 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf supervised learning for robust voice cloning
Paper and Code
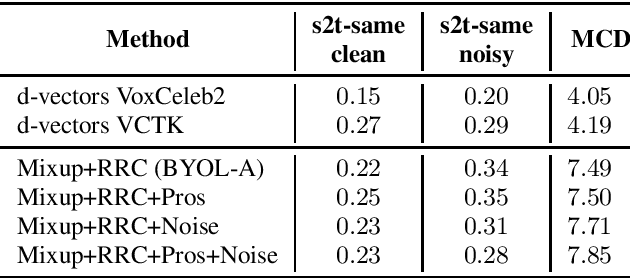
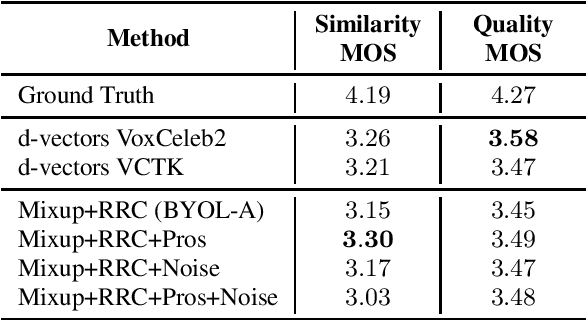
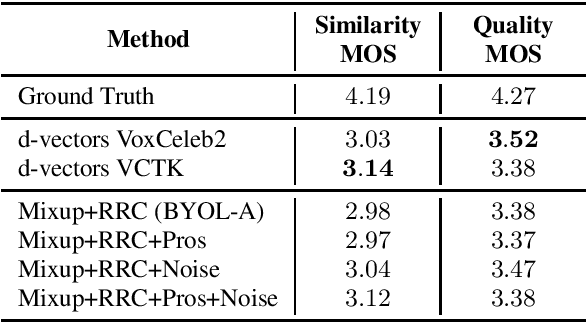
Voice cloning is a difficult task which requires robust and informative features incorporated in a high quality TTS system in order to effectively copy an unseen speaker's voice. In our work, we utilize features learned in a self-supervised framework via the Bootstrap Your Own Latent (BYOL) method, which is shown to produce high quality speech representations when specific audio augmentations are applied to the vanilla algorithm. We further extend the augmentations in the training procedure to aid the resulting features to capture the speaker identity and to make them robust to noise and acoustic conditions. The learned features are used as pre-trained utterance-level embeddings and as inputs to a Non-Attentive Tacotron based architecture, aiming to achieve multispeaker speech synthesis without utilizing additional speaker features. This method enables us to train our model in an unlabeled multispeaker dataset as well as use unseen speaker embeddings to copy a speaker's voice. Subjective and objective evaluations are used to validate the proposed model, as well as the robustness to the acoustic conditions of the target utterance.