 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Dimensional Quality Scoring Framework for Decentralized LLM Inference with Proof of Quality
Mar 04, 2026Decentralized large language model (LLM) inference networks can pool heterogeneous compute to scale serving, but they require lightweight and incentive-compatible mechanisms to assess output quality. Prior work introduced cost-aware Proof of Quality (PoQ) and adaptive robust PoQ to allocate rewards under evaluator heterogeneity and adversarial behavior. In this paper, we focus on the quality signal itself and propose a multi-dimensional quality scoring framework that decomposes output quality into modular dimensions, including model and cost priors, structure quality, semantic quality, query-output alignment, and agreement/uncertainty. Using logged outputs from QA and summarization tasks, we systematically audit dimension reliability and show that seemingly reasonable dimensions can be task-dependent and even negatively correlated with reference quality without calibration. While the default composite underperforms a strong single semantic evaluator, ablations reveal that removing unreliable dimensions and re-normalizing weights yields a calibrated composite that matches or exceeds the best single- evaluator and consensus baselines. Finally, we integrate the composite score as a drop-in quality signal in PoQ and demonstrate complementary benefits with robust aggregation and adaptive trust weighting under adversarial evaluator attacks.
Adaptive and Robust Cost-Aware Proof of Quality for Decentralized LLM Inference Networks
Jan 29, 2026Decentralized large language model inference networks require lightweight mechanisms to reward high quality outputs under heterogeneous latency and cost. Proof of Quality provides scalable verification by sampling evaluator nodes that score candidate outputs, then aggregating their scores into a consensus signal that determines rewards. However, evaluator heterogeneity and malicious score manipulation can distort consensus and inflate payouts, which weakens incentive alignment in open participation settings. This paper extends a cost-aware Proof of Quality mechanism by adding adversary-resilient consensus formation. We study robust aggregation rules, including median and trimmed mean, and an adaptive trust-weighted consensus that updates evaluator weights from deviation signals. Using question answering and summarization workloads with a ground truth proxy for offline analysis, we quantify evaluator reliability and show strong variance across evaluators, including task-dependent misalignment that can invert correlations. We then evaluate robustness under four adversarial strategies, including noise injection, boosting, sabotage, and intermittent manipulation, across a sweep of malicious ratios and evaluator sample sizes. Our results show that robust aggregation improves consensus alignment with the ground truth proxy and reduces sensitivity to noisy and strategic attacks compared with simple averaging. We further characterize the operational trade-off introduced by evaluator sampling, where larger evaluator sets reduce evaluator rewards and increase payoff variance while inference rewards remain relatively stable in our configuration. These findings motivate robust consensus as a default component for cost-aware Proof of Quality and provide practical guidance for selecting evaluator sampling parameters under adversarial risk and resource constraints.
Design and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
Dec 18, 2025
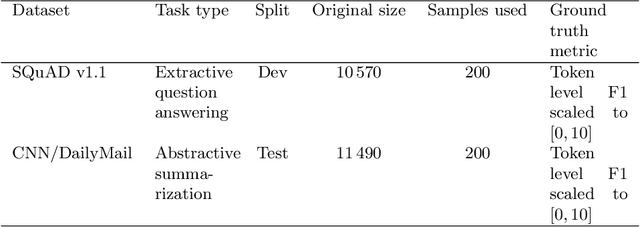


Decentralized large language model (LLM) inference promises transparent and censorship resistant access to advanced AI, yet existing verification approaches struggle to scale to modern models. Proof of Quality (PoQ) replaces cryptographic verification of computation with consensus over output quality, but the original formulation ignores heterogeneous computational costs across inference and evaluator nodes. This paper introduces a cost-aware PoQ framework that integrates explicit efficiency measurements into the reward mechanism for both types of nodes. The design combines ground truth token level F1, lightweight learned evaluators, and GPT based judgments within a unified evaluation pipeline, and adopts a linear reward function that balances normalized quality and cost. Experiments on extractive question answering and abstractive summarization use five instruction tuned LLMs ranging from TinyLlama-1.1B to Llama-3.2-3B and three evaluation models spanning cross encoder and bi encoder architectures. Results show that a semantic textual similarity bi encoder achieves much higher correlation with both ground truth and GPT scores than cross encoders, indicating that evaluator architecture is a critical design choice for PoQ. Quality-cost analysis further reveals that the largest models in the pool are also the most efficient in terms of quality per unit latency. Monte Carlo simulations over 5\,000 PoQ rounds demonstrate that the cost-aware reward scheme consistently assigns higher average rewards to high quality low cost inference models and to efficient evaluators, while penalizing slow low quality nodes. These findings suggest that cost-aware PoQ provides a practical foundation for economically sustainable decentralized LLM inference.