 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurate-Train-Refine: A Closed-Loop Agentic Framework for Zero Shot Classification
Jan 23, 2026Large language models (LLMs) and high-capacity encoders have advanced zero and few-shot classification, but their inference cost and latency limit practical deployment. We propose training lightweight text classifiers using dynamically generated supervision from an LLM. Our method employs an iterative, agentic loop in which the LLM curates training data, analyzes model successes and failures, and synthesizes targeted examples to address observed errors. This closed-loop generation and evaluation process progressively improves data quality and adapts it to the downstream classifier and task. Across four widely used benchmarks, our approach consistently outperforms standard zero and few-shot baselines. These results indicate that LLMs can serve effectively as data curators, enabling accurate and efficient classification without the operational cost of large-model deployment.
Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice
Aug 24, 2025Human social behaviors are inherently multimodal necessitating the development of powerful audiovisual models for their perception. In this paper, we present Social-MAE, our pre-trained audiovisual Masked Autoencoder based on an extended version of Contrastive Audio-Visual Masked Auto-Encoder (CAV-MAE), which is pre-trained on audiovisual social data. Specifically, we modify CAV-MAE to receive a larger number of frames as input and pre-train it on a large dataset of human social interaction (VoxCeleb2) in a self-supervised manner. We demonstrate the effectiveness of this model by finetuning and evaluating the model on different social and affective downstream tasks, namely, emotion recognition, laughter detection and apparent personality estimation. The model achieves state-of-the-art results on multimodal emotion recognition and laughter recognition and competitive results for apparent personality estimation, demonstrating the effectiveness of in-domain self-supervised pre-training. Code and model weight are available here https://github.com/HuBohy/SocialMAE.
* 5 pages, 3 figures, IEEE FG 2024 conference
ASR Benchmarking: Need for a More Representative Conversational Dataset
Sep 18, 2024



Automatic Speech Recognition (ASR) systems have achieved remarkable performance on widely used benchmarks such as LibriSpeech and Fleurs. However, these benchmarks do not adequately reflect the complexities of real-world conversational environments, where speech is often unstructured and contains disfluencies such as pauses, interruptions, and diverse accents. In this study, we introduce a multilingual conversational dataset, derived from TalkBank, consisting of unstructured phone conversation between adults. Our results show a significant performance drop across various state-of-the-art ASR models when tested in conversational settings. Furthermore, we observe a correlation between Word Error Rate and the presence of speech disfluencies, highlighting the critical need for more realistic, conversational ASR benchmarks.
Efficacy of Synthetic Data as a Benchmark
Sep 18, 2024Large language models (LLMs) have enabled a range of applications in zero-shot and few-shot learning settings, including the generation of synthetic datasets for training and testing. However, to reliably use these synthetic datasets, it is essential to understand how representative they are of real-world data. We investigate this by assessing the effectiveness of generating synthetic data through LLM and using it as a benchmark for various NLP tasks. Our experiments across six datasets, and three different tasks, show that while synthetic data can effectively capture performance of various methods for simpler tasks, such as intent classification, it falls short for more complex tasks like named entity recognition. Additionally, we propose a new metric called the bias factor, which evaluates the biases introduced when the same LLM is used to both generate benchmarking data and to perform the tasks. We find that smaller LLMs exhibit biases towards their own generated data, whereas larger models do not. Overall, our findings suggest that the effectiveness of synthetic data as a benchmark varies depending on the task, and that practitioners should rely on data generated from multiple larger models whenever possible.
A New Perspective on Smiling and Laughter Detection: Intensity Levels Matter
Mar 04, 2024



Smiles and laughs detection systems have attracted a lot of attention in the past decade contributing to the improvement of human-agent interaction systems. But very few considered these expressions as distinct, although no prior work clearly proves them to belong to the same category or not. In this work, we present a deep learning-based multimodal smile and laugh classification system, considering them as two different entities. We compare the use of audio and vision-based models as well as a fusion approach. We show that, as expected, the fusion leads to a better generalization on unseen data. We also present an in-depth analysis of the behavior of these models on the smiles and laughs intensity levels. The analyses on the intensity levels show that the relationship between smiles and laughs might not be as simple as a binary one or even grouping them in a single category, and so, a more complex approach should be taken when dealing with them. We also tackle the problem of limited resources by showing that transfer learning allows the models to improve the detection of confusing intensity levels.
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs
Feb 20, 2024



Deploying large language models (LLMs) of several billion parameters can be impractical in most industrial use cases due to constraints such as cost, latency limitations, and hardware accessibility. Knowledge distillation (KD) offers a solution by compressing knowledge from resource-intensive large models to smaller ones. Various strategies exist, some relying on the text generated by the teacher model and optionally utilizing his logits to enhance learning. However, these methods based on logits often require both teacher and student models to share the same tokenizer, limiting their applicability across different LLM families. In this paper, we introduce Universal Logit Distillation (ULD) loss, grounded in optimal transport, to address this limitation. Our experimental results demonstrate the effectiveness of ULD loss in enabling distillation across models with different architectures and tokenizers, paving the way to a more widespread use of distillation techniques.
Deep learning-based stereo camera multi-video synchronization
Mar 22, 2023Stereo vision is essential for many applications. Currently, the synchronization of the streams coming from two cameras is done using mostly hardware. A software-based synchronization method would reduce the cost, weight and size of the entire system and allow for more flexibility when building such systems. With this goal in mind, we present here a comparison of different deep learning-based systems and prove that some are efficient and generalizable enough for such a task. This study paves the way to a production ready software-based video synchronization system.
Analysis and Assessment of Controllability of an Expressive Deep Learning-based TTS system
Mar 06, 2021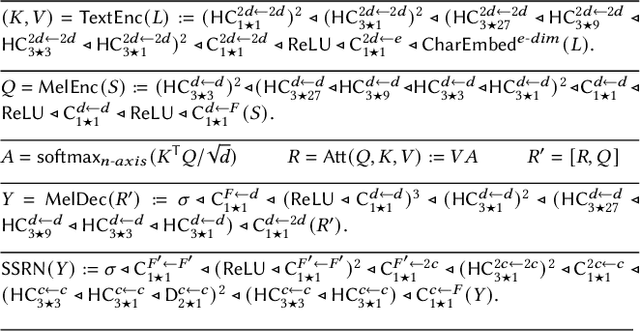


In this paper, we study the controllability of an Expressive TTS system trained on a dataset for a continuous control. The dataset is the Blizzard 2013 dataset based on audiobooks read by a female speaker containing a great variability in styles and expressiveness. Controllability is evaluated with both an objective and a subjective experiment. The objective assessment is based on a measure of correlation between acoustic features and the dimensions of the latent space representing expressiveness. The subjective assessment is based on a perceptual experiment in which users are shown an interface for Controllable Expressive TTS and asked to retrieve a synthetic utterance whose expressiveness subjectively corresponds to that a reference utterance.
ICE-Talk: an Interface for a Controllable Expressive Talking Machine
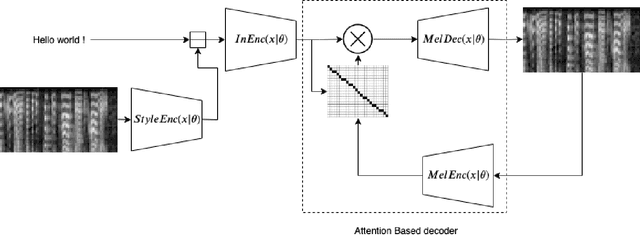
Aug 25, 2020
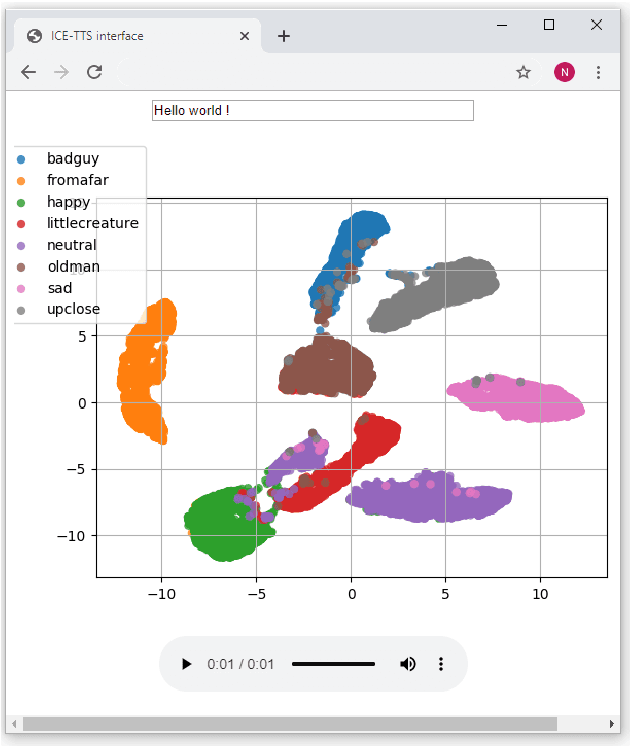
ICE-Talk is an open source web-based GUI that allows the use of a TTS system with controllable parameters via a text field and a clickable 2D plot. It enables the study of latent spaces for controllable TTS. Moreover it is implemented as a module that can be used as part of a Human-Agent interaction.
Laughter Synthesis: Combining Seq2seq modeling with Transfer Learning
Aug 20, 2020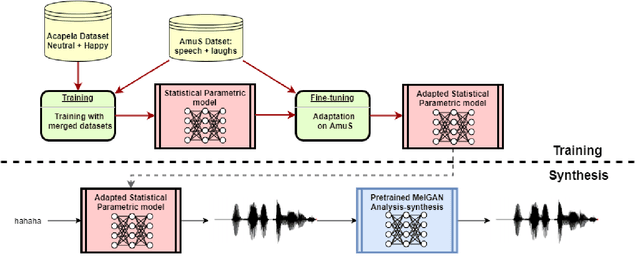
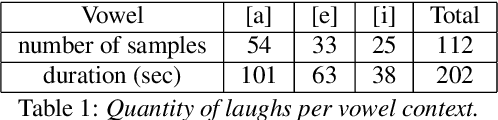
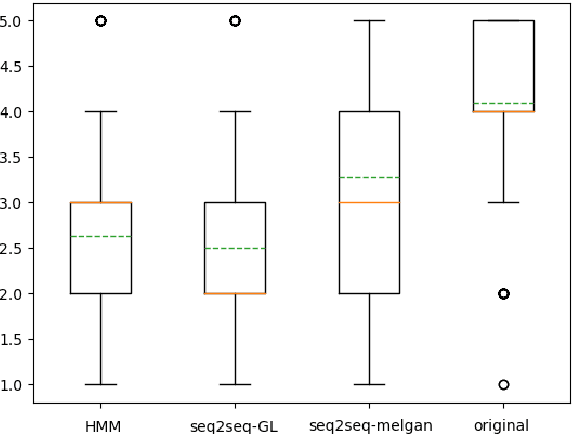
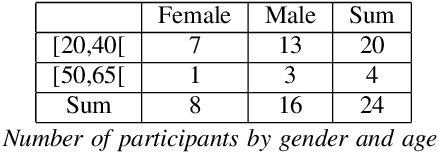
Despite the growing interest for expressive speech synthesis, synthesis of nonverbal expressions is an under-explored area. In this paper we propose an audio laughter synthesis system based on a sequence-to-sequence TTS synthesis system. We leverage transfer learning by training a deep learning model to learn to generate both speech and laughs from annotations. We evaluate our model with a listening test, comparing its performance to an HMM-based laughter synthesis one and assess that it reaches higher perceived naturalness. Our solution is a first step towards a TTS system that would be able to synthesize speech with a control on amusement level with laughter integration.