 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing for ASR in Speech LLM with Common Word Cues and Bias Word Position Prediction
Apr 14, 2026Speech-aware LLMs (SLLMs) have recently achieved state-of-the-art ASR performance; however, they still fail to accurately transcribe bias words that appear rarely or never in the training data. Contextual biasing mechanisms are commonly implemented by introducing a predefined bias word list into the model via a text prompt or additional module. For further improvement, predefined bias words can be paired with their phoneme representations as pronunciation cues. Typically, phoneme sequences are generated through a G2P system that covers the target languages and domains of the bias words. Therefore, when a compatible G2P system is unavailable, phoneme-assisted contextual biasing becomes difficult to perform. Moreover, manually adding accurate phoneme sequences requires advanced phonetic knowledge. In this paper, we explore contextual biasing in SLLM based on acoustic cues associated with a set of common words whose pronunciations are partially similar to those of the target bias words. We assume ASR applications in which end users do not require special knowledge of phonetics or utilize G2P tools for inference. For enhanced robustness, we also introduce bias word positional prediction implemented in a multi-output learning fashion. Our method reduces bias word recognition errors by 16.3% compared to baseline systems, including on out-of-domain data.
Self-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts
Mar 11, 2026We propose self-speculative decoding for speech-aware LLMs by using the CTC encoder as a draft model to accelerate auto-regressive (AR) inference and improve ASR accuracy. Our three-step procedure works as follows: (1) if the frame entropies of the CTC output distributions are below a threshold, the greedy CTC hypothesis is accepted as final; (2) otherwise, the CTC hypothesis is verified in a single LLM forward pass using a relaxed acceptance criterion based on token likelihoods; (3) if verification fails, AR decoding resumes from the accepted CTC prefix. Experiments on nine corpora and five languages show that this approach can simultaneously accelerate decoding and reduce WER. On the HuggingFace Open ASR benchmark with a 1B parameter LLM and 440M parameter CTC encoder, we achieve a record 5.58% WER and improve the inverse real time factor by a factor of 4.4 with only a 12% relative WER increase over AR search. Code and model weights are publicly available under a permissive license.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
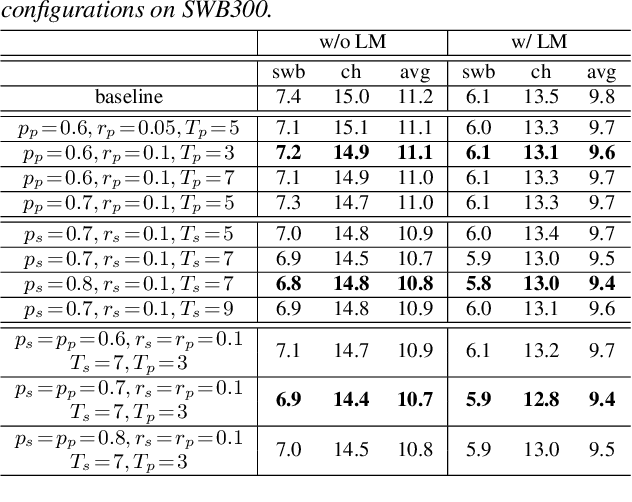
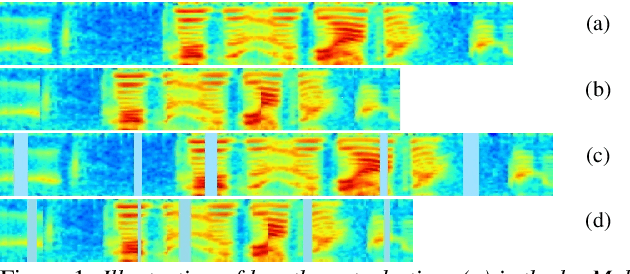

We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Knowledge Distillation Leveraging Alternative Soft Targets from Non-Parallel Qualified Speech Data
Dec 16, 2021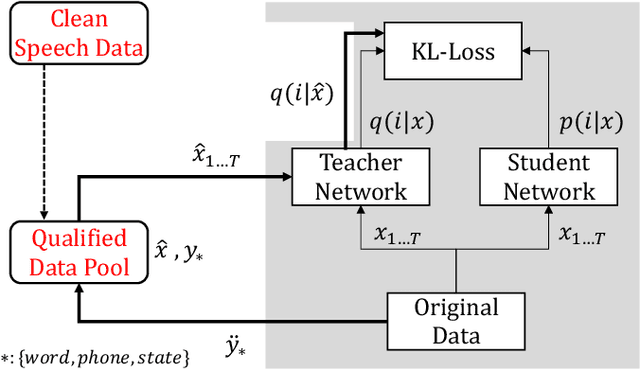
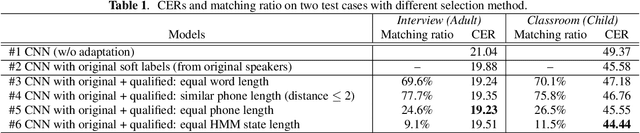
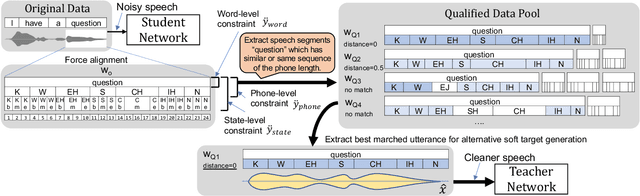
This paper describes a novel knowledge distillation framework that leverages acoustically qualified speech data included in an existing training data pool as privileged information. In our proposed framework, a student network is trained with multiple soft targets for each utterance that consist of main soft targets from original speakers' utterance and alternative targets from other speakers' utterances spoken under better acoustic conditions as a secondary view. These qualified utterances from other speakers, used to generate better soft targets, are collected from a qualified data pool by using strict constraints in terms of word/phone/state durations. Our proposed method is a form of target-side data augmentation that creates multiple copies of data with corresponding better soft targets obtained from a qualified data pool. We show in our experiments under acoustic model adaptation settings that the proposed method, exploiting better soft targets obtained from various speakers, can further improve recognition accuracy compared with conventional methods using only soft targets from original speakers.