 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Unified Deep Speaker Embedding Framework for Mixed-Bandwidth Speech Data
Dec 01, 2020
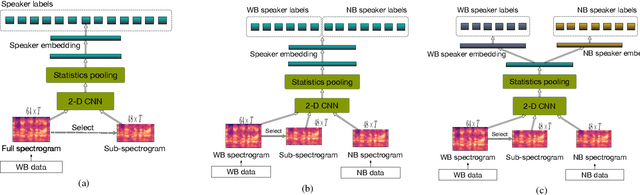
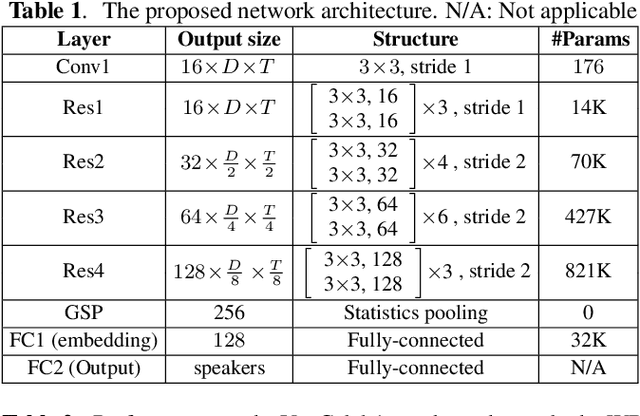
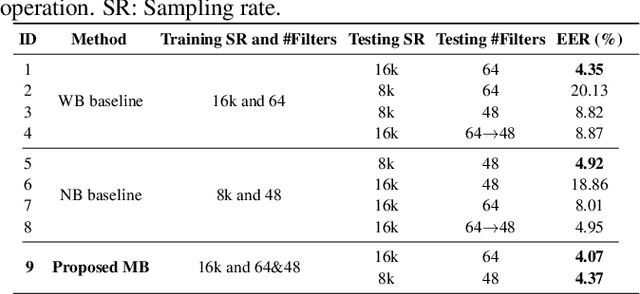
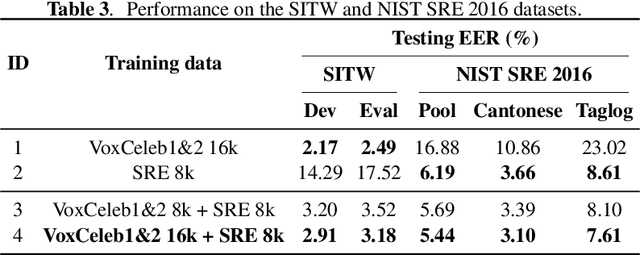
This paper proposes a unified deep speaker embedding framework for modeling speech data with different sampling rates. Considering the narrowband spectrogram as a sub-image of the wideband spectrogram, we tackle the joint modeling problem of the mixed-bandwidth data in an image classification manner. From this perspective, we elaborate several mixed-bandwidth joint training strategies under different training and test data scenarios. The proposed systems are able to flexibly handle the mixed-bandwidth speech data in a single speaker embedding model without any additional downsampling, upsampling, bandwidth extension, or padding operations. We conduct extensive experimental studies on the VoxCeleb1 dataset. Furthermore, the effectiveness of the proposed approach is validated by the SITW and NIST SRE 2016 datasets.
Federated Learning with Dynamic Transformer for Text to Speech
Jul 09, 2021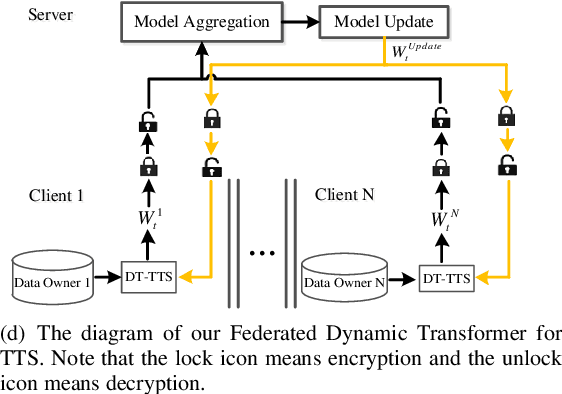

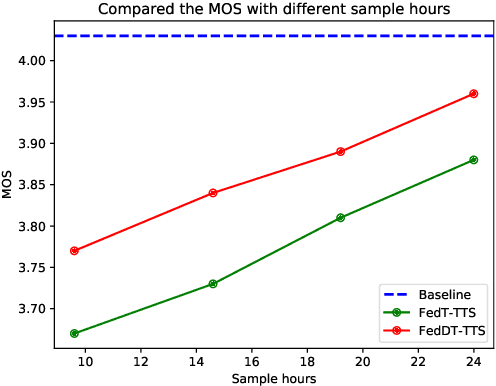
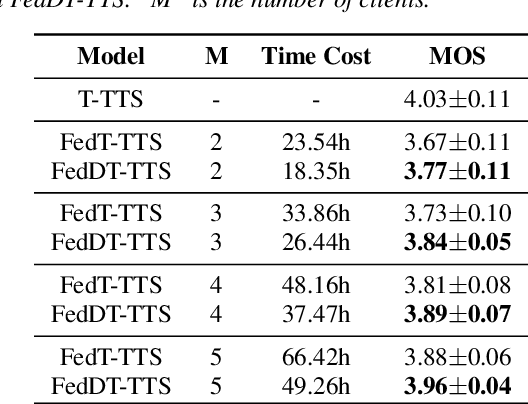
Text to speech (TTS) is a crucial task for user interaction, but TTS model training relies on a sizable set of high-quality original datasets. Due to privacy and security issues, the original datasets are usually unavailable directly. Recently, federated learning proposes a popular distributed machine learning paradigm with an enhanced privacy protection mechanism. It offers a practical and secure framework for data owners to collaborate with others, thus obtaining a better global model trained on the larger dataset. However, due to the high complexity of transformer models, the convergence process becomes slow and unstable in the federated learning setting. Besides, the transformer model trained in federated learning is costly communication and limited computational speed on clients, impeding its popularity. To deal with these challenges, we propose the federated dynamic transformer. On the one hand, the performance is greatly improved comparing with the federated transformer, approaching centralize-trained Transformer-TTS when increasing clients number. On the other hand, it achieves faster and more stable convergence in the training phase and significantly reduces communication time. Experiments on the LJSpeech dataset also strongly prove our method's advantage.
MultiQT: Multimodal Learning for Real-Time Question Tracking in Speech
May 12, 2020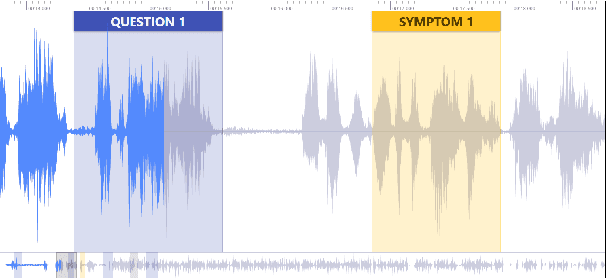

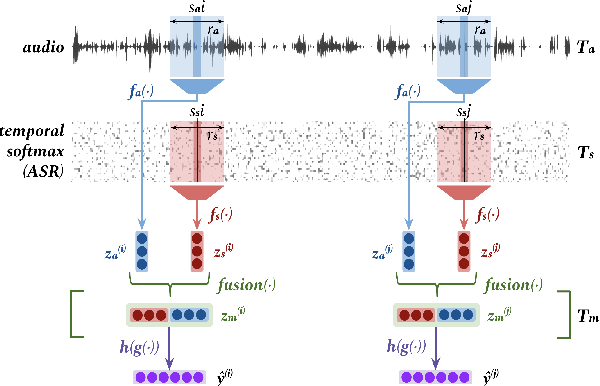

We address a challenging and practical task of labeling questions in speech in real time during telephone calls to emergency medical services in English, which embeds within a broader decision support system for emergency call-takers. We propose a novel multimodal approach to real-time sequence labeling in speech. Our model treats speech and its own textual representation as two separate modalities or views, as it jointly learns from streamed audio and its noisy transcription into text via automatic speech recognition. Our results show significant gains of jointly learning from the two modalities when compared to text or audio only, under adverse noise and limited volume of training data. The results generalize to medical symptoms detection where we observe a similar pattern of improvements with multimodal learning.
Self supervised learning for robust voice cloning
Apr 07, 2022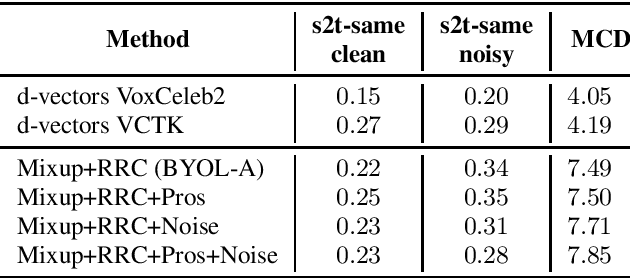
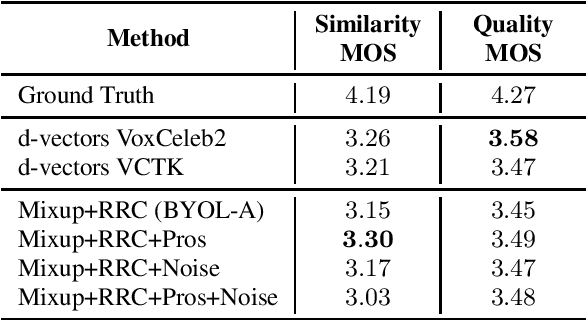
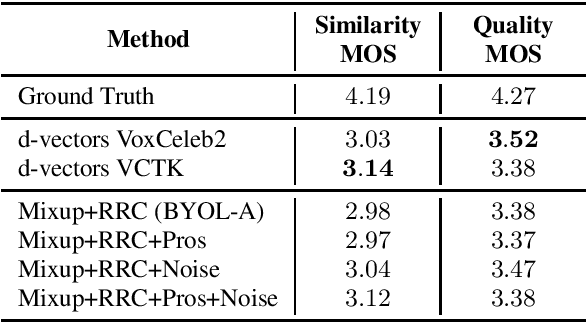
Voice cloning is a difficult task which requires robust and informative features incorporated in a high quality TTS system in order to effectively copy an unseen speaker's voice. In our work, we utilize features learned in a self-supervised framework via the Bootstrap Your Own Latent (BYOL) method, which is shown to produce high quality speech representations when specific audio augmentations are applied to the vanilla algorithm. We further extend the augmentations in the training procedure to aid the resulting features to capture the speaker identity and to make them robust to noise and acoustic conditions. The learned features are used as pre-trained utterance-level embeddings and as inputs to a Non-Attentive Tacotron based architecture, aiming to achieve multispeaker speech synthesis without utilizing additional speaker features. This method enables us to train our model in an unlabeled multispeaker dataset as well as use unseen speaker embeddings to copy a speaker's voice. Subjective and objective evaluations are used to validate the proposed model, as well as the robustness to the acoustic conditions of the target utterance.
Perception-Aware Attack: Creating Adversarial Music via Reverse-Engineering Human Perception
Jul 26, 2022

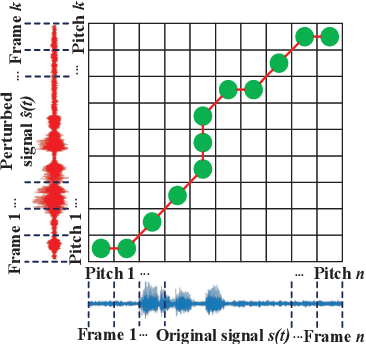

Recently, adversarial machine learning attacks have posed serious security threats against practical audio signal classification systems, including speech recognition, speaker recognition, and music copyright detection. Previous studies have mainly focused on ensuring the effectiveness of attacking an audio signal classifier via creating a small noise-like perturbation on the original signal. It is still unclear if an attacker is able to create audio signal perturbations that can be well perceived by human beings in addition to its attack effectiveness. This is particularly important for music signals as they are carefully crafted with human-enjoyable audio characteristics. In this work, we formulate the adversarial attack against music signals as a new perception-aware attack framework, which integrates human study into adversarial attack design. Specifically, we conduct a human study to quantify the human perception with respect to a change of a music signal. We invite human participants to rate their perceived deviation based on pairs of original and perturbed music signals, and reverse-engineer the human perception process by regression analysis to predict the human-perceived deviation given a perturbed signal. The perception-aware attack is then formulated as an optimization problem that finds an optimal perturbation signal to minimize the prediction of perceived deviation from the regressed human perception model. We use the perception-aware framework to design a realistic adversarial music attack against YouTube's copyright detector. Experiments show that the perception-aware attack produces adversarial music with significantly better perceptual quality than prior work.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
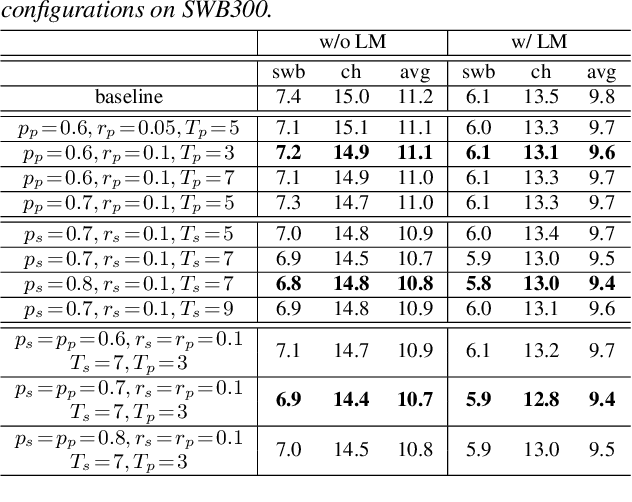
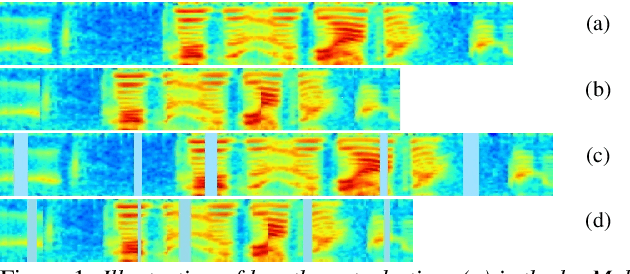

We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Detecting Adversarial Examples in Batches -- a geometrical approach
Jun 17, 2022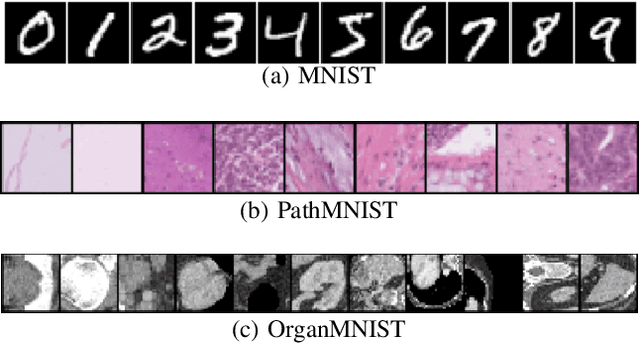

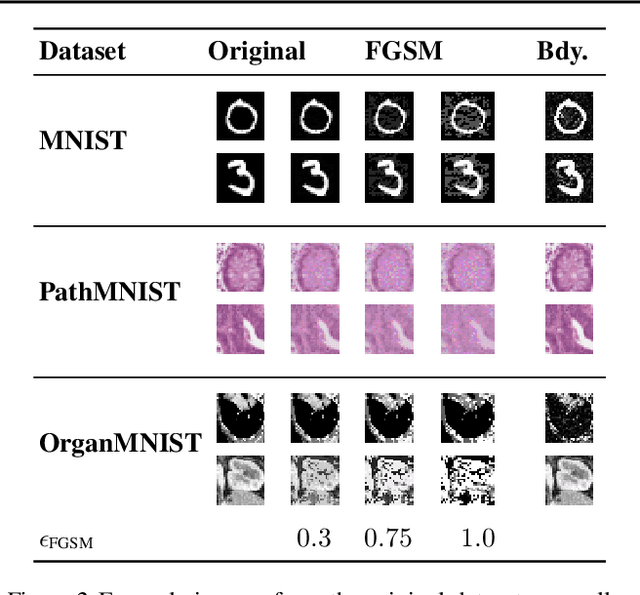

Many deep learning methods have successfully solved complex tasks in computer vision and speech recognition applications. Nonetheless, the robustness of these models has been found to be vulnerable to perturbed inputs or adversarial examples, which are imperceptible to the human eye, but lead the model to erroneous output decisions. In this study, we adapt and introduce two geometric metrics, density and coverage, and evaluate their use in detecting adversarial samples in batches of unseen data. We empirically study these metrics using MNIST and two real-world biomedical datasets from MedMNIST, subjected to two different adversarial attacks. Our experiments show promising results for both metrics to detect adversarial examples. We believe that his work can lay the ground for further study on these metrics' use in deployed machine learning systems to monitor for possible attacks by adversarial examples or related pathologies such as dataset shift.
Pseudo Label Is Better Than Human Label
Mar 28, 2022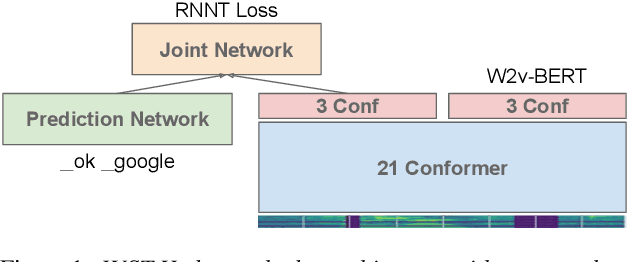

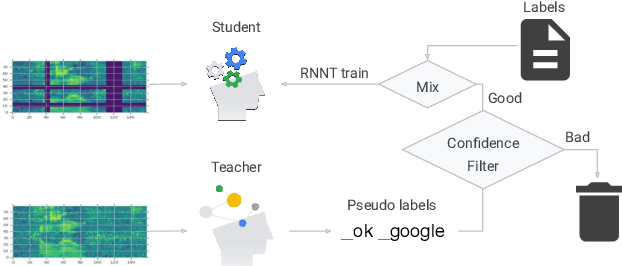
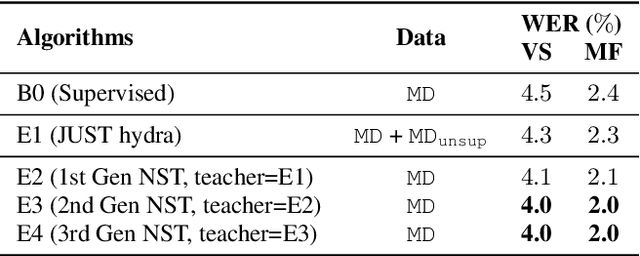
State-of-the-art automatic speech recognition (ASR) systems are trained with tens of thousands of hours of labeled speech data. Human transcription is expensive and time consuming. Factors such as the quality and consistency of the transcription can greatly affect the performance of the ASR models trained with these data. In this paper, we show that we can train a strong teacher model to produce high quality pseudo labels by utilizing recent self-supervised and semi-supervised learning techniques. Specifically, we use JUST (Joint Unsupervised/Supervised Training) and iterative noisy student teacher training to train a 600 million parameter bi-directional teacher model. This model achieved 4.0% word error rate (WER) on a voice search task, 11.1% relatively better than a baseline. We further show that by using this strong teacher model to generate high-quality pseudo labels for training, we can achieve 13.6% relative WER reduction (5.9% to 5.1%) for a streaming model compared to using human labels.
Distance Learner: Incorporating Manifold Prior to Model Training
Jul 14, 2022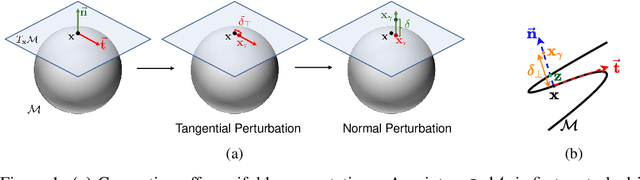
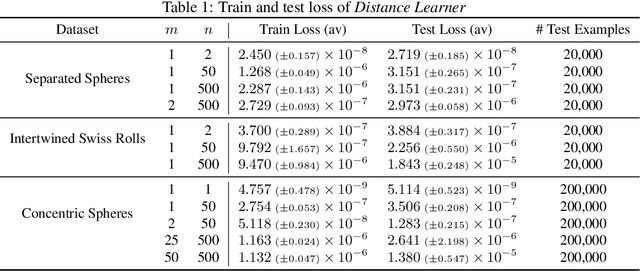

The manifold hypothesis (real world data concentrates near low-dimensional manifolds) is suggested as the principle behind the effectiveness of machine learning algorithms in very high dimensional problems that are common in domains such as vision and speech. Multiple methods have been proposed to explicitly incorporate the manifold hypothesis as a prior in modern Deep Neural Networks (DNNs), with varying success. In this paper, we propose a new method, Distance Learner, to incorporate this prior for DNN-based classifiers. Distance Learner is trained to predict the distance of a point from the underlying manifold of each class, rather than the class label. For classification, Distance Learner then chooses the class corresponding to the closest predicted class manifold. Distance Learner can also identify points as being out of distribution (belonging to neither class), if the distance to the closest manifold is higher than a threshold. We evaluate our method on multiple synthetic datasets and show that Distance Learner learns much more meaningful classification boundaries compared to a standard classifier. We also evaluate our method on the task of adversarial robustness, and find that it not only outperforms standard classifier by a large margin, but also performs at par with classifiers trained via state-of-the-art adversarial training.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021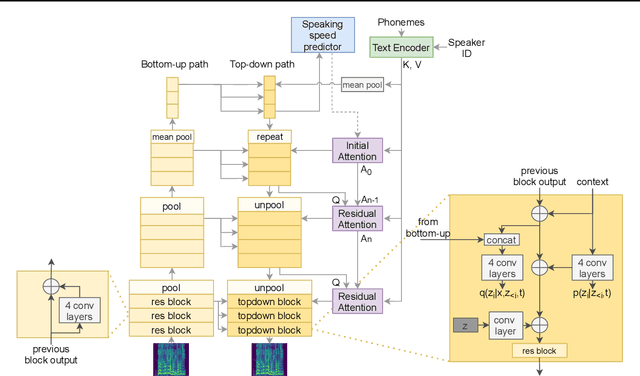
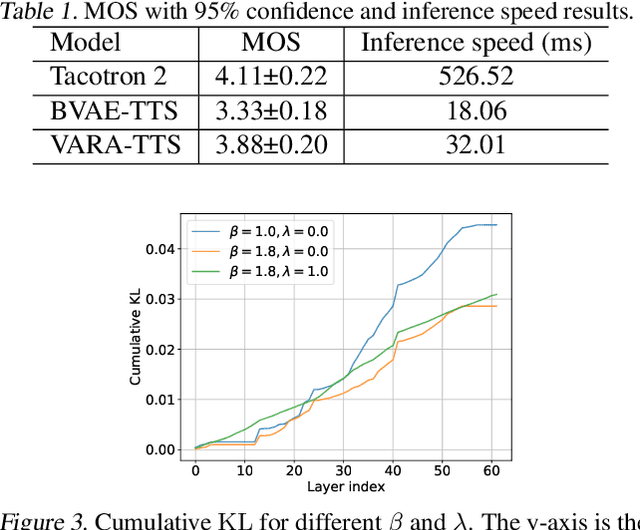

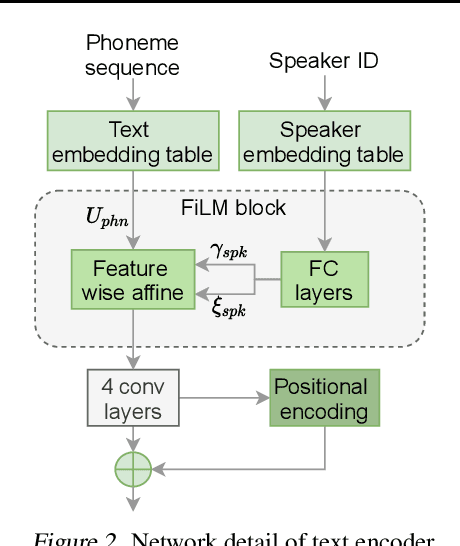
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.