 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Active-learning-based Training Data Selection for Speech Spoofing Countermeasure
Mar 28, 2022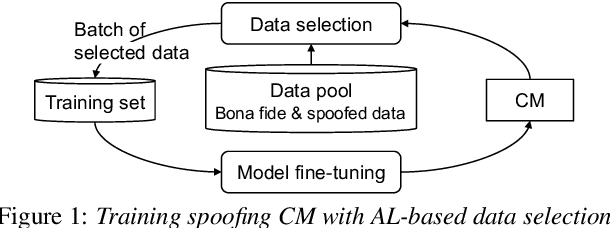
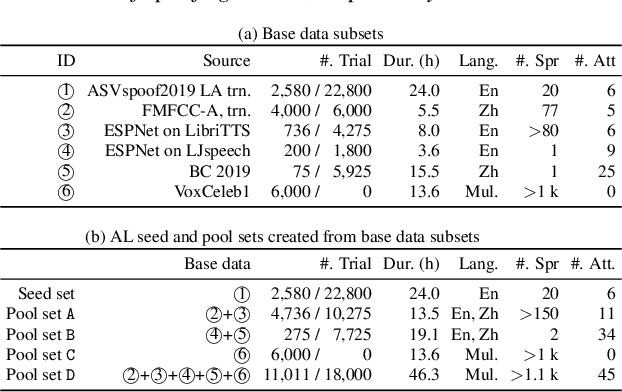
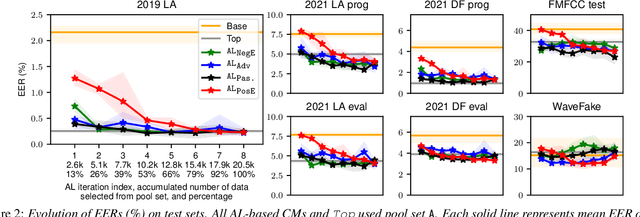
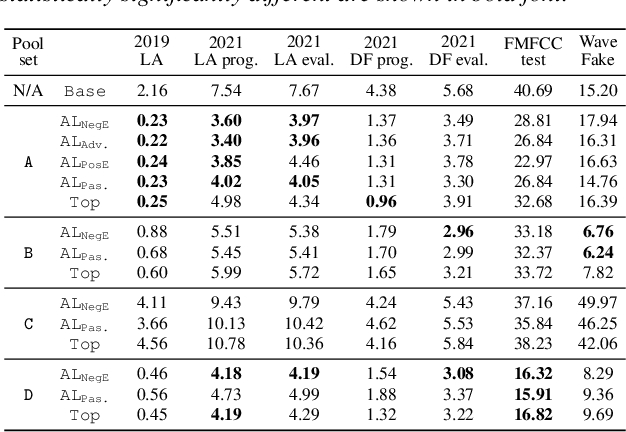
Training a spoofing countermeasure (CM) that generalizes to various unseen data is desired but challenging. While methods such as data augmentation and self-supervised learning are applicable, the imperfect CM performance on diverse test sets still calls for additional strategies. This study took the initiative and investigated CM training using active learning (AL), a framework that iteratively selects useful data from a large pool set and fine-tunes the CM. This study compared a few methods to measure the data usefulness and the impact of using different pool sets collected from various sources. The results showed that the AL-based CMs achieved better generalization than our strong baseline on multiple test tests. Furthermore, compared with a top-line CM that simply used the whole data pool set for training, the AL-based CMs achieved similar performance using less training data. Although no single best configuration was found for AL, the rule of thumb is to include diverse spoof and bona fide data in the pool set and to avoid any AL data selection method that selects the data that the CM feels confident in.
A Comparative Study on Recent Neural Spoofing Countermeasures for Synthetic Speech Detection
Mar 21, 2021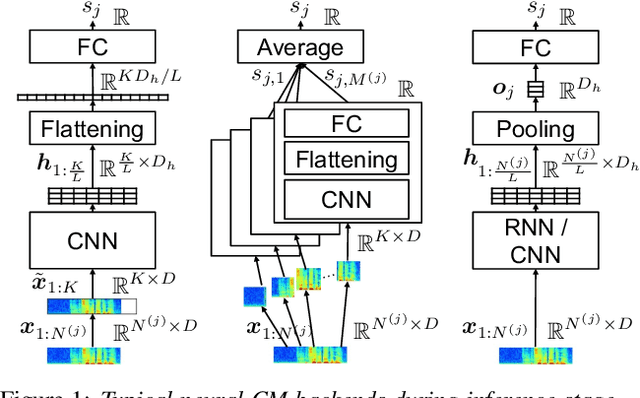
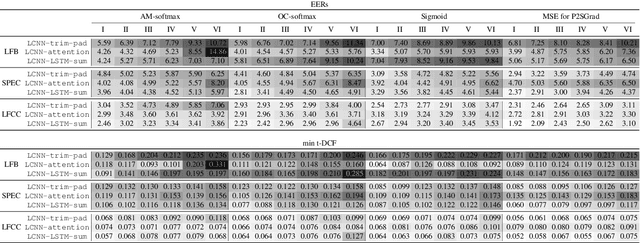
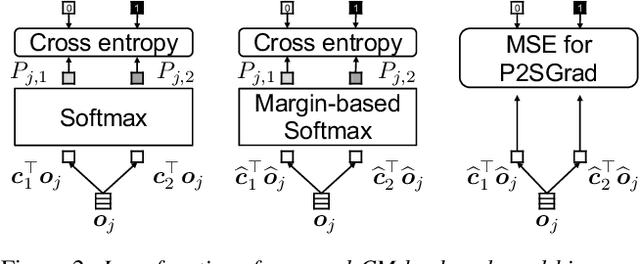
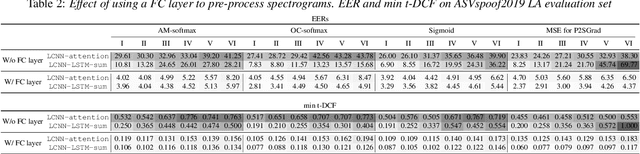
A great deal of recent research effort on speech spoofing countermeasures has been invested into back-end neural networks and training criteria. We contribute to this effort with a comparative perspective in this study. Our comparison of countermeasure models on the ASVspoof 2019 logical access scenario takes into account common strategies to deal with input trials of varied length, recently proposed margin-based training criteria, and widely used front ends. We also measured intra-model differences through multiple training-evaluation rounds with random initialization. Our statistical analysis demonstrates that the performance of the same model may be statistically significantly different when just changing the random initial seed. We thus recommend similar statistical analysis or reporting results of multiple runs for further research on the database. Despite the intra-model differences, we observed a few promising techniques, including average pooling, to efficiently process varied-length inputs and a new hyper-parameter-free loss function. The two techniques led to the best single model in our experiment, which achieved an equal error rate of 1.92% and was significantly different in statistical sense from most of the other experimental models.