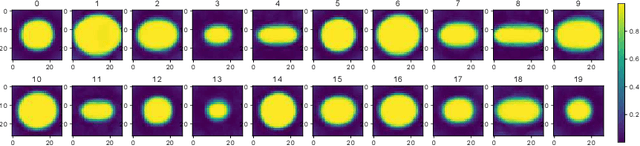
The field of computational pathology has witnessed great advancements since deep neural networks have been widely applied. These deep neural networks usually require large numbers of annotated data to train vast parameters. However, it takes significant effort to annotate a large histopathology dataset. We propose to build a data-efficient model, which only requires partial annotation, specifically on isolated nucleus, rather than on the whole slide image. It exploits shallow features as its backbone and is light-weight, therefore a small number of data is sufficient for training. What's more, it is a generative compositional model, which enjoys interpretability in its prediction. The proposed method could be an alternative solution for the data-hungry problem of deep learning methods.
Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
Jul 12, 2021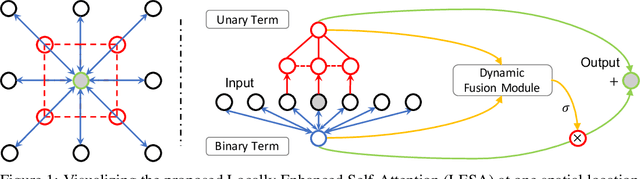

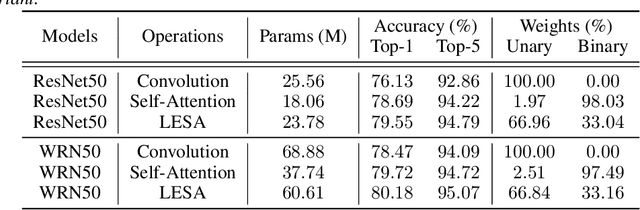

Self-Attention has become prevalent in computer vision models. Inspired by fully connected Conditional Random Fields (CRFs), we decompose it into local and context terms. They correspond to the unary and binary terms in CRF and are implemented by attention mechanisms with projection matrices. We observe that the unary terms only make small contributions to the outputs, and meanwhile standard CNNs that rely solely on the unary terms achieve great performances on a variety of tasks. Therefore, we propose Locally Enhanced Self-Attention (LESA), which enhances the unary term by incorporating it with convolutions, and utilizes a fusion module to dynamically couple the unary and binary operations. In our experiments, we replace the self-attention modules with LESA. The results on ImageNet and COCO show the superiority of LESA over convolution and self-attention baselines for the tasks of image recognition, object detection, and instance segmentation. The code is made publicly available.
To fit or not to fit: Model-based Face Reconstruction and Occlusion Segmentation from Weak Supervision
Jun 17, 2021


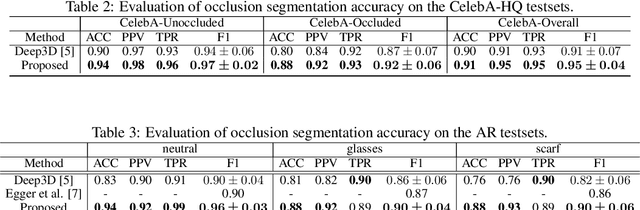
3D face reconstruction from a single image is challenging due to its ill-posed nature. Model-based face autoencoders address this issue effectively by fitting a face model to the target image in a weakly supervised manner. However, in unconstrained environments occlusions distort the face reconstruction because the model often erroneously tries to adapt to occluded face regions. Supervised occlusion segmentation is a viable solution to avoid the fitting of occluded face regions, but it requires a large amount of annotated training data. In this work, we enable model-based face autoencoders to segment occluders accurately without requiring any additional supervision during training, and this separates regions where the model will be fitted from those where it will not be fitted. To achieve this, we extend face autoencoders with a segmentation network. The segmentation network decides which regions the model should adapt to by reaching balances in a trade-off between including pixels and adapting the model to them, and excluding pixels so that the model fitting is not negatively affected and reaches higher overall reconstruction accuracy on pixels showing the face. This leads to a synergistic effect, in which the occlusion segmentation guides the training of the face autoencoder to constrain the fitting in the non-occluded regions, while the improved fitting enables the segmentation model to better predict the occluded face regions. Qualitative and quantitative experiments on the CelebA-HQ database and the AR database verify the effectiveness of our model in improving 3D face reconstruction under occlusions and in enabling accurate occlusion segmentation from weak supervision only. Code available at https://github.com/unibas-gravis/Occlusion-Robust-MoFA.
Simulated Adversarial Testing of Face Recognition Models
Jun 08, 2021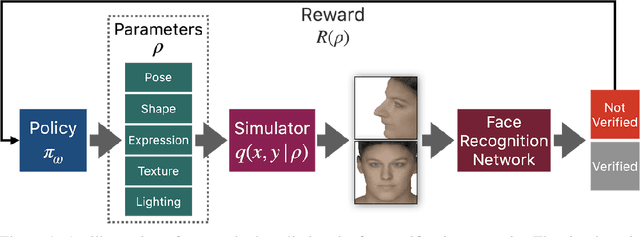

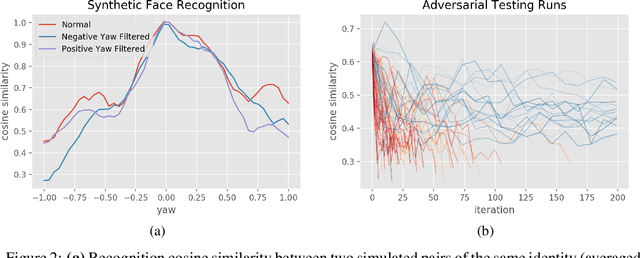
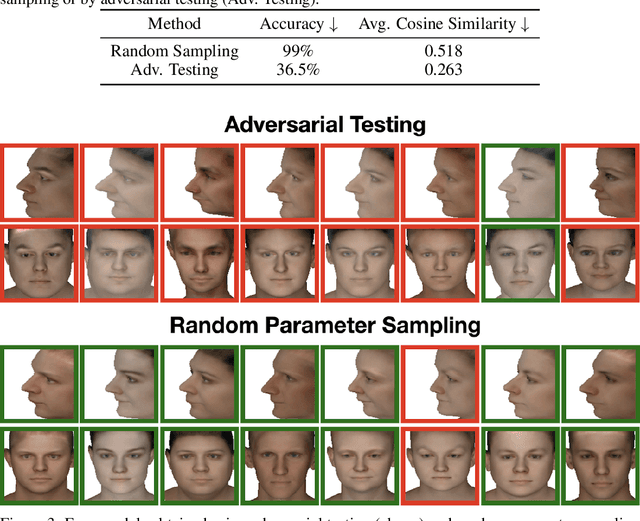
Most machine learning models are validated and tested on fixed datasets. This can give an incomplete picture of the capabilities and weaknesses of the model. Such weaknesses can be revealed at test time in the real world. The risks involved in such failures can be loss of profits, loss of time or even loss of life in certain critical applications. In order to alleviate this issue, simulators can be controlled in a fine-grained manner using interpretable parameters to explore the semantic image manifold. In this work, we propose a framework for learning how to test machine learning algorithms using simulators in an adversarial manner in order to find weaknesses in the model before deploying it in critical scenarios. We apply this model in a face recognition scenario. We are the first to show that weaknesses of models trained on real data can be discovered using simulated samples. Using our proposed method, we can find adversarial synthetic faces that fool contemporary face recognition models. This demonstrates the fact that these models have weaknesses that are not measured by commonly used validation datasets. We hypothesize that this type of adversarial examples are not isolated, but usually lie in connected components in the latent space of the simulator. We present a method to find these adversarial regions as opposed to the typical adversarial points found in the adversarial example literature.
Rethinking Re-Sampling in Imbalanced Semi-Supervised Learning
Jun 01, 2021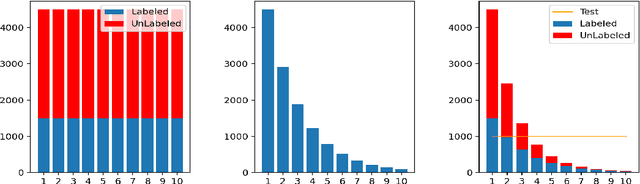
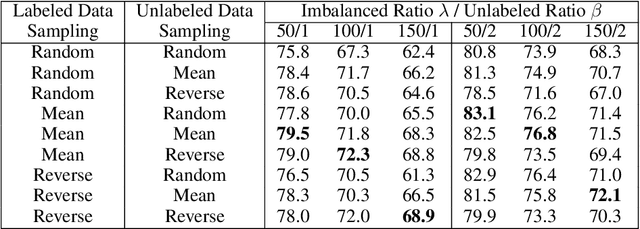
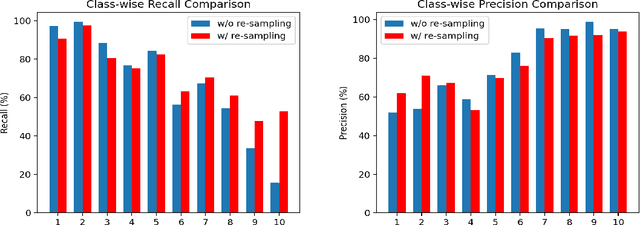
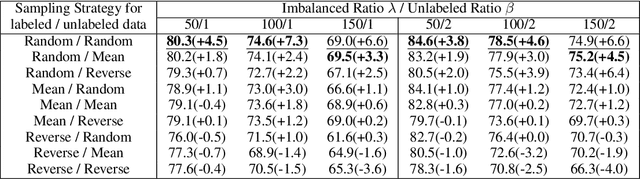
Semi-Supervised Learning (SSL) has shown its strong ability in utilizing unlabeled data when labeled data is scarce. However, most SSL algorithms work under the assumption that the class distributions are balanced in both training and test sets. In this work, we consider the problem of SSL on class-imbalanced data, which better reflects real-world situations but has only received limited attention so far. In particular, we decouple the training of the representation and the classifier, and systematically investigate the effects of different data re-sampling techniques when training the whole network including a classifier as well as fine-tuning the feature extractor only. We find that data re-sampling is of critical importance to learn a good classifier as it increases the accuracy of the pseudo-labels, in particular for the minority classes in the unlabeled data. Interestingly, we find that accurate pseudo-labels do not help when training the feature extractor, rather contrariwise, data re-sampling harms the training of the feature extractor. This finding is against the general intuition that wrong pseudo-labels always harm the model performance in SSL. Based on these findings, we suggest to re-think the current paradigm of having a single data re-sampling strategy and develop a simple yet highly effective Bi-Sampling (BiS) strategy for SSL on class-imbalanced data. BiS implements two different re-sampling strategies for training the feature extractor and the classifier and integrates this decoupled training into an end-to-end framework... Code will be released at https://github.com/TACJu/Bi-Sampling.
A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation
Apr 15, 2021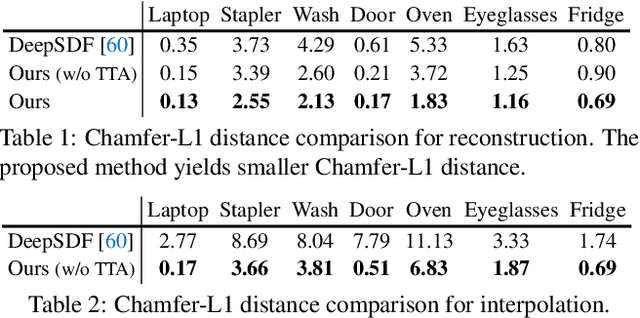
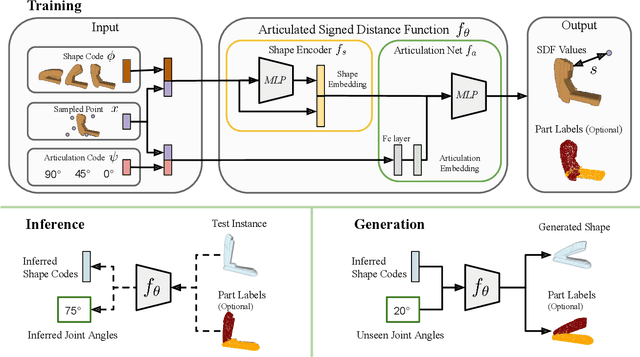
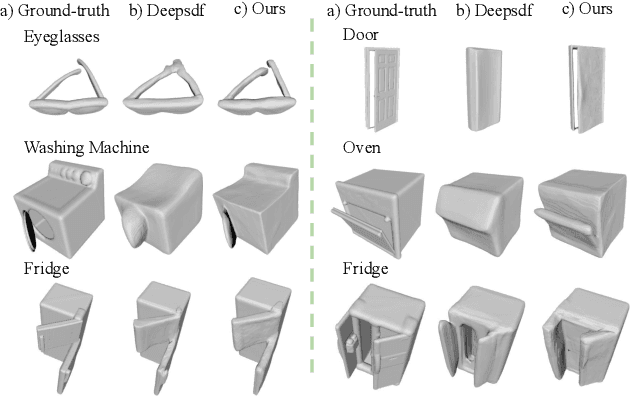

Recent work has made significant progress on using implicit functions, as a continuous representation for 3D rigid object shape reconstruction. However, much less effort has been devoted to modeling general articulated objects. Compared to rigid objects, articulated objects have higher degrees of freedom, which makes it hard to generalize to unseen shapes. To deal with the large shape variance, we introduce Articulated Signed Distance Functions (A-SDF) to represent articulated shapes with a disentangled latent space, where we have separate codes for encoding shape and articulation. We assume no prior knowledge on part geometry, articulation status, joint type, joint axis, and joint location. With this disentangled continuous representation, we demonstrate that we can control the articulation input and animate unseen instances with unseen joint angles. Furthermore, we propose a Test-Time Adaptation inference algorithm to adjust our model during inference. We demonstrate our model generalize well to out-of-distribution and unseen data, e.g., partial point clouds and real-world depth images.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 28, 2021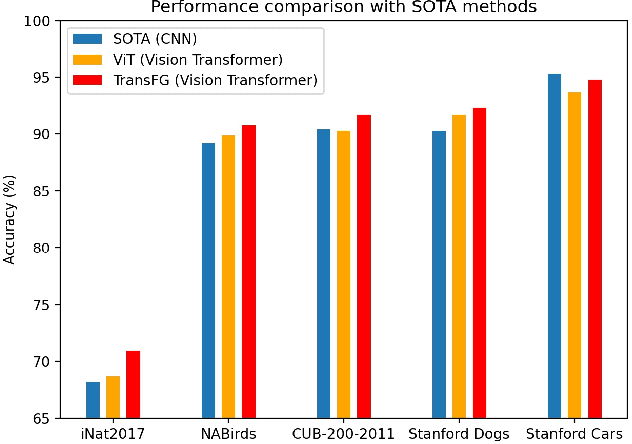
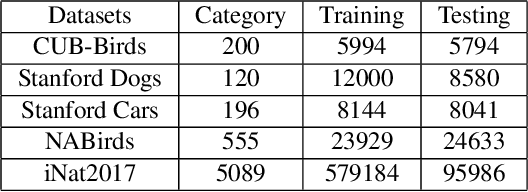
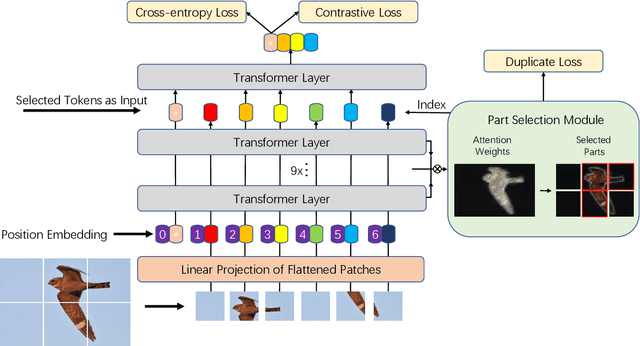
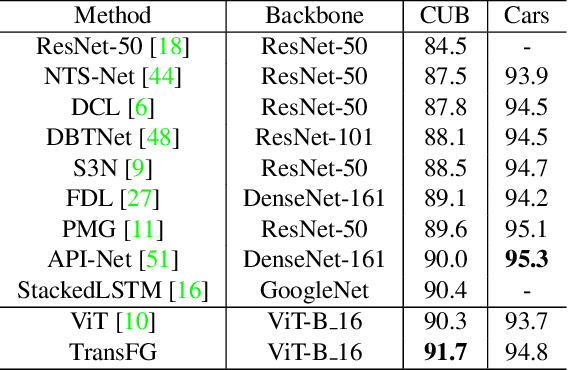
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model. Code is available at https://github.com/TACJu/TransFG.