 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Depression Detection: An Emotional Audio-Textual Corpus and a GRU/BiLSTM-based Model
Feb 15, 2022

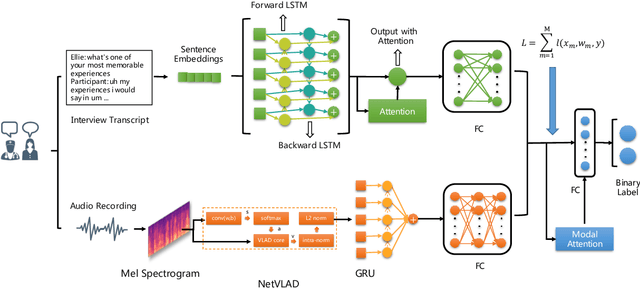

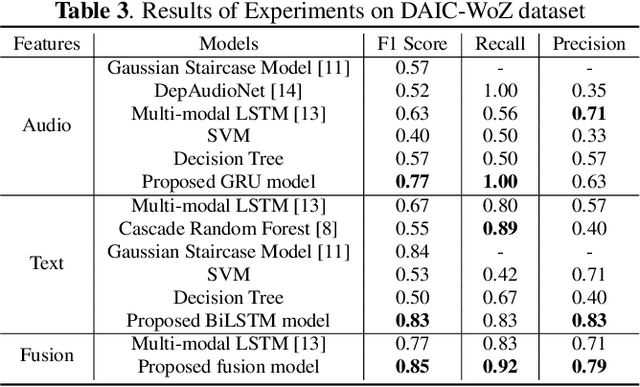
Depression is a global mental health problem, the worst case of which can lead to suicide. An automatic depression detection system provides great help in facilitating depression self-assessment and improving diagnostic accuracy. In this work, we propose a novel depression detection approach utilizing speech characteristics and linguistic contents from participants' interviews. In addition, we establish an Emotional Audio-Textual Depression Corpus (EATD-Corpus) which contains audios and extracted transcripts of responses from depressed and non-depressed volunteers. To the best of our knowledge, EATD-Corpus is the first and only public depression dataset that contains audio and text data in Chinese. Evaluated on two depression datasets, the proposed method achieves the state-of-the-art performances. The outperforming results demonstrate the effectiveness and generalization ability of the proposed method. The source code and EATD-Corpus are available at https://github.com/speechandlanguageprocessing/ICASSP2022-Depression.
Generative Adversarial Networks for Unpaired Voice Transformation on Impaired Speech
Oct 30, 2018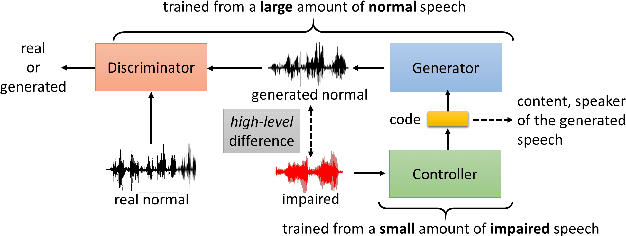
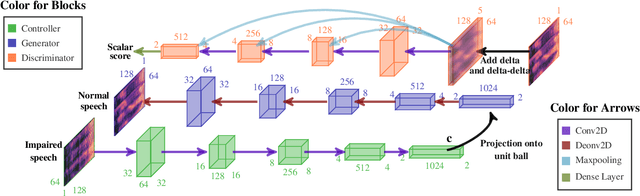

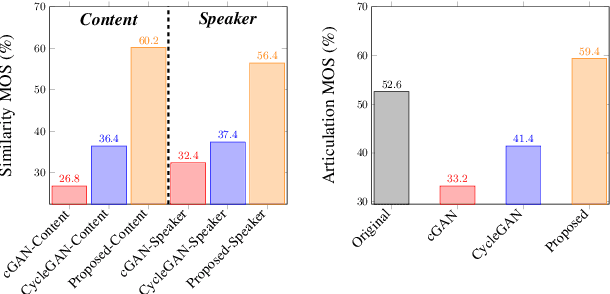
This paper focuses on using voice conversion (VC) to improve the speech intelligibility of surgical patients who have had parts of their articulators removed. Due to the difficulty of data collection, VC without parallel data is highly desired. Although techniques for unparallel VC, for example, CycleGAN, have been developed, they usually focus on transforming the speaker identity, and directly transforming the speech of one speaker to that of another speaker and as such do not address the task here. In this paper, we propose a new approach for unparallel VC. The proposed approach transforms impaired speech to normal speech while preserving the linguistic content and speaker characteristics. To our knowledge, this is the first end-to-end GAN-based unsupervised VC model applied to impaired speech. The experimental results show that the proposed approach outperforms CycleGAN.
KBCNMUJAL@HASOC-Dravidian-CodeMix-FIRE2020: Using Machine Learning for Detection of Hate Speech and Offensive Code-Mixed Social Media text
Feb 19, 2021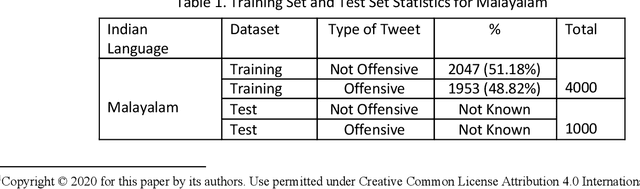
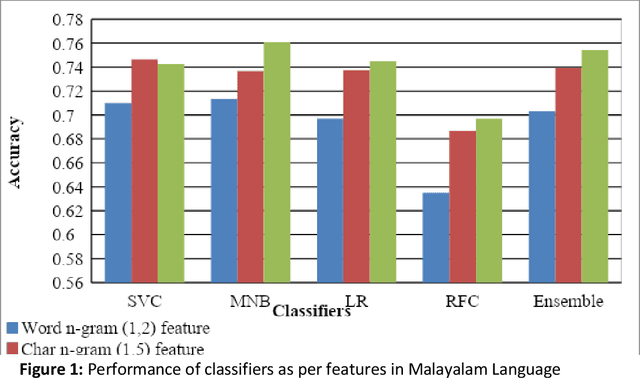

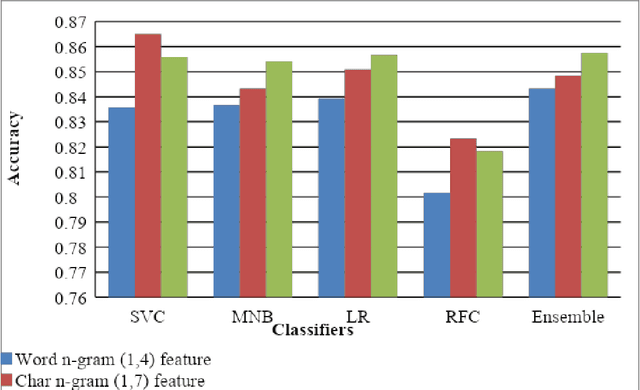
This paper describes the system submitted by our team, KBCNMUJAL, for Task 2 of the shared task Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC), at Forum for Information Retrieval Evaluation, December 16-20, 2020, Hyderabad, India. The datasets of two Dravidian languages Viz. Malayalam and Tamil of size 4000 observations, each were shared by the HASOC organizers. These datasets are used to train the machine using different machine learning algorithms, based on classification and regression models. The datasets consist of tweets or YouTube comments with two class labels offensive and not offensive. The machine is trained to classify such social media messages in these two categories. Appropriate n-gram feature sets are extracted to learn the specific characteristics of the Hate Speech text messages. These feature models are based on TFIDF weights of n-gram. The referred work and respective experiments show that the features such as word, character and combined model of word and character n-grams could be used to identify the term patterns of offensive text contents. As a part of the HASOC shared task, the test data sets are made available by the HASOC track organizers. The best performing classification models developed for both languages are applied on test datasets. The model which gives the highest accuracy result on training dataset for Malayalam language was experimented to predict the categories of respective test data. This system has obtained an F1 score of 0.77. Similarly the best performing model for Tamil language has obtained an F1 score of 0.87. This work has received 2nd and 3rd rank in this shared Task 2 for Malayalam and Tamil language respectively. The proposed system is named HASOC_kbcnmujal.
Introducing the ICBe Dataset: Very High Recall and Precision Event Extraction from Narratives about International Crises
Feb 14, 2022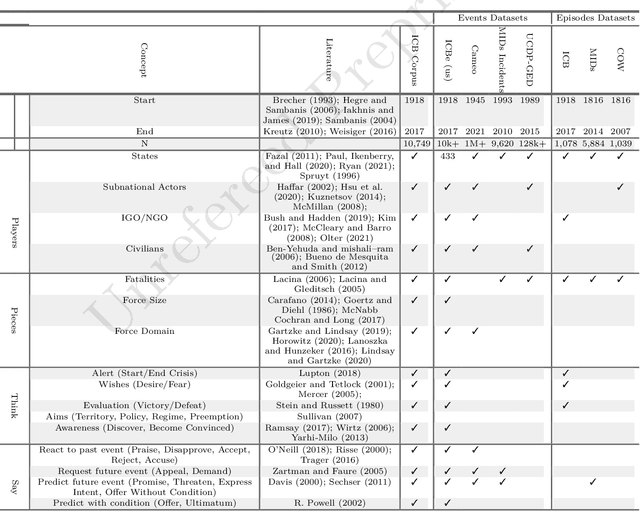
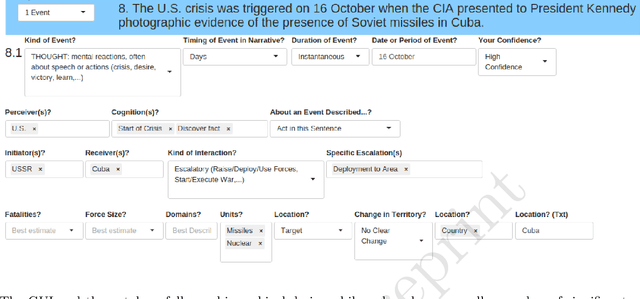
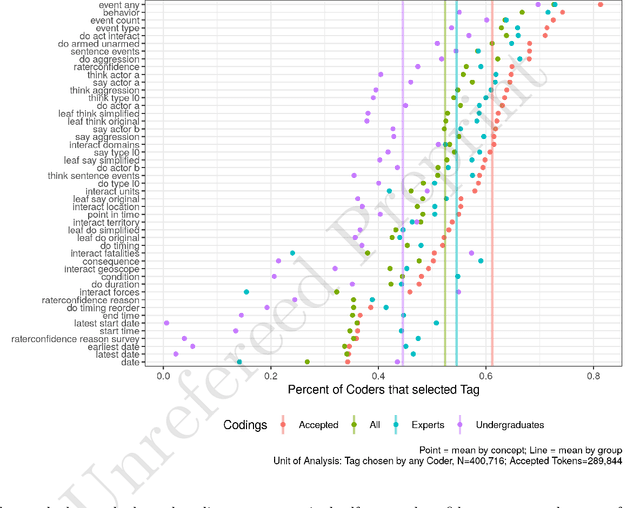
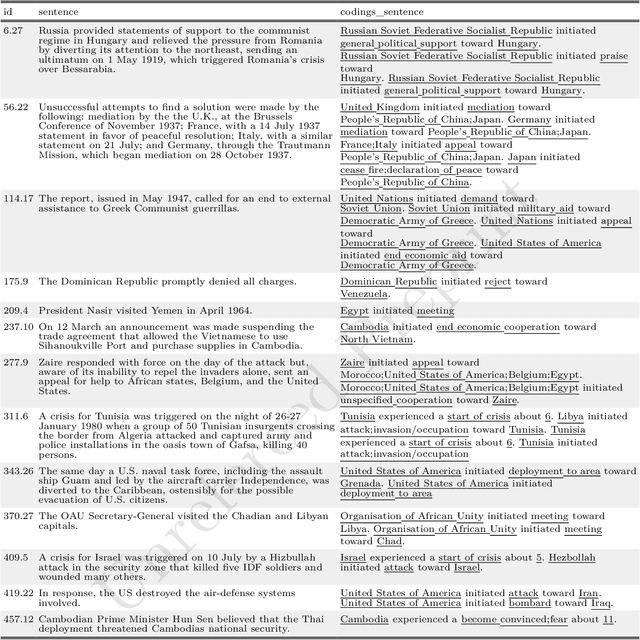
How do international crises unfold? We conceive of international affairs as a strategic chess game between adversaries, necessitating a systematic way to measure pieces, moves, and gambits accurately and consistently over different contexts and periods. We develop such a measurement strategy with an ontology of crisis actions and interactions and apply it to a high-quality corpus of crisis narratives recorded by the International Crisis Behavior (ICB) Project. We demonstrate that the ontology has high coverage over most of the thoughts, speech, and actions contained in these narratives and produces high inter-coder agreement when applied by human coders. We introduce a new crisis event dataset ICB Events (ICBe). We find that ICBe captures the process of a crisis with greater accuracy and granularity than other well-regarded events or crisis datasets. We make the data, replication material, and additional visualizations available at a companion website www.crisisevents.org.
Visual Acoustic Matching
Feb 14, 2022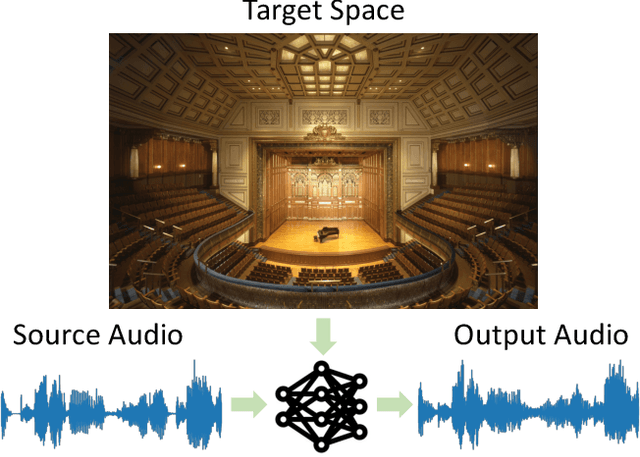
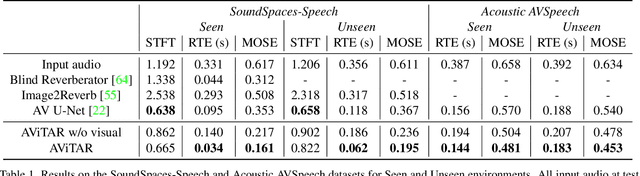

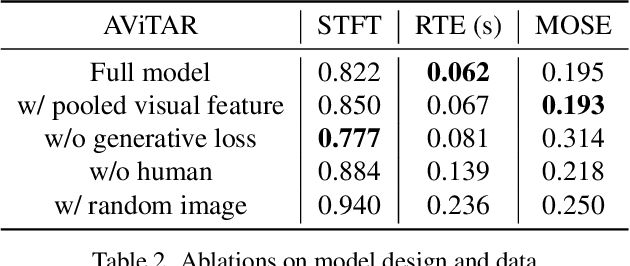
We introduce the visual acoustic matching task, in which an audio clip is transformed to sound like it was recorded in a target environment. Given an image of the target environment and a waveform for the source audio, the goal is to re-synthesize the audio to match the target room acoustics as suggested by its visible geometry and materials. To address this novel task, we propose a cross-modal transformer model that uses audio-visual attention to inject visual properties into the audio and generate realistic audio output. In addition, we devise a self-supervised training objective that can learn acoustic matching from in-the-wild Web videos, despite their lack of acoustically mismatched audio. We demonstrate that our approach successfully translates human speech to a variety of real-world environments depicted in images, outperforming both traditional acoustic matching and more heavily supervised baselines.
Dialog-context aware end-to-end speech recognition
Aug 07, 2018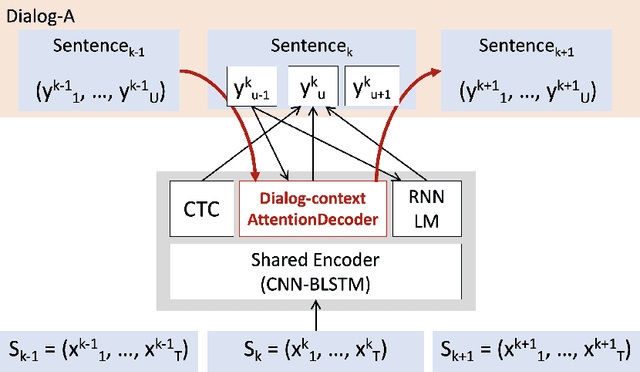

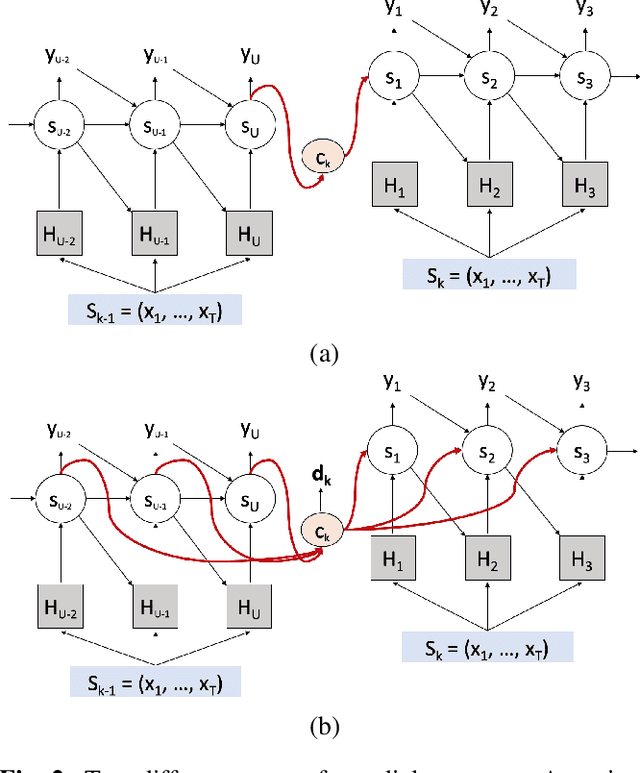

Existing speech recognition systems are typically built at the sentence level, although it is known that dialog context, e.g. higher-level knowledge that spans across sentences or speakers, can help the processing of long conversations. The recent progress in end-to-end speech recognition systems promises to integrate all available information (e.g. acoustic, language resources) into a single model, which is then jointly optimized. It seems natural that such dialog context information should thus also be integrated into the end-to-end models to improve further recognition accuracy. In this work, we present a dialog-context aware speech recognition model, which explicitly uses context information beyond sentence-level information, in an end-to-end fashion. Our dialog-context model captures a history of sentence-level context so that the whole system can be trained with dialog-context information in an end-to-end manner. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a comparable sentence-level end-to-end speech recognition system.
Visualization and Interpretation of Latent Spaces for Controlling Expressive Speech Synthesis through Audio Analysis
Mar 27, 2019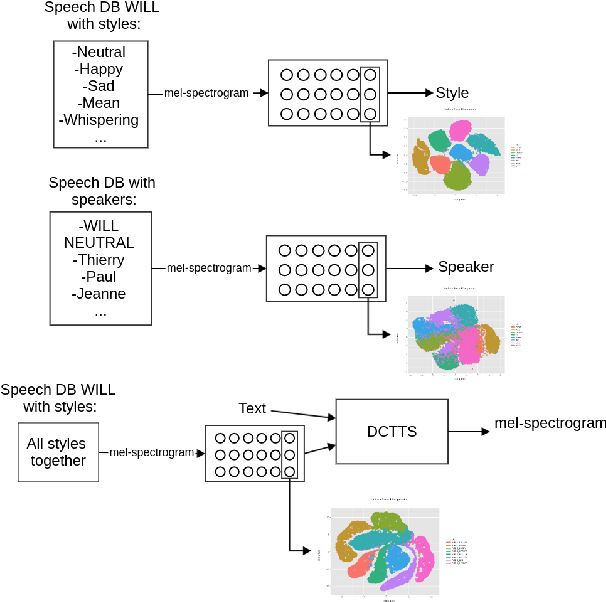
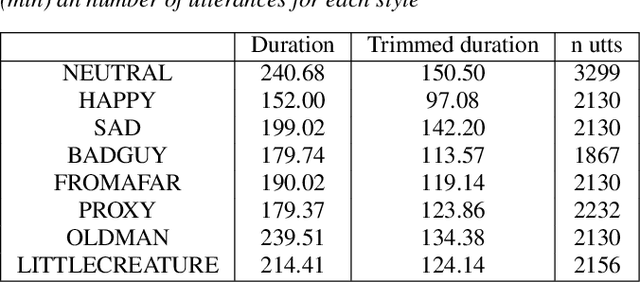
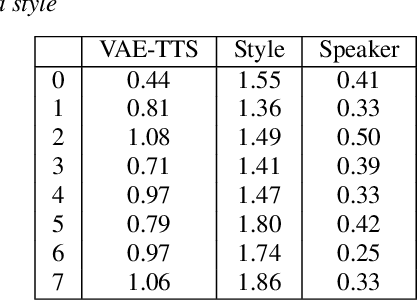
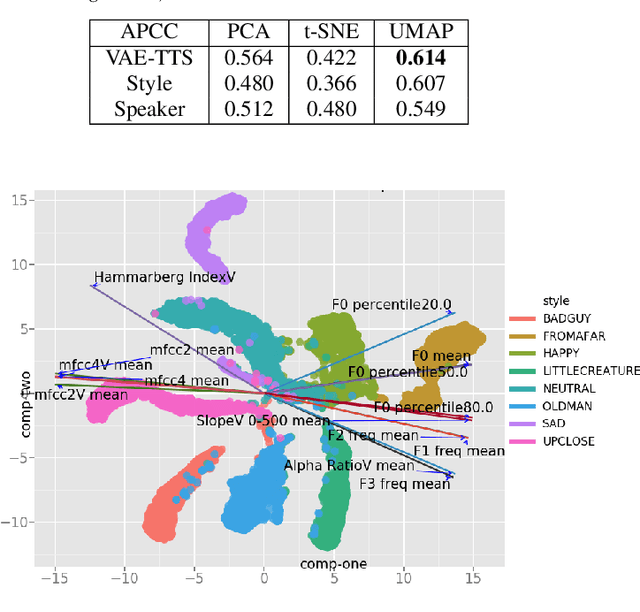
The field of Text-to-Speech has experienced huge improvements last years benefiting from deep learning techniques. Producing realistic speech becomes possible now. As a consequence, the research on the control of the expressiveness, allowing to generate speech in different styles or manners, has attracted increasing attention lately. Systems able to control style have been developed and show impressive results. However the control parameters often consist of latent variables and remain complex to interpret. In this paper, we analyze and compare different latent spaces and obtain an interpretation of their influence on expressive speech. This will enable the possibility to build controllable speech synthesis systems with an understandable behaviour.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 25, 2020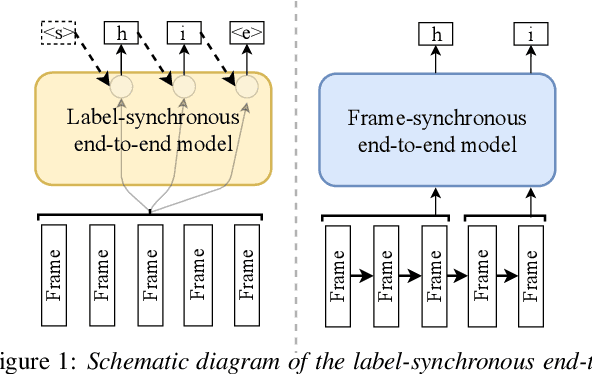

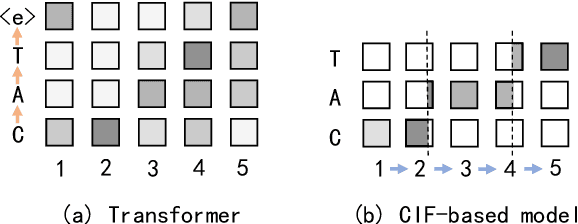
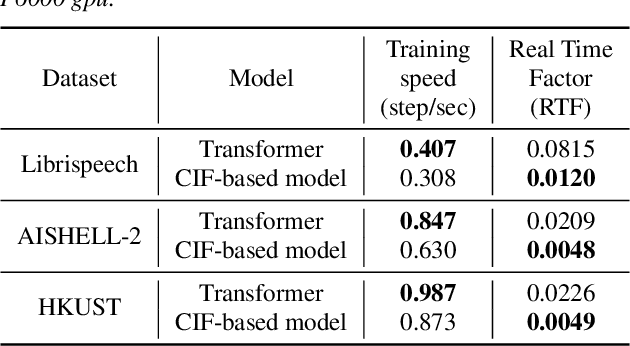
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.
On using 2D sequence-to-sequence models for speech recognition
Nov 20, 2019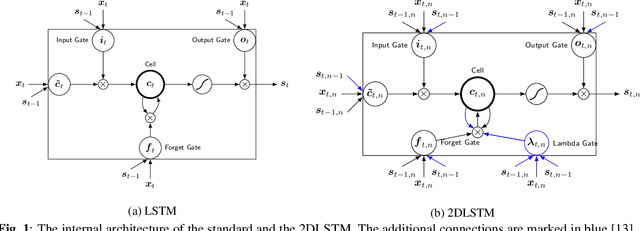

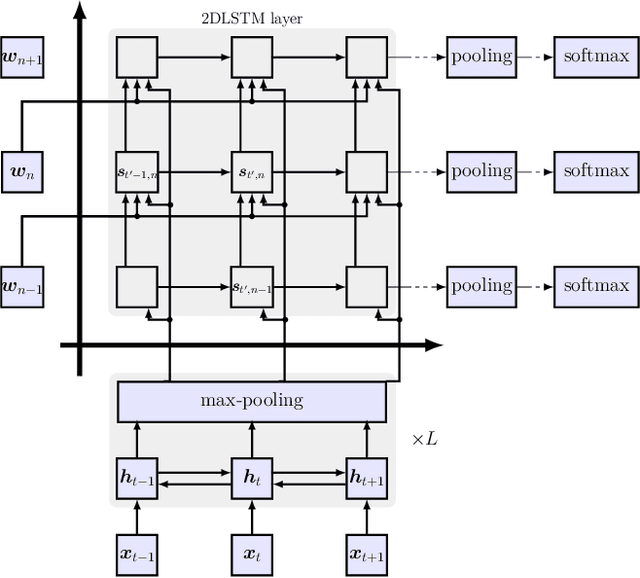
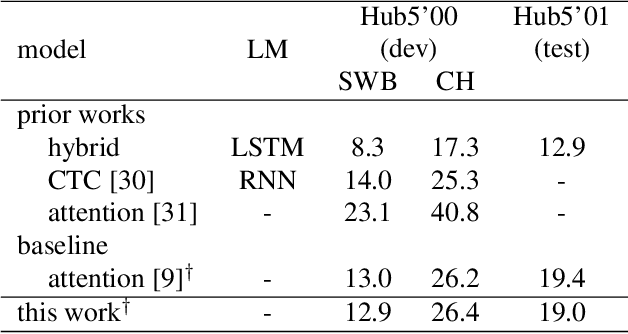
Attention-based sequence-to-sequence models have shown promising results in automatic speech recognition. Using these architectures, one-dimensional input and output sequences are related by an attention approach, thereby replacing more explicit alignment processes, like in classical HMM-based modeling. In contrast, here we apply a novel two-dimensional long short-term memory (2DLSTM) architecture to directly model the input/output relation between audio/feature vector sequences and word sequences. The proposed model is an alternative model such that instead of using any type of attention components, we apply a 2DLSTM layer to assimilate the context from both input observations and output transcriptions. The experimental evaluation on the Switchboard 300h automatic speech recognition task shows word error rates for the 2DLSTM model that are competitive to end-to-end attention-based model.
Channel-Attention Dense U-Net for Multichannel Speech Enhancement
Jan 30, 2020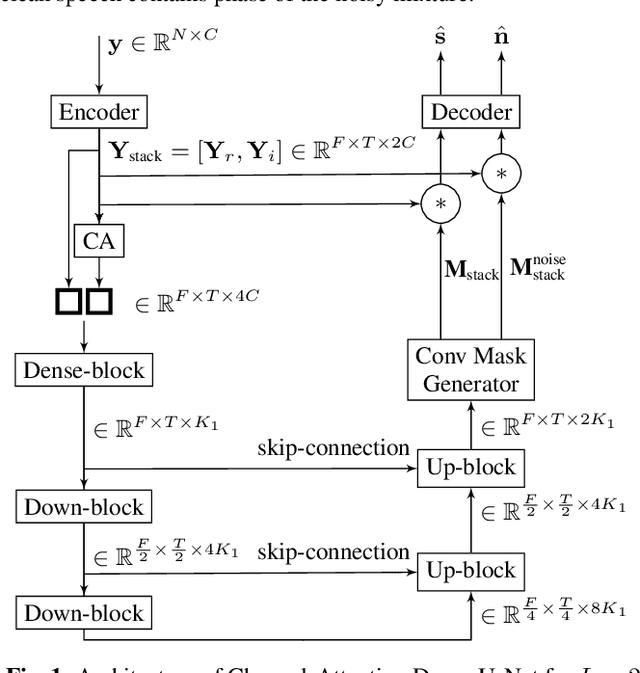
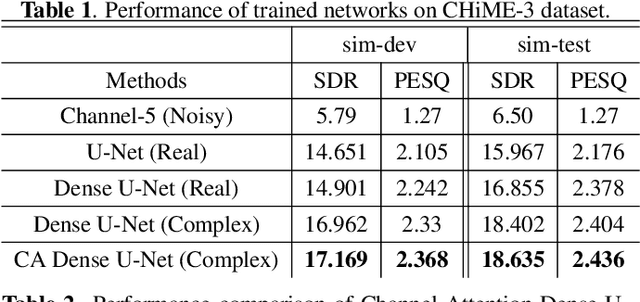
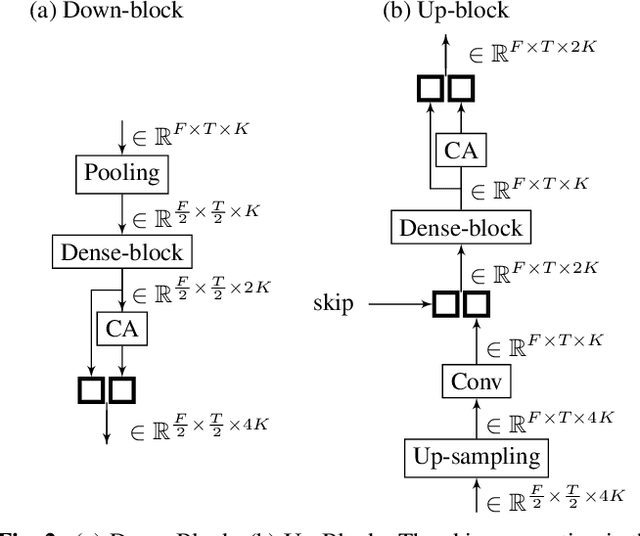
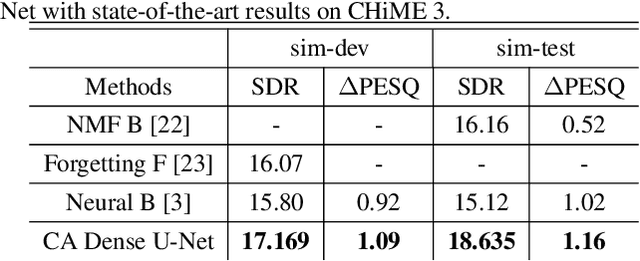
Supervised deep learning has gained significant attention for speech enhancement recently. The state-of-the-art deep learning methods perform the task by learning a ratio/binary mask that is applied to the mixture in the time-frequency domain to produce the clean speech. Despite the great performance in the single-channel setting, these frameworks lag in performance in the multichannel setting as the majority of these methods a) fail to exploit the available spatial information fully, and b) still treat the deep architecture as a black box which may not be well-suited for multichannel audio processing. This paper addresses these drawbacks, a) by utilizing complex ratio masking instead of masking on the magnitude of the spectrogram, and more importantly, b) by introducing a channel-attention mechanism inside the deep architecture to mimic beamforming. We propose Channel-Attention Dense U-Net, in which we apply the channel-attention unit recursively on feature maps at every layer of the network, enabling the network to perform non-linear beamforming. We demonstrate the superior performance of the network against the state-of-the-art approaches on the CHiME-3 dataset.