 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Uncertainty Calibration in Large Language Model Long-Form Question Answering
Jan 30, 2026Large Language Models (LLMs) are commonly used in Question Answering (QA) settings, increasingly in the natural sciences if not science at large. Reliable Uncertainty Quantification (UQ) is critical for the trustworthy uptake of generated answers. Existing UQ approaches remain weakly validated in scientific QA, a domain relying on fact-retrieval and reasoning capabilities. We introduce the first large-scale benchmark for evaluating UQ metrics in reasoning-demanding QA studying calibration of UQ methods, providing an extensible open-source framework to reproducibly assess calibration. Our study spans up to 20 large language models of base, instruction-tuned and reasoning variants. Our analysis covers seven scientific QA datasets, including both multiple-choice and arithmetic question answering tasks, using prompting to emulate an open question answering setting. We evaluate and compare methods representative of prominent approaches on a total of 685,000 long-form responses, spanning different reasoning complexities representative of domain-specific tasks. At the token level, we find that instruction tuning induces strong probability mass polarization, reducing the reliability of token-level confidences as estimates of uncertainty. Models further fine-tuned for reasoning are exposed to the same effect, but the reasoning process appears to mitigate it depending on the provider. At the sequence level, we show that verbalized approaches are systematically biased and poorly correlated with correctness, while answer frequency (consistency across samples) yields the most reliable calibration. In the wake of our analysis, we study and report the misleading effect of relying exclusively on ECE as a sole measure for judging performance of UQ methods on benchmark datasets. Our findings expose critical limitations of current UQ methods for LLMs and standard practices in benchmarking thereof.
Data-efficient U-Net for Segmentation of Carbide Microstructures in SEM Images of Steel Alloys
Nov 14, 2025Understanding reactor-pressure-vessel steel microstructure is crucial for predicting mechanical properties, as carbide precipitates both strengthen the alloy and can initiate cracks. In scanning electron microscopy images, gray-value overlap between carbides and matrix makes simple thresholding ineffective. We present a data-efficient segmentation pipeline using a lightweight U-Net (30.7~M parameters) trained on just \textbf{10 annotated scanning electron microscopy images}. Despite limited data, our model achieves a \textbf{Dice-Sørensen coefficient of 0.98}, significantly outperforming the state-of-the-art in the field of metallurgy (classical image analysis: 0.85), while reducing annotation effort by one order of magnitude compared to the state-of-the-art data efficient segmentation model. This approach enables rapid, automated carbide quantification for alloy design and generalizes to other steel types, demonstrating the potential of data-efficient deep learning in reactor-pressure-vessel steel analysis.
sbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
Testing Uncertainty of Large Language Models for Physics Knowledge and Reasoning
Nov 18, 2024Large Language Models (LLMs) have gained significant popularity in recent years for their ability to answer questions in various fields. However, these models have a tendency to "hallucinate" their responses, making it challenging to evaluate their performance. A major challenge is determining how to assess the certainty of a model's predictions and how it correlates with accuracy. In this work, we introduce an analysis for evaluating the performance of popular open-source LLMs, as well as gpt-3.5 Turbo, on multiple choice physics questionnaires. We focus on the relationship between answer accuracy and variability in topics related to physics. Our findings suggest that most models provide accurate replies in cases where they are certain, but this is by far not a general behavior. The relationship between accuracy and uncertainty exposes a broad horizontal bell-shaped distribution. We report how the asymmetry between accuracy and uncertainty intensifies as the questions demand more logical reasoning of the LLM agent, while the same relationship remains sharp for knowledge retrieval tasks.
Harnessing Machine Learning for Single-Shot Measurement of Free Electron Laser Pulse Power
Nov 14, 2024Electron beam accelerators are essential in many scientific and technological fields. Their operation relies heavily on the stability and precision of the electron beam. Traditional diagnostic techniques encounter difficulties in addressing the complex and dynamic nature of electron beams. Particularly in the context of free-electron lasers (FELs), it is fundamentally impossible to measure the lasing-on and lasingoff electron power profiles for a single electron bunch. This is a crucial hurdle in the exact reconstruction of the photon pulse profile. To overcome this hurdle, we developed a machine learning model that predicts the temporal power profile of the electron bunch in the lasing-off regime using machine parameters that can be obtained when lasing is on. The model was statistically validated and showed superior predictions compared to the state-of-the-art batch calibrations. The work we present here is a critical element for a virtual pulse reconstruction diagnostic (VPRD) tool designed to reconstruct the power profile of individual photon pulses without requiring repeated measurements in the lasing-off regime. This promises to significantly enhance the diagnostic capabilities in FELs at large.
Uncertainty Estimation in Instance Segmentation with Star-convex Shapes
Sep 19, 2023



Instance segmentation has witnessed promising advancements through deep neural network-based algorithms. However, these models often exhibit incorrect predictions with unwarranted confidence levels. Consequently, evaluating prediction uncertainty becomes critical for informed decision-making. Existing methods primarily focus on quantifying uncertainty in classification or regression tasks, lacking emphasis on instance segmentation. Our research addresses the challenge of estimating spatial certainty associated with the location of instances with star-convex shapes. Two distinct clustering approaches are evaluated which compute spatial and fractional certainty per instance employing samples by the Monte-Carlo Dropout or Deep Ensemble technique. Our study demonstrates that combining spatial and fractional certainty scores yields improved calibrated estimation over individual certainty scores. Notably, our experimental results show that the Deep Ensemble technique alongside our novel radial clustering approach proves to be an effective strategy. Our findings emphasize the significance of evaluating the calibration of estimated certainties for model reliability and decision-making.
Detecting Adversarial Examples in Batches -- a geometrical approach
Jun 17, 2022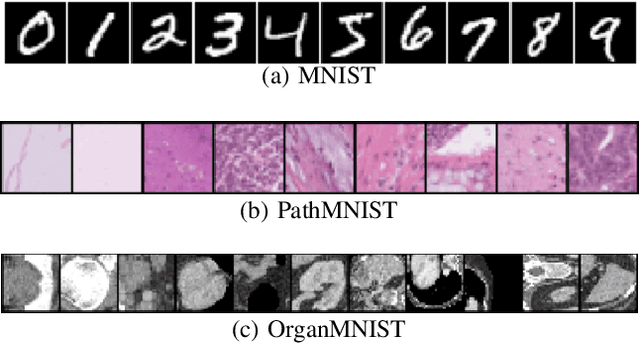

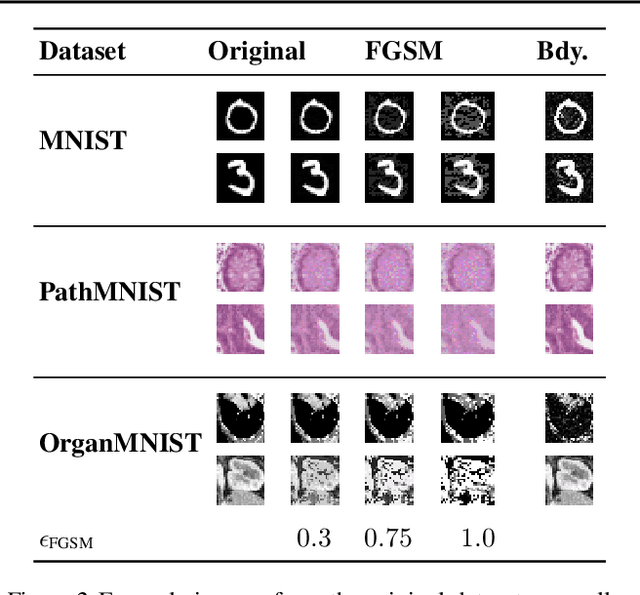

Many deep learning methods have successfully solved complex tasks in computer vision and speech recognition applications. Nonetheless, the robustness of these models has been found to be vulnerable to perturbed inputs or adversarial examples, which are imperceptible to the human eye, but lead the model to erroneous output decisions. In this study, we adapt and introduce two geometric metrics, density and coverage, and evaluate their use in detecting adversarial samples in batches of unseen data. We empirically study these metrics using MNIST and two real-world biomedical datasets from MedMNIST, subjected to two different adversarial attacks. Our experiments show promising results for both metrics to detect adversarial examples. We believe that his work can lay the ground for further study on these metrics' use in deployed machine learning systems to monitor for possible attacks by adversarial examples or related pathologies such as dataset shift.
Recommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022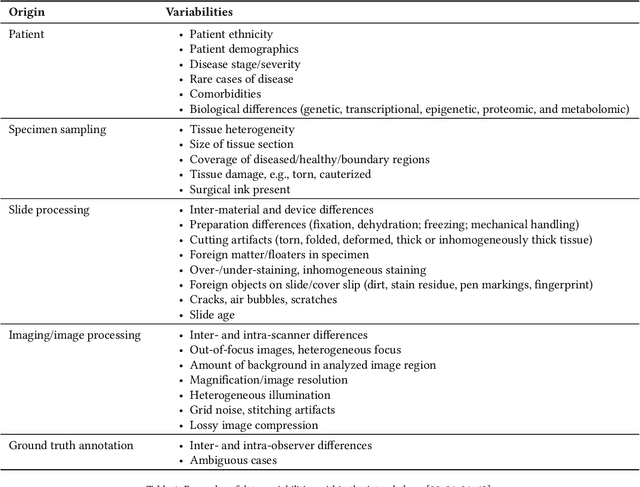

Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.
Machine Learning State-of-the-Art with Uncertainties
Apr 14, 2022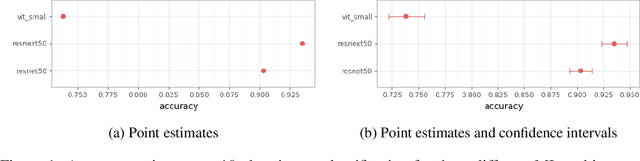
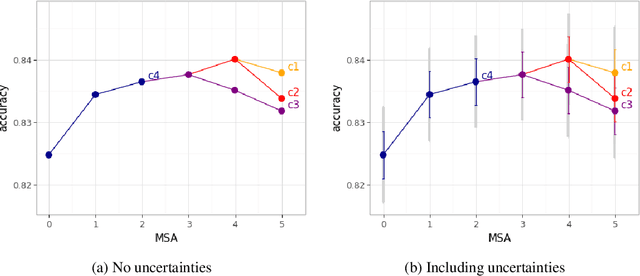
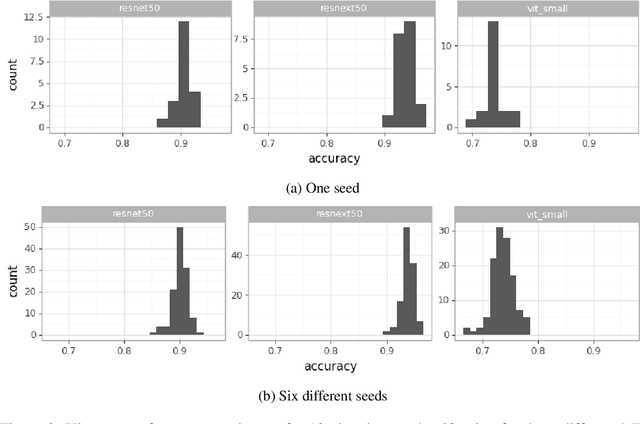
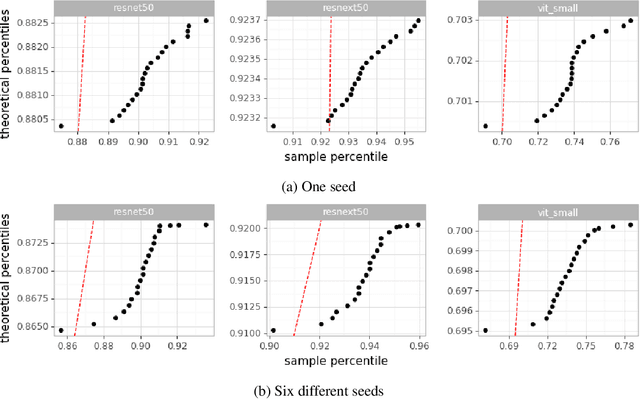
With the availability of data, hardware, software ecosystem and relevant skill sets, the machine learning community is undergoing a rapid development with new architectures and approaches appearing at high frequency every year. In this article, we conduct an exemplary image classification study in order to demonstrate how confidence intervals around accuracy measurements can greatly enhance the communication of research results as well as impact the reviewing process. In addition, we explore the hallmarks and limitations of this approximation. We discuss the relevance of this approach reflecting on a spotlight publication of ICLR22. A reproducible workflow is made available as an open-source adjoint to this publication. Based on our discussion, we make suggestions for improving the authoring and reviewing process of machine learning articles.