 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Investigating Active-learning-based Training Data Selection for Speech Spoofing Countermeasure
Mar 28, 2022
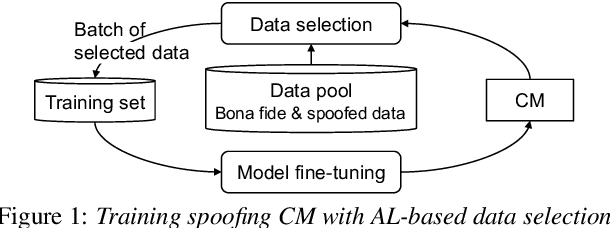
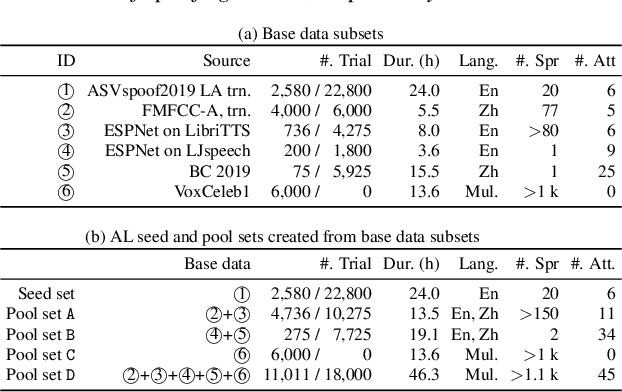
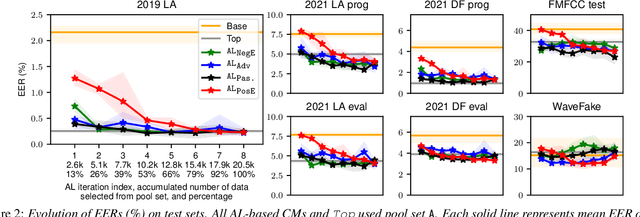
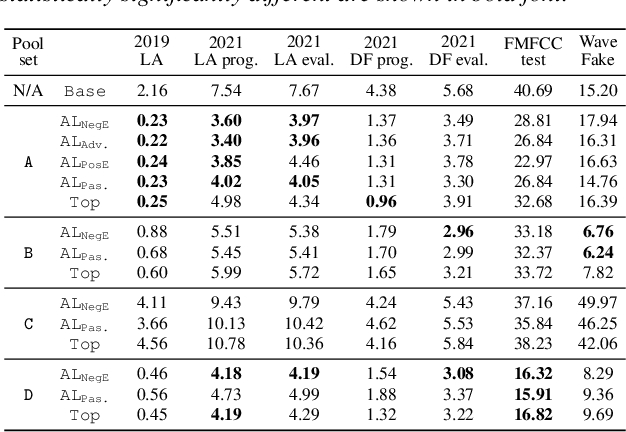
Training a spoofing countermeasure (CM) that generalizes to various unseen data is desired but challenging. While methods such as data augmentation and self-supervised learning are applicable, the imperfect CM performance on diverse test sets still calls for additional strategies. This study took the initiative and investigated CM training using active learning (AL), a framework that iteratively selects useful data from a large pool set and fine-tunes the CM. This study compared a few methods to measure the data usefulness and the impact of using different pool sets collected from various sources. The results showed that the AL-based CMs achieved better generalization than our strong baseline on multiple test tests. Furthermore, compared with a top-line CM that simply used the whole data pool set for training, the AL-based CMs achieved similar performance using less training data. Although no single best configuration was found for AL, the rule of thumb is to include diverse spoof and bona fide data in the pool set and to avoid any AL data selection method that selects the data that the CM feels confident in.
Does Terrorism Trigger Online Hate Speech? On the Association of Events and Time Series
Apr 30, 2020
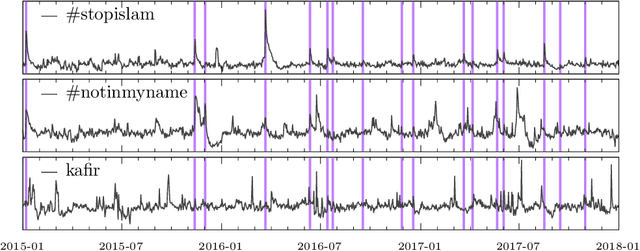
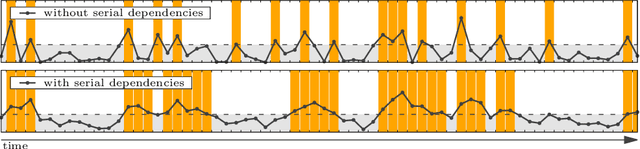
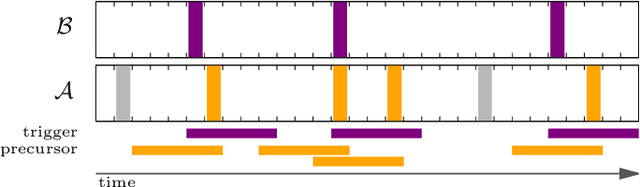
Hate speech is ubiquitous on the Web. Recently, the offline causes that contribute to online hate speech have received increasing attention. A recurring question is whether the occurrence of extreme events offline systematically triggers bursts of hate speech online, indicated by peaks in the volume of hateful social media posts. Formally, this question translates into measuring the association between a sparse event series and a time series. We propose a novel statistical methodology to measure, test and visualize the systematic association between rare events and peaks in a time series. In contrast to previous methods for causal inference or independence tests on time series, our approach focuses only on the timing of events and peaks, and no other distributional characteristics. We follow the framework of event coincidence analysis (ECA) that was originally developed to correlate point processes. We formulate a discrete-time variant of ECA and derive all required distributions to enable analyses of peaks in time series, with a special focus on serial dependencies and peaks over multiple thresholds. The analysis gives rise to a novel visualization of the association via quantile-trigger rate plots. We demonstrate the utility of our approach by analyzing whether Islamist terrorist attacks in Western Europe and North America systematically trigger bursts of hate speech and counter-hate speech on Twitter.
Hate Me Not: Detecting Hate Inducing Memes in Code Switched Languages
Apr 24, 2022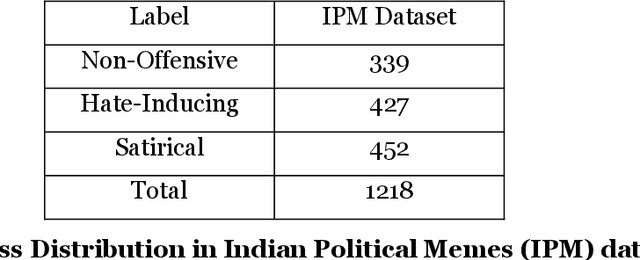


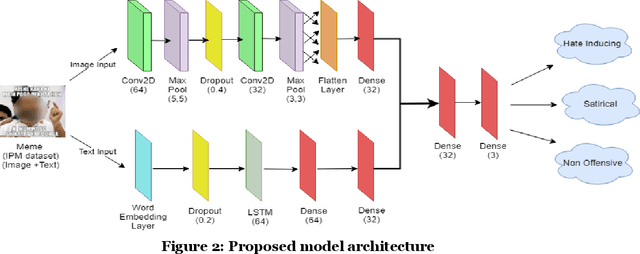
The rise in the number of social media users has led to an increase in the hateful content posted online. In countries like India, where multiple languages are spoken, these abhorrent posts are from an unusual blend of code-switched languages. This hate speech is depicted with the help of images to form "Memes" which create a long-lasting impact on the human mind. In this paper, we take up the task of hate and offense detection from multimodal data, i.e. images (Memes) that contain text in code-switched languages. We firstly present a novel triply annotated Indian political Memes (IPM) dataset, which comprises memes from various Indian political events that have taken place post-independence and are classified into three distinct categories. We also propose a binary-channelled CNN cum LSTM based model to process the images using the CNN model and text using the LSTM model to get state-of-the-art results for this task.
Target Based Speech Act Classification in Political Campaign Text
May 20, 2019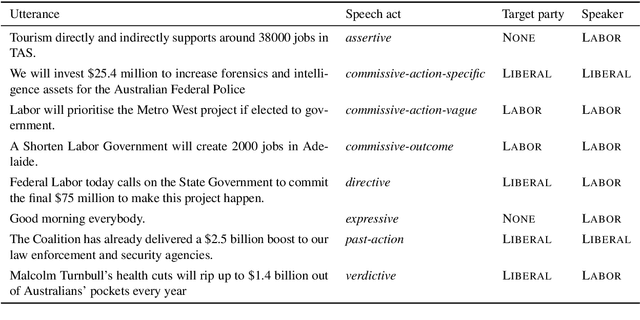
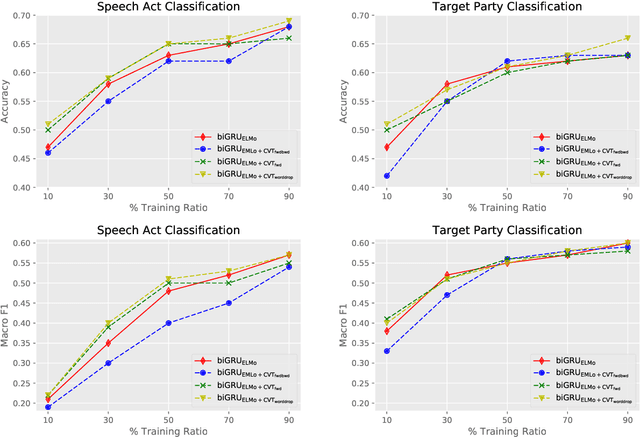

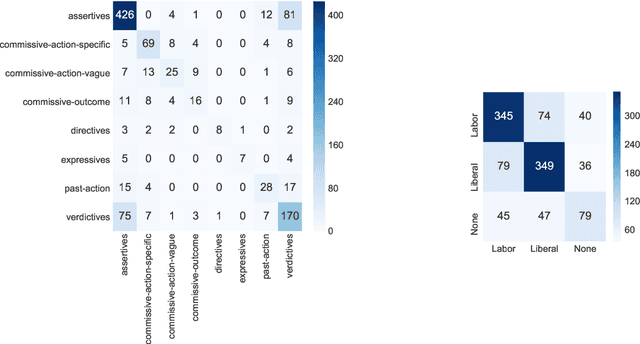
We study pragmatics in political campaign text, through analysis of speech acts and the target of each utterance. We propose a new annotation schema incorporating domain-specific speech acts, such as commissive-action, and present a novel annotated corpus of media releases and speech transcripts from the 2016 Australian election cycle. We show how speech acts and target referents can be modeled as sequential classification, and evaluate several techniques, exploiting contextualized word representations, semi-supervised learning, task dependencies and speaker meta-data.
Moving fast and slow: Analysis of representations and post-processing in speech-driven automatic gesture generation
Jul 16, 2020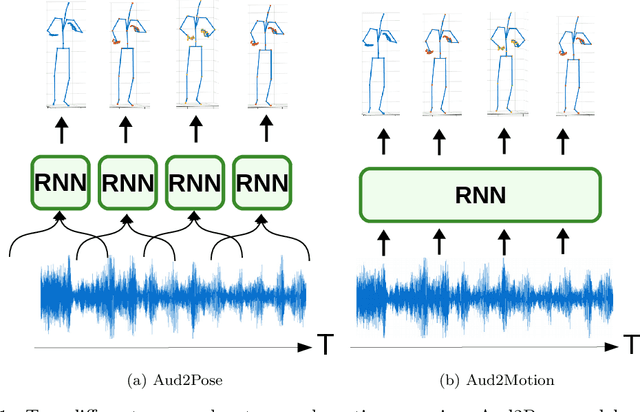
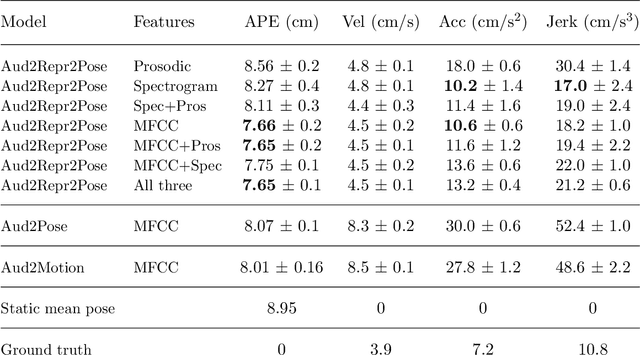


This paper presents a novel framework for speech-driven gesture production, applicable to virtual agents to enhance human-computer interaction. Specifically, we extend recent deep-learning-based, data-driven methods for speech-driven gesture generation by incorporating representation learning. Our model takes speech as input and produces gestures as output, in the form of a sequence of 3D coordinates. We provide an analysis of different representations for the input (speech) and the output (motion) of the network by both objective and subjective evaluations. We also analyse the importance of smoothing of the produced motion. Our results indicated that the proposed method improved on our baseline in terms of objective measures. For example, it better captured the motion dynamics and better matched the motion-speed distribution. Moreover, we performed user studies on two different datasets. The studies confirmed that our proposed method is perceived as more natural than the baseline, although the difference in the studies was eliminated by appropriate post-processing: hip-centering and smoothing. We conclude that it is important to take both feature representation, model architecture and post-processing into account when designing an automatic gesture-production method.
Deep Representation Learning in Speech Processing: Challenges, Recent Advances, and Future Trends
Jan 02, 2020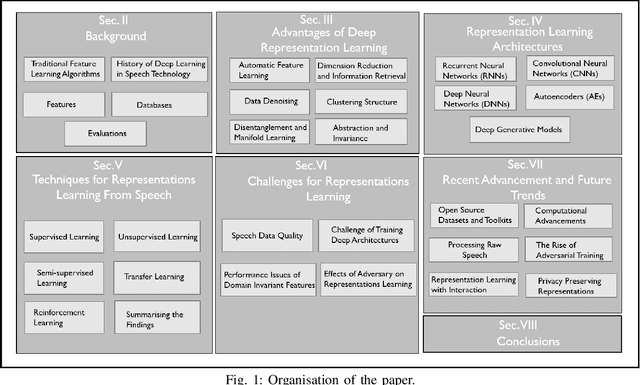
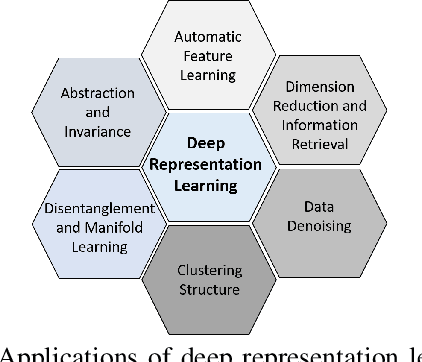
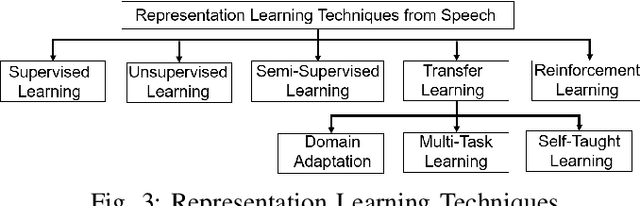
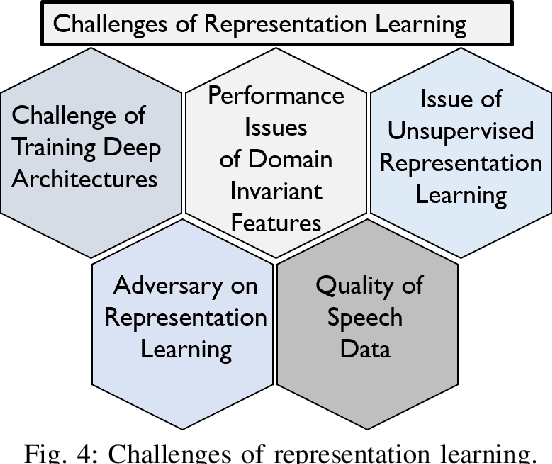
Research on speech processing has traditionally considered the task of designing hand-engineered acoustic features (feature engineering) as a separate distinct problem from the task of designing efficient machine learning (ML) models to make prediction and classification decisions. There are two main drawbacks to this approach: firstly, the feature engineering being manual is cumbersome and requires human knowledge; and secondly, the designed features might not be best for the objective at hand. This has motivated the adoption of a recent trend in speech community towards utilisation of representation learning techniques, which can learn an intermediate representation of the input signal automatically that better suits the task at hand and hence lead to improved performance. The significance of representation learning has increased with advances in deep learning (DL), where the representations are more useful and less dependent on human knowledge, making it very conducive for tasks like classification, prediction, etc. The main contribution of this paper is to present an up-to-date and comprehensive survey on different techniques of speech representation learning by bringing together the scattered research across three distinct research areas including Automatic Speech Recognition (ASR), Speaker Recognition (SR), and Speaker Emotion Recognition (SER). Recent reviews in speech have been conducted for ASR, SR, and SER, however, none of these has focused on the representation learning from speech---a gap that our survey aims to bridge.
SNP2Vec: Scalable Self-Supervised Pre-Training for Genome-Wide Association Study
Apr 14, 2022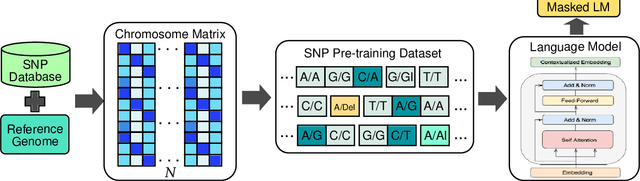
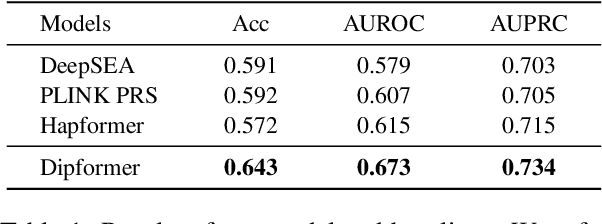
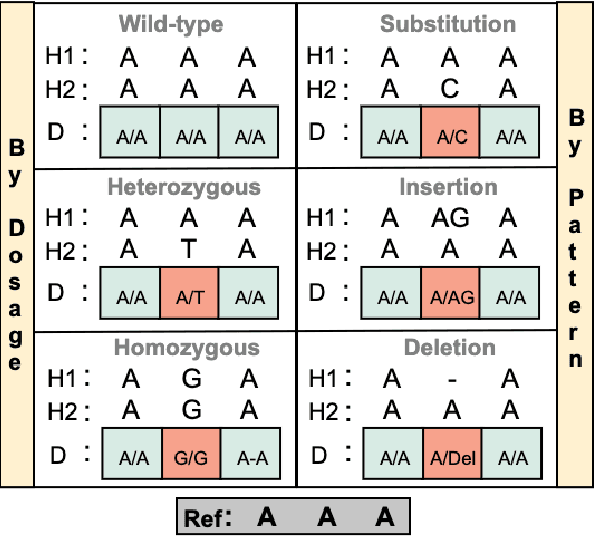

Self-supervised pre-training methods have brought remarkable breakthroughs in the understanding of text, image, and speech. Recent developments in genomics has also adopted these pre-training methods for genome understanding. However, they focus only on understanding haploid sequences, which hinders their applicability towards understanding genetic variations, also known as single nucleotide polymorphisms (SNPs), which is crucial for genome-wide association study. In this paper, we introduce SNP2Vec, a scalable self-supervised pre-training approach for understanding SNP. We apply SNP2Vec to perform long-sequence genomics modeling, and we evaluate the effectiveness of our approach on predicting Alzheimer's disease risk in a Chinese cohort. Our approach significantly outperforms existing polygenic risk score methods and all other baselines, including the model that is trained entirely with haploid sequences. We release our code and dataset on https://github.com/HLTCHKUST/snp2vec.
Investigating Generative Adversarial Networks based Speech Dereverberation for Robust Speech Recognition
Oct 25, 2018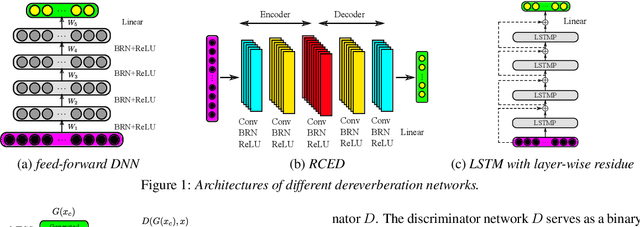
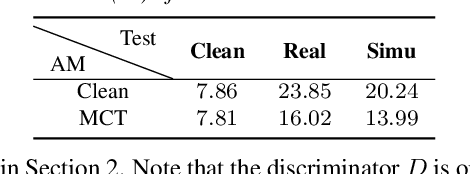
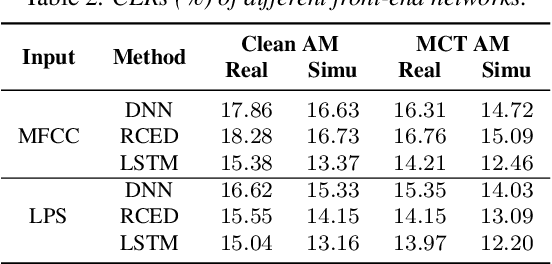
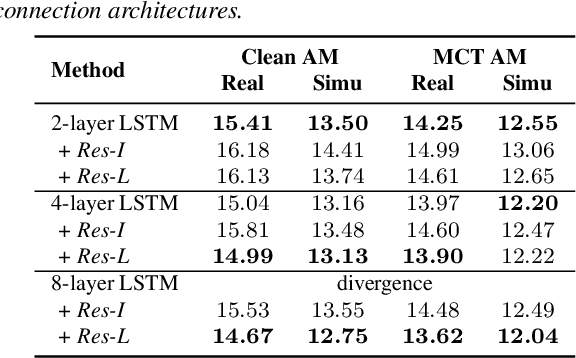
We investigate the use of generative adversarial networks (GANs) in speech dereverberation for robust speech recognition. GANs have been recently studied for speech enhancement to remove additive noises, but there still lacks of a work to examine their ability in speech dereverberation and the advantages of using GANs have not been fully established. In this paper, we provide deep investigations in the use of GAN-based dereverberation front-end in ASR. First, we study the effectiveness of different dereverberation networks (the generator in GAN) and find that LSTM leads a significant improvement as compared with feed-forward DNN and CNN in our dataset. Second, further adding residual connections in the deep LSTMs can boost the performance as well. Finally, we find that, for the success of GAN, it is important to update the generator and the discriminator using the same mini-batch data during training. Moreover, using reverberant spectrogram as a condition to discriminator, as suggested in previous studies, may degrade the performance. In summary, our GAN-based dereverberation front-end achieves 14%-19% relative CER reduction as compared to the baseline DNN dereverberation network when tested on a strong multi-condition training acoustic model.
* Interspeech 2018
Set-based Meta-Interpolation for Few-Task Meta-Learning
May 20, 2022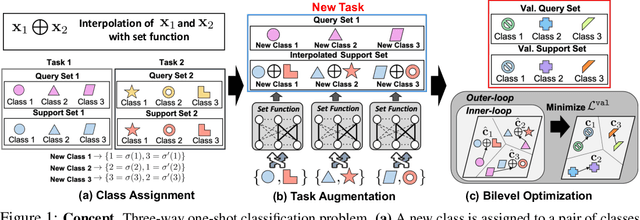
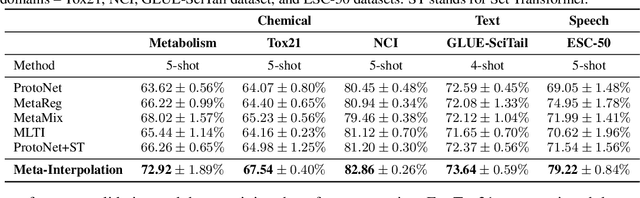
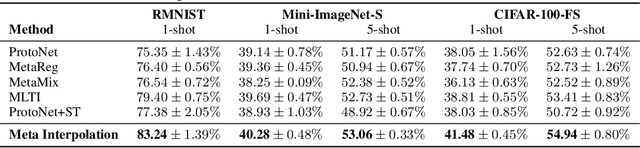
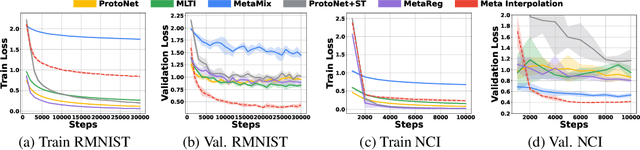
Meta-learning approaches enable machine learning systems to adapt to new tasks given few examples by leveraging knowledge from related tasks. However, a large number of meta-training tasks are still required for generalization to unseen tasks during meta-testing, which introduces a critical bottleneck for real-world problems that come with only few tasks, due to various reasons including the difficulty and cost of constructing tasks. Recently, several task augmentation methods have been proposed to tackle this issue using domain-specific knowledge to design augmentation techniques to densify the meta-training task distribution. However, such reliance on domain-specific knowledge renders these methods inapplicable to other domains. While Manifold Mixup based task augmentation methods are domain-agnostic, we empirically find them ineffective on non-image domains. To tackle these limitations, we propose a novel domain-agnostic task augmentation method, Meta-Interpolation, which utilizes expressive neural set functions to densify the meta-training task distribution using bilevel optimization. We empirically validate the efficacy of Meta-Interpolation on eight datasets spanning across various domains such as image classification, molecule property prediction, text classification and speech recognition. Experimentally, we show that Meta-Interpolation consistently outperforms all the relevant baselines. Theoretically, we prove that task interpolation with the set function regularizes the meta-learner to improve generalization.
Polish Read Speech Corpus for Speech Tools and Services
Jun 01, 2017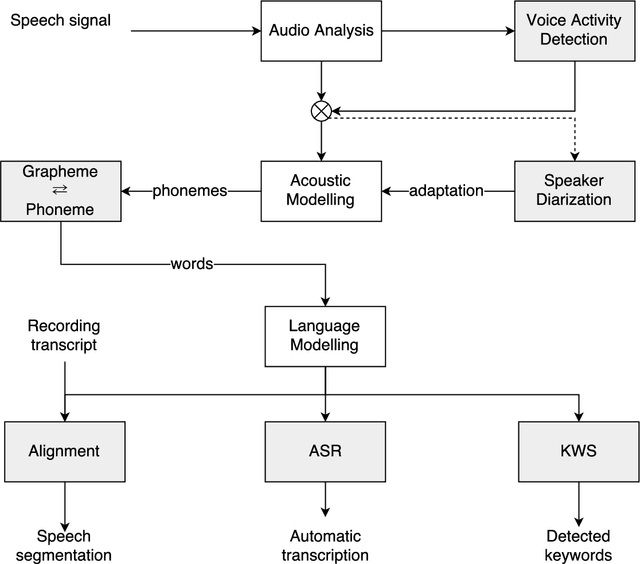


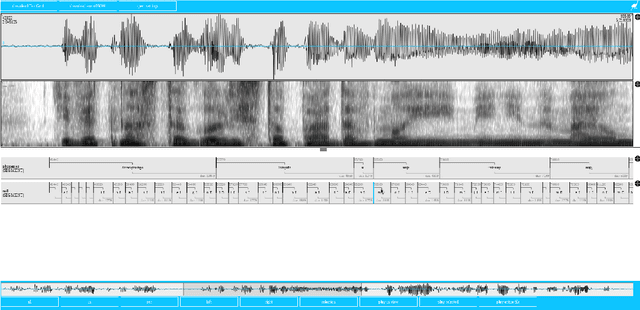
This paper describes the speech processing activities conducted at the Polish consortium of the CLARIN project. The purpose of this segment of the project was to develop specific tools that would allow for automatic and semi-automatic processing of large quantities of acoustic speech data. The tools include the following: grapheme-to-phoneme conversion, speech-to-text alignment, voice activity detection, speaker diarization, keyword spotting and automatic speech transcription. Furthermore, in order to develop these tools, a large high-quality studio speech corpus was recorded and released under an open license, to encourage development in the area of Polish speech research. Another purpose of the corpus was to serve as a reference for studies in phonetics and pronunciation. All the tools and resources were released on the the Polish CLARIN website. This paper discusses the current status and future plans for the project.