 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting phoneme-level prosody latents using AR and flow-based Prior Networks for expressive speech synthesis
Nov 02, 2022



A large part of the expressive speech synthesis literature focuses on learning prosodic representations of the speech signal which are then modeled by a prior distribution during inference. In this paper, we compare different prior architectures at the task of predicting phoneme level prosodic representations extracted with an unsupervised FVAE model. We use both subjective and objective metrics to show that normalizing flow based prior networks can result in more expressive speech at the cost of a slight drop in quality. Furthermore, we show that the synthesized speech has higher variability, for a given text, due to the nature of normalizing flows. We also propose a Dynamical VAE model, that can generate higher quality speech although with decreased expressiveness and variability compared to the flow based models.
Learning utterance-level representations through token-level acoustic latents prediction for Expressive Speech Synthesis
Nov 01, 2022



This paper proposes an Expressive Speech Synthesis model that utilizes token-level latent prosodic variables in order to capture and control utterance-level attributes, such as character acting voice and speaking style. Current works aim to explicitly factorize such fine-grained and utterance-level speech attributes into different representations extracted by modules that operate in the corresponding level. We show that the fine-grained latent space also captures coarse-grained information, which is more evident as the dimension of latent space increases in order to capture diverse prosodic representations. Therefore, a trade-off arises between the diversity of the token-level and utterance-level representations and their disentanglement. We alleviate this issue by first capturing rich speech attributes into a token-level latent space and then, separately train a prior network that given the input text, learns utterance-level representations in order to predict the phoneme-level, posterior latents extracted during the previous step. Both qualitative and quantitative evaluations are used to demonstrate the effectiveness of the proposed approach. Audio samples are available in our demo page.
Generating Gender-Ambiguous Text-to-Speech Voices
Nov 01, 2022



The gender of a voice assistant or any voice user interface is a central element of its perceived identity. While a female voice is a common choice, there is an increasing interest in alternative approaches where the gender is ambiguous rather than clearly identifying as female or male. This work addresses the task of generating gender-ambiguous text-to-speech (TTS) voices that do not correspond to any existing person. This is accomplished by sampling from a latent speaker embeddings' space that was formed while training a multilingual, multi-speaker TTS system on data from multiple male and female speakers. Various options are investigated regarding the sampling process. In our experiments, the effects of different sampling choices on the gender ambiguity and the naturalness of the resulting voices are evaluated. The proposed method is shown able to efficiently generate novel speakers that are superior to a baseline averaged speaker embedding. To our knowledge, this is the first systematic approach that can reliably generate a range of gender-ambiguous voices to meet diverse user requirements.
Fine-grained Noise Control for Multispeaker Speech Synthesis
Apr 11, 2022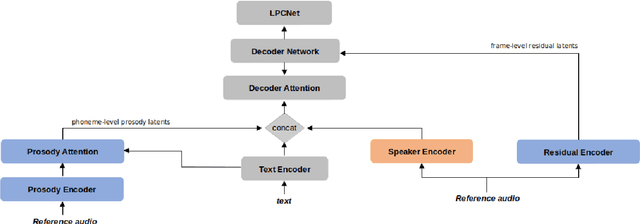
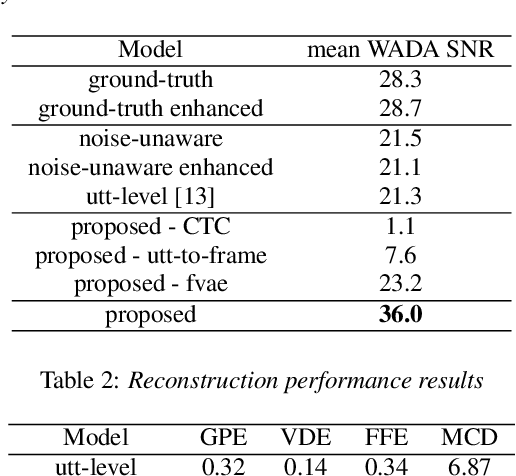
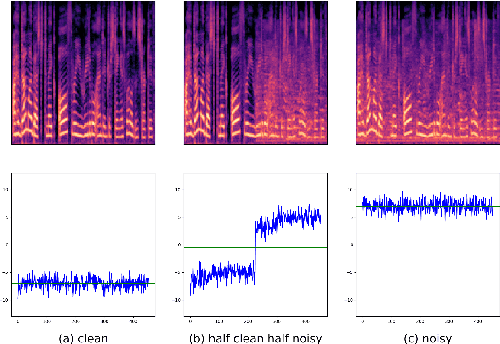
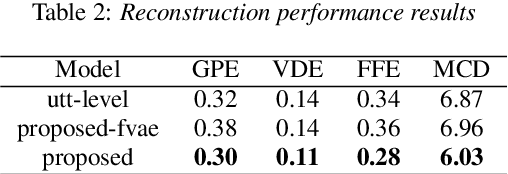
A text-to-speech (TTS) model typically factorizes speech attributes such as content, speaker and prosody into disentangled representations.Recent works aim to additionally model the acoustic conditions explicitly, in order to disentangle the primary speech factors, i.e. linguistic content, prosody and timbre from any residual factors, such as recording conditions and background noise.This paper proposes unsupervised, interpretable and fine-grained noise and prosody modeling. We incorporate adversarial training, representation bottleneck and utterance-to-frame modeling in order to learn frame-level noise representations. To the same end, we perform fine-grained prosody modeling via a Fully Hierarchical Variational AutoEncoder (FVAE) which additionally results in more expressive speech synthesis.
Self supervised learning for robust voice cloning
Apr 07, 2022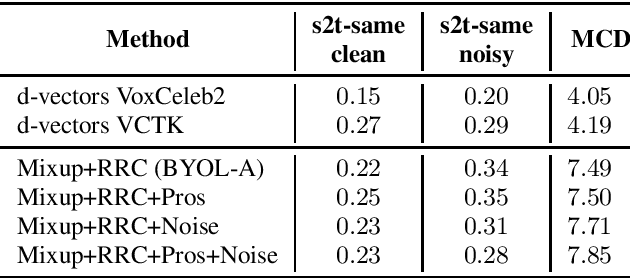
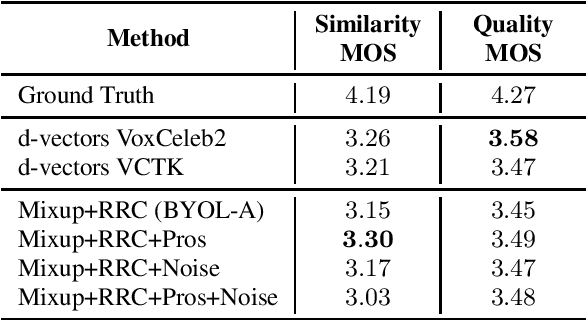
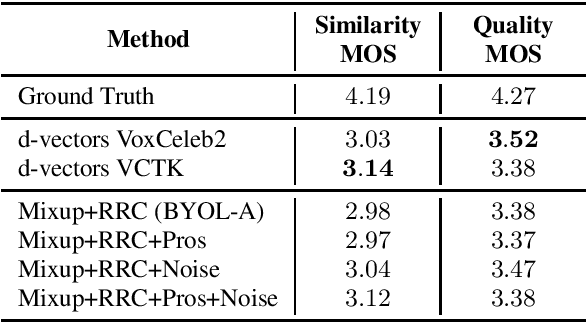
Voice cloning is a difficult task which requires robust and informative features incorporated in a high quality TTS system in order to effectively copy an unseen speaker's voice. In our work, we utilize features learned in a self-supervised framework via the Bootstrap Your Own Latent (BYOL) method, which is shown to produce high quality speech representations when specific audio augmentations are applied to the vanilla algorithm. We further extend the augmentations in the training procedure to aid the resulting features to capture the speaker identity and to make them robust to noise and acoustic conditions. The learned features are used as pre-trained utterance-level embeddings and as inputs to a Non-Attentive Tacotron based architecture, aiming to achieve multispeaker speech synthesis without utilizing additional speaker features. This method enables us to train our model in an unlabeled multispeaker dataset as well as use unseen speaker embeddings to copy a speaker's voice. Subjective and objective evaluations are used to validate the proposed model, as well as the robustness to the acoustic conditions of the target utterance.
SOMOS: The Samsung Open MOS Dataset for the Evaluation of Neural Text-to-Speech Synthesis
Apr 06, 2022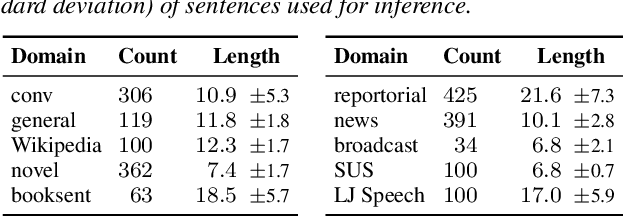
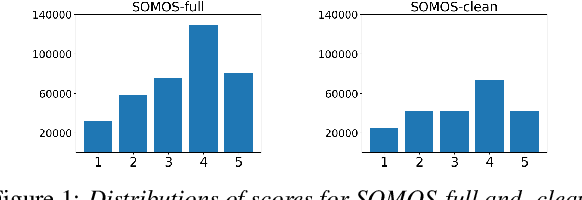
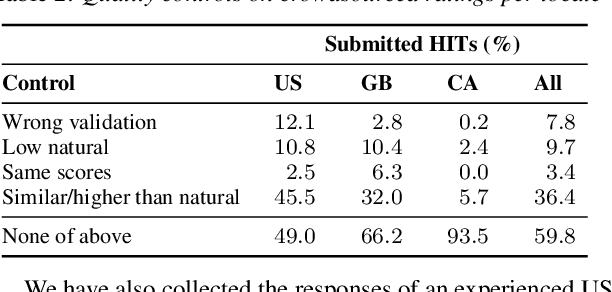
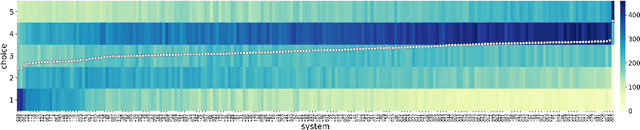
In this work, we present the SOMOS dataset, the first large-scale mean opinion scores (MOS) dataset consisting of solely neural text-to-speech (TTS) samples. It can be employed to train automatic MOS prediction systems focused on the assessment of modern synthesizers, and can stimulate advancements in acoustic model evaluation. It consists of 20K synthetic utterances of the LJ Speech voice, a public domain speech dataset which is a common benchmark for building neural acoustic models and vocoders. Utterances are generated from 200 TTS systems including vanilla neural acoustic models as well as models which allow prosodic variations. An LPCNet vocoder is used for all systems, so that the samples' variation depends only on the acoustic models. The synthesized utterances provide balanced and adequate domain and length coverage. We collect MOS naturalness evaluations on 3 English Amazon Mechanical Turk locales and share practices leading to reliable crowdsourced annotations for this task. Baseline results of state-of-the-art MOS prediction models on the SOMOS dataset are presented, while we show the challenges that such models face when assigned to evaluate synthetic utterances.