 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive and Robust Cost-Aware Proof of Quality for Decentralized LLM Inference Networks
Jan 29, 2026Decentralized large language model inference networks require lightweight mechanisms to reward high quality outputs under heterogeneous latency and cost. Proof of Quality provides scalable verification by sampling evaluator nodes that score candidate outputs, then aggregating their scores into a consensus signal that determines rewards. However, evaluator heterogeneity and malicious score manipulation can distort consensus and inflate payouts, which weakens incentive alignment in open participation settings. This paper extends a cost-aware Proof of Quality mechanism by adding adversary-resilient consensus formation. We study robust aggregation rules, including median and trimmed mean, and an adaptive trust-weighted consensus that updates evaluator weights from deviation signals. Using question answering and summarization workloads with a ground truth proxy for offline analysis, we quantify evaluator reliability and show strong variance across evaluators, including task-dependent misalignment that can invert correlations. We then evaluate robustness under four adversarial strategies, including noise injection, boosting, sabotage, and intermittent manipulation, across a sweep of malicious ratios and evaluator sample sizes. Our results show that robust aggregation improves consensus alignment with the ground truth proxy and reduces sensitivity to noisy and strategic attacks compared with simple averaging. We further characterize the operational trade-off introduced by evaluator sampling, where larger evaluator sets reduce evaluator rewards and increase payoff variance while inference rewards remain relatively stable in our configuration. These findings motivate robust consensus as a default component for cost-aware Proof of Quality and provide practical guidance for selecting evaluator sampling parameters under adversarial risk and resource constraints.
Design and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
Dec 18, 2025
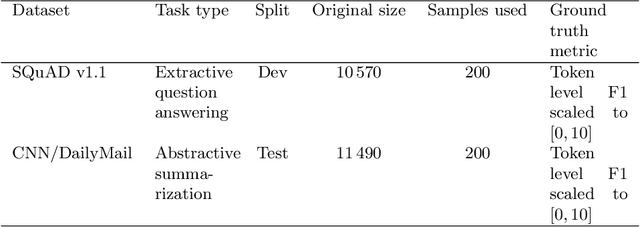


Decentralized large language model (LLM) inference promises transparent and censorship resistant access to advanced AI, yet existing verification approaches struggle to scale to modern models. Proof of Quality (PoQ) replaces cryptographic verification of computation with consensus over output quality, but the original formulation ignores heterogeneous computational costs across inference and evaluator nodes. This paper introduces a cost-aware PoQ framework that integrates explicit efficiency measurements into the reward mechanism for both types of nodes. The design combines ground truth token level F1, lightweight learned evaluators, and GPT based judgments within a unified evaluation pipeline, and adopts a linear reward function that balances normalized quality and cost. Experiments on extractive question answering and abstractive summarization use five instruction tuned LLMs ranging from TinyLlama-1.1B to Llama-3.2-3B and three evaluation models spanning cross encoder and bi encoder architectures. Results show that a semantic textual similarity bi encoder achieves much higher correlation with both ground truth and GPT scores than cross encoders, indicating that evaluator architecture is a critical design choice for PoQ. Quality-cost analysis further reveals that the largest models in the pool are also the most efficient in terms of quality per unit latency. Monte Carlo simulations over 5\,000 PoQ rounds demonstrate that the cost-aware reward scheme consistently assigns higher average rewards to high quality low cost inference models and to efficient evaluators, while penalizing slow low quality nodes. These findings suggest that cost-aware PoQ provides a practical foundation for economically sustainable decentralized LLM inference.
SOP-Bench: Complex Industrial SOPs for Evaluating LLM Agents
Jun 09, 2025Large Language Models (LLMs) demonstrate impressive general-purpose reasoning and problem-solving abilities. However, they struggle with executing complex, long-horizon workflows that demand strict adherence to Standard Operating Procedures (SOPs), a critical requirement for real-world industrial automation. Despite this need, there is a lack of public benchmarks that reflect the complexity, structure, and domain-specific nuances of SOPs. To address this, we present three main contributions. First, we introduce a synthetic data generation framework to create realistic, industry-grade SOPs that rigorously test the planning, reasoning, and tool-use capabilities of LLM-based agents. Second, using this framework, we develop SOP-Bench, a benchmark of over 1,800 tasks across 10 industrial domains, each with APIs, tool interfaces, and human-validated test cases. Third, we evaluate two prominent agent architectures: Function-Calling and ReAct Agents, on SOP-Bench, observing average success rates of only 27% and 48%, respectively. Remarkably, when the tool registry is much larger than necessary, agents invoke incorrect tools nearly 100% of the time. These findings underscore a substantial gap between current agentic capabilities of LLMs and the demands of automating real-world SOPs. Performance varies significantly by task and domain, highlighting the need for domain-specific benchmarking and architectural choices before deployment. SOP-Bench is publicly available at http://sop-bench.s3-website-us-west-2.amazonaws.com/. We also release the prompts underpinning the data generation framework to support new domain-specific SOP benchmarks. We invite the community to extend SOP-Bench with SOPs from their industrial domains.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
Tailoring Self-Rationalizers with Multi-Reward Distillation
Nov 06, 2023Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
Resprompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models
Oct 07, 2023Chain-of-thought (CoT) prompting, which offers step-by-step problem-solving rationales, has impressively unlocked the reasoning potential of large language models (LLMs). Yet, the standard CoT is less effective in problems demanding multiple reasoning steps. This limitation arises from the complex reasoning process in multi-step problems: later stages often depend on the results of several steps earlier, not just the results of the immediately preceding step. Such complexities suggest the reasoning process is naturally represented as a graph. The almost linear and straightforward structure of CoT prompting, however, struggles to capture this complex reasoning graph. To address this challenge, we propose Residual Connection Prompting (RESPROMPT), a new prompting strategy that advances multi-step reasoning in LLMs. Our key idea is to reconstruct the reasoning graph within prompts. We achieve this by integrating necessary connections-links present in the reasoning graph but missing in the linear CoT flow-into the prompts. Termed "residual connections", these links are pivotal in morphing the linear CoT structure into a graph representation, effectively capturing the complex reasoning graphs inherent in multi-step problems. We evaluate RESPROMPT on six benchmarks across three diverse domains: math, sequential, and commonsense reasoning. For the open-sourced LLaMA family of models, RESPROMPT yields a significant average reasoning accuracy improvement of 12.5% on LLaMA-65B and 6.8% on LLaMA2-70B. Breakdown analysis further highlights RESPROMPT particularly excels in complex multi-step reasoning: for questions demanding at least five reasoning steps, RESPROMPT outperforms the best CoT based benchmarks by a remarkable average improvement of 21.1% on LLaMA-65B and 14.3% on LLaMA2-70B. Through extensive ablation studies and analyses, we pinpoint how to most effectively build residual connections.
Are Machine Rationales (Not) Useful to Humans? Measuring and Improving Human Utility of Free-Text Rationales
May 11, 2023



Among the remarkable emergent capabilities of large language models (LMs) is free-text rationalization; beyond a certain scale, large LMs are capable of generating seemingly useful rationalizations, which in turn, can dramatically enhance their performances on leaderboards. This phenomenon raises a question: can machine generated rationales also be useful for humans, especially when lay humans try to answer questions based on those machine rationales? We observe that human utility of existing rationales is far from satisfactory, and expensive to estimate with human studies. Existing metrics like task performance of the LM generating the rationales, or similarity between generated and gold rationales are not good indicators of their human utility. While we observe that certain properties of rationales like conciseness and novelty are correlated with their human utility, estimating them without human involvement is challenging. We show that, by estimating a rationale's helpfulness in answering similar unseen instances, we can measure its human utility to a better extent. We also translate this finding into an automated score, GEN-U, that we propose, which can help improve LMs' ability to generate rationales with better human utility, while maintaining most of its task performance. Lastly, we release all code and collected data with this project.
KNIFE: Knowledge Distillation with Free-Text Rationales
Dec 19, 2022Free-text rationales (FTRs) follow how humans communicate by explaining reasoning processes via natural language. A number of recent works have studied how to improve language model (LM) generalization by using FTRs to teach LMs the correct reasoning processes behind correct task outputs. These prior works aim to learn from FTRs by appending them to the LM input or target output, but this may introduce an input distribution shift or conflict with the task objective, respectively. We propose KNIFE, which distills FTR knowledge from an FTR-augmented teacher LM (takes both task input and FTR) to a student LM (takes only task input), which is used for inference. Crucially, the teacher LM's forward computation has a bottleneck stage in which all of its FTR states are masked out, which pushes knowledge from the FTR states into the task input/output states. Then, FTR knowledge is distilled to the student LM by training its task input/output states to align with the teacher LM's. On two question answering datasets, we show that KNIFE significantly outperforms existing FTR learning methods, in both fully-supervised and low-resource settings.
PINTO: Faithful Language Reasoning Using Prompt-Generated Rationales
Nov 03, 2022Neural language models (LMs) have achieved impressive results on various language-based reasoning tasks by utilizing latent knowledge encoded in their own pretrained parameters. To make this reasoning process more explicit, recent works retrieve a rationalizing LM's internal knowledge by training or prompting it to generate free-text rationales, which can be used to guide task predictions made by either the same LM or a separate reasoning LM. However, rationalizing LMs require expensive rationale annotation and/or computation, without any assurance that their generated rationales improve LM task performance or faithfully reflect LM decision-making. In this paper, we propose PINTO, an LM pipeline that rationalizes via prompt-based learning, and learns to faithfully reason over rationales via counterfactual regularization. First, PINTO maps out a suitable reasoning process for the task input by prompting a frozen rationalizing LM to generate a free-text rationale. Second, PINTO's reasoning LM is fine-tuned to solve the task using the generated rationale as context, while regularized to output less confident predictions when the rationale is perturbed. Across four datasets, we show that PINTO significantly improves the generalization ability of the reasoning LM, yielding higher performance on both in-distribution and out-of-distribution test sets. Also, we find that PINTO's rationales are more faithful to its task predictions than those generated by competitive baselines.
XMD: An End-to-End Framework for Interactive Explanation-Based Debugging of NLP Models
Oct 30, 2022NLP models are susceptible to learning spurious biases (i.e., bugs) that work on some datasets but do not properly reflect the underlying task. Explanation-based model debugging aims to resolve spurious biases by showing human users explanations of model behavior, asking users to give feedback on the behavior, then using the feedback to update the model. While existing model debugging methods have shown promise, their prototype-level implementations provide limited practical utility. Thus, we propose XMD: the first open-source, end-to-end framework for explanation-based model debugging. Given task- or instance-level explanations, users can flexibly provide various forms of feedback via an intuitive, web-based UI. After receiving user feedback, XMD automatically updates the model in real time, by regularizing the model so that its explanations align with the user feedback. The new model can then be easily deployed into real-world applications via Hugging Face. Using XMD, we can improve the model's OOD performance on text classification tasks by up to 18%.