 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
Mar 26, 2021
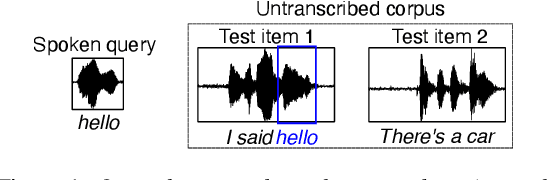
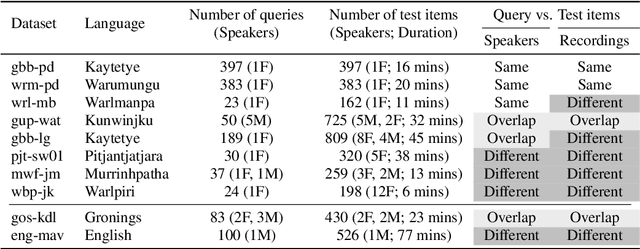
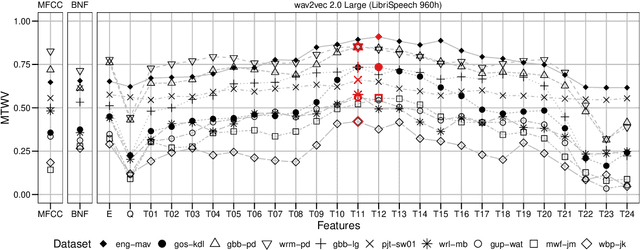
For languages with insufficient resources to train speech recognition systems, query-by-example spoken term detection (QbE-STD) offers a way of accessing an untranscribed speech corpus by helping identify regions where spoken query terms occur. Yet retrieval performance can be poor when the query and corpus are spoken by different speakers and produced in different recording conditions. Using data selected from a variety of speakers and recording conditions from 7 Australian Aboriginal languages and a regional variety of Dutch, all of which are endangered or vulnerable, we evaluated whether QbE-STD performance on these languages could be improved by leveraging representations extracted from the pre-trained English wav2vec 2.0 model. Compared to the use of Mel-frequency cepstral coefficients and bottleneck features, we find that representations from the middle layers of the wav2vec 2.0 Transformer offer large gains in task performance (between 56% and 86%). While features extracted using the pre-trained English model yielded improved detection on all the evaluation languages, better detection performance was associated with the evaluation language's phonological similarity to English.
Voice Conversion for Whispered Speech Synthesis
Jan 17, 2020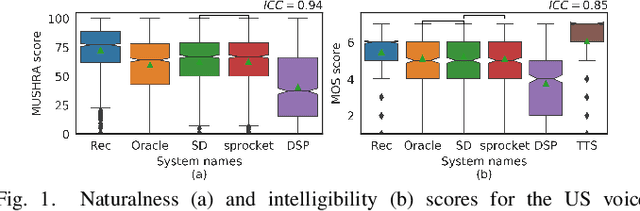
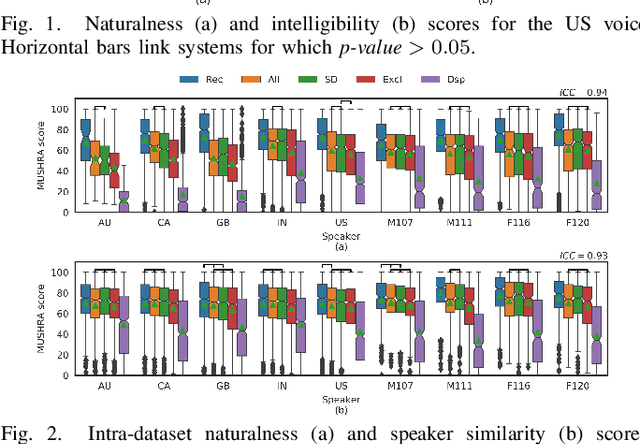
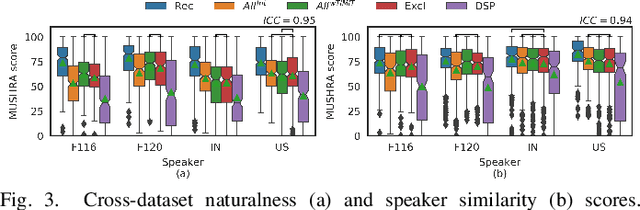
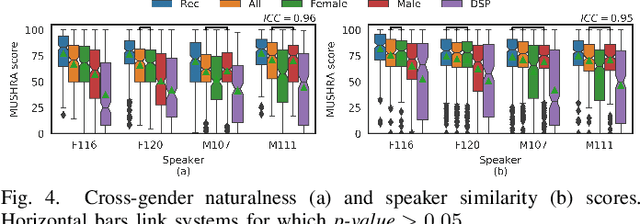
We present an approach to synthesize whisper by applying a handcrafted signal processing recipe and Voice Conversion (VC) techniques to convert normally phonated speech to whispered speech. We investigate using Gaussian Mixture Models (GMM) and Deep Neural Networks (DNN) to model the mapping between acoustic features of normal speech and those of whispered speech. We evaluate naturalness and speaker similarity of the converted whisper on an internal corpus and on the publicly available wTIMIT corpus. We show that applying VC techniques is significantly better than using rule-based signal processing methods and it achieves results that are indistinguishable from copy-synthesis of natural whisper recordings. We investigate the ability of the DNN model to generalize on unseen speakers, when trained with data from multiple speakers. We show that excluding the target speaker from the training set has little or no impact on the perceived naturalness and speaker similarity of the converted whisper. The proposed DNN method is used in the newly released Whisper Mode of Amazon Alexa.
The NiuTrans End-to-End Speech Translation System for IWSLT 2021 Offline Task
Jul 08, 2021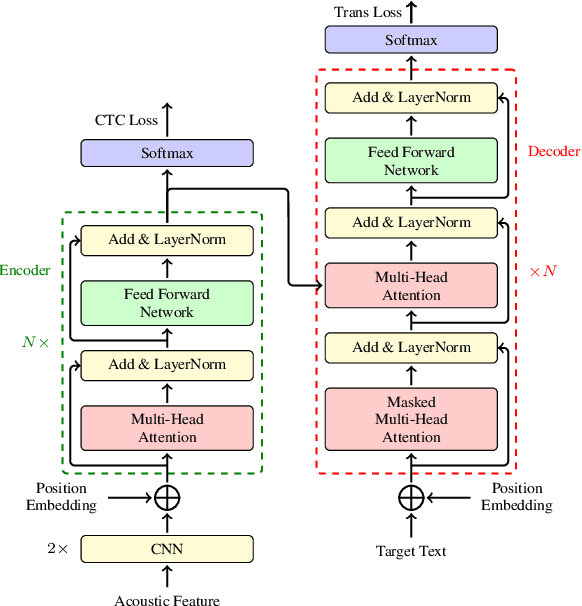
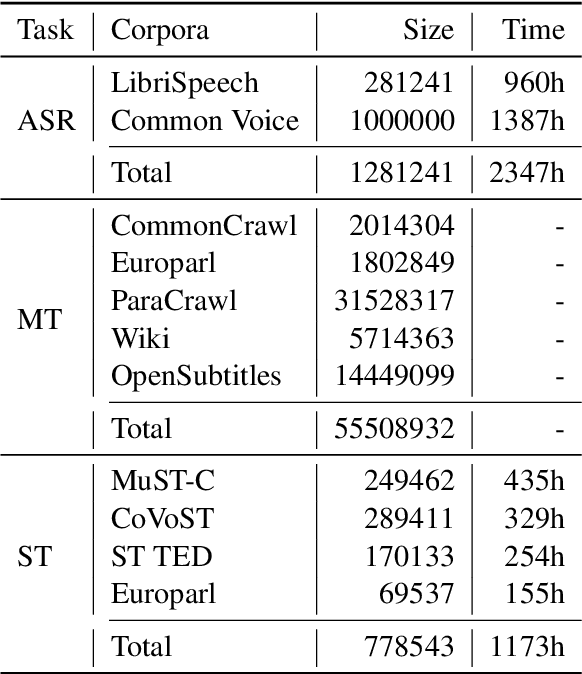
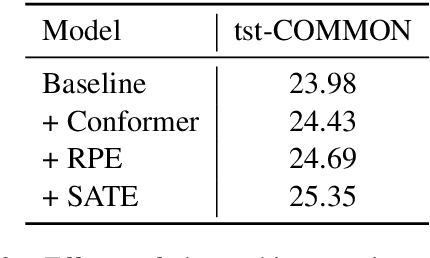
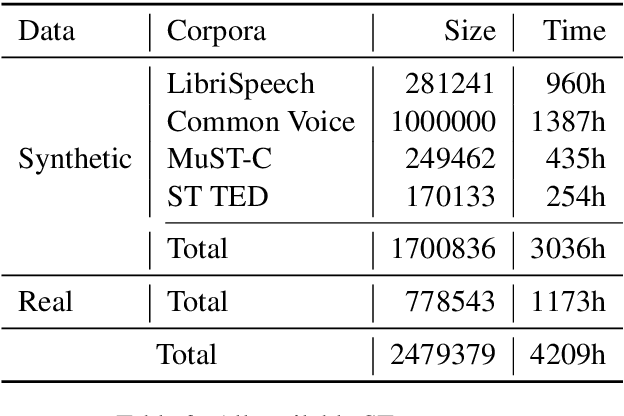
This paper describes the submission of the NiuTrans end-to-end speech translation system for the IWSLT 2021 offline task, which translates from the English audio to German text directly without intermediate transcription. We use the Transformer-based model architecture and enhance it by Conformer, relative position encoding, and stacked acoustic and textual encoding. To augment the training data, the English transcriptions are translated to German translations. Finally, we employ ensemble decoding to integrate the predictions from several models trained with the different datasets. Combining these techniques, we achieve 33.84 BLEU points on the MuST-C En-De test set, which shows the enormous potential of the end-to-end model.
LibriVoxDeEn: A Corpus for German-to-English Speech Translation and Speech Recognition
Oct 18, 2019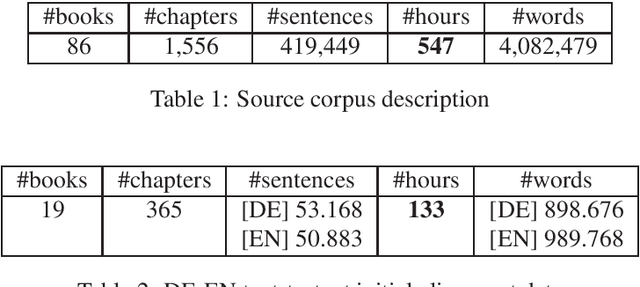



We present a corpus of sentence-aligned triples of German audio, German text, and English translation, based on German audio books. The corpus consists of over 100 hours of audio material and over 50k parallel sentences. The audio data is read speech and thus low in disfluencies. The quality of audio and sentence alignments has been checked by a manual evaluation, showing that speech alignment quality is in general very high. The sentence alignment quality is comparable to well-used parallel translation data and can be adjusted by cutoffs on the automatic alignment score. To our knowledge, this corpus is to date the largest resource for end-to-end speech translation for German.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022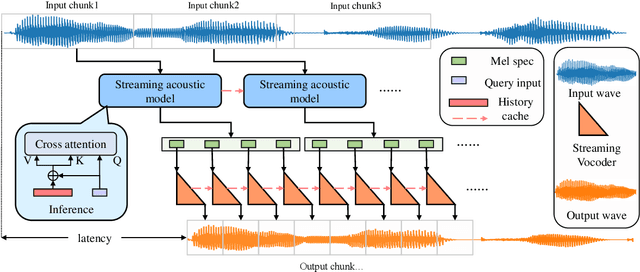
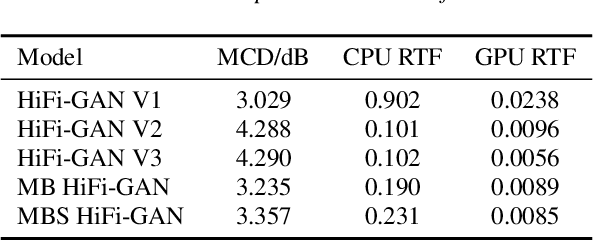
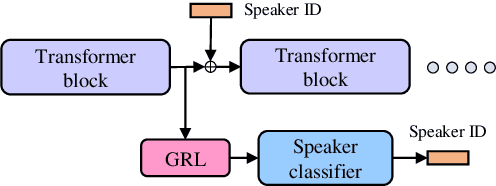
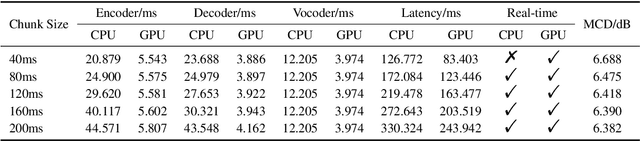
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
Using VAEs and Normalizing Flows for One-shot Text-To-Speech Synthesis of Expressive Speech
Nov 28, 2019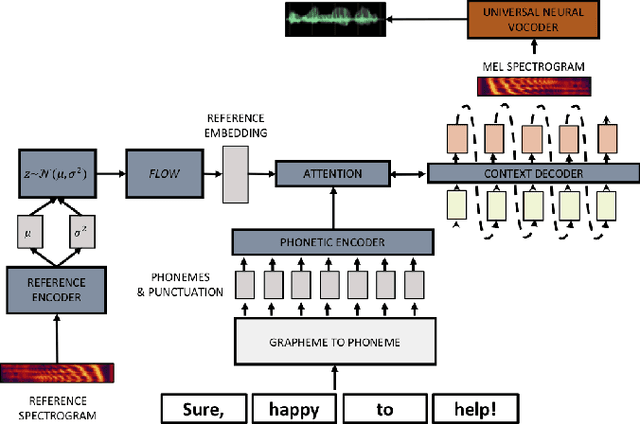
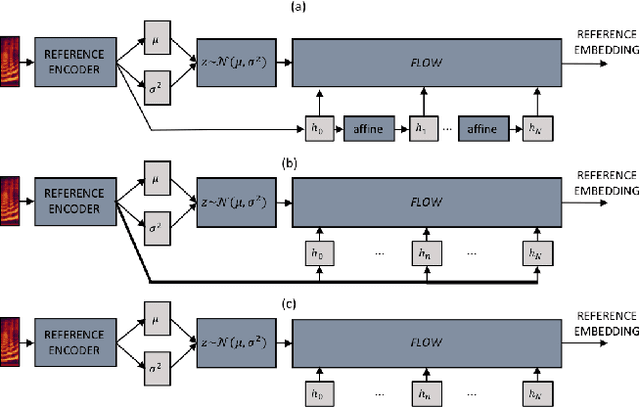
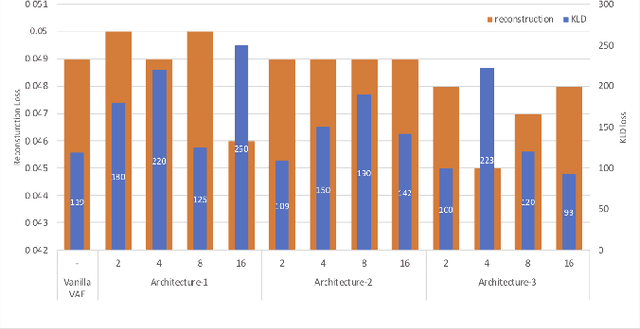
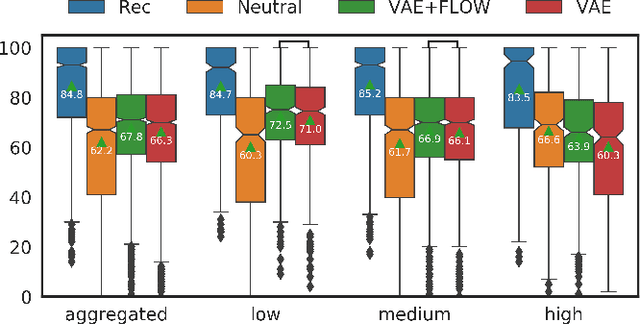
We propose a Text-to-Speech method to create an unseen expressive style using one utterance of expressive speech of around one second. Specifically, we enhance the disentanglement capabilities of a state-of-the-art sequence-to-sequence based system with a Variational AutoEncoder (VAE) and a Householder Flow. The proposed system provides a 22% KL-divergence reduction while jointly improving perceptual metrics over state-of-the-art. At synthesis time we use one example of expressive style as a reference input to the encoder for generating any text in the desired style. Perceptual MUSHRA evaluations show that we can create a voice with a 9% relative naturalness improvement over standard Neural Text-to-Speech, while also improving the perceived emotional intensity (59 compared to the 55 of neutral speech).
Data augmentation using prosody and false starts to recognize non-native children's speech
Aug 29, 2020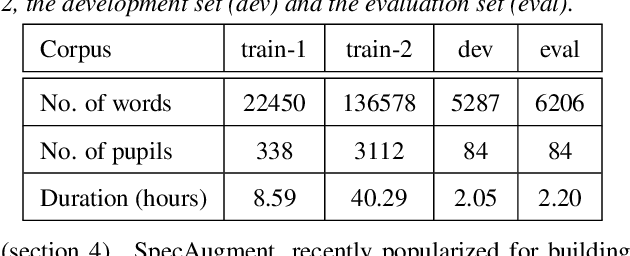
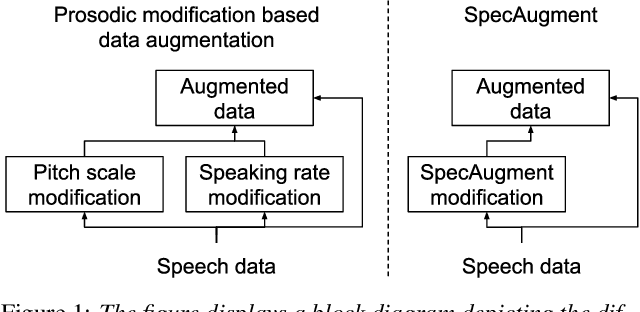
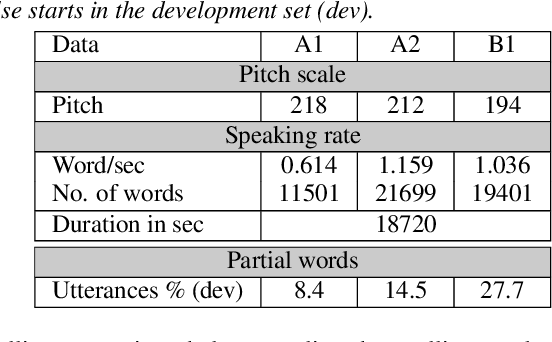
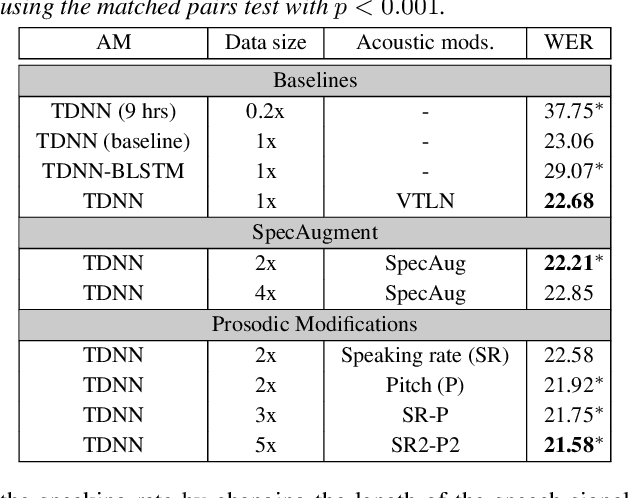
This paper describes AaltoASR's speech recognition system for the INTERSPEECH 2020 shared task on Automatic Speech Recognition (ASR) for non-native children's speech. The task is to recognize non-native speech from children of various age groups given a limited amount of speech. Moreover, the speech being spontaneous has false starts transcribed as partial words, which in the test transcriptions leads to unseen partial words. To cope with these two challenges, we investigate a data augmentation-based approach. Firstly, we apply the prosody-based data augmentation to supplement the audio data. Secondly, we simulate false starts by introducing partial-word noise in the language modeling corpora creating new words. Acoustic models trained on prosody-based augmented data outperform the models using the baseline recipe or the SpecAugment-based augmentation. The partial-word noise also helps to improve the baseline language model. Our ASR system, a combination of these schemes, is placed third in the evaluation period and achieves the word error rate of 18.71%. Post-evaluation period, we observe that increasing the amounts of prosody-based augmented data leads to better performance. Furthermore, removing low-confidence-score words from hypotheses can lead to further gains. These two improvements lower the ASR error rate to 17.99%.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 11, 2021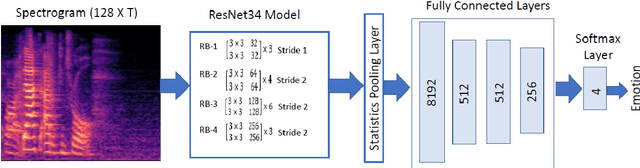
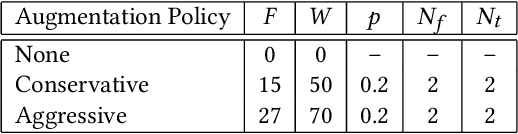
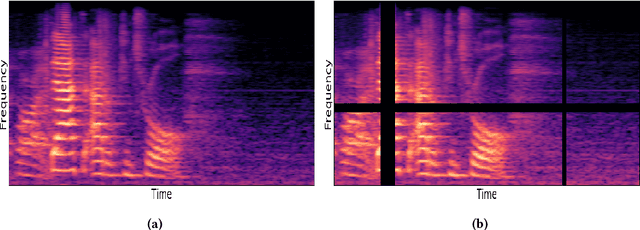
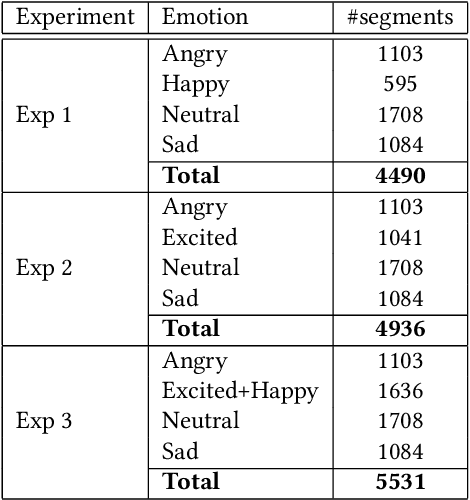
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
HASOCOne@FIRE-HASOC2020: Using BERT and Multilingual BERT models for Hate Speech Detection
Jan 22, 2021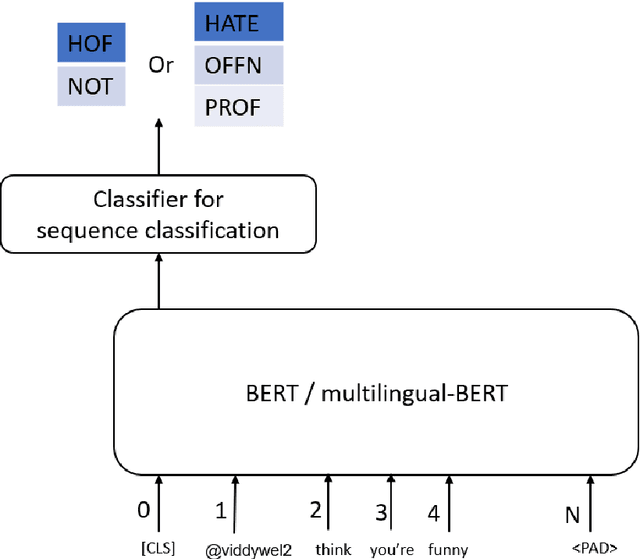
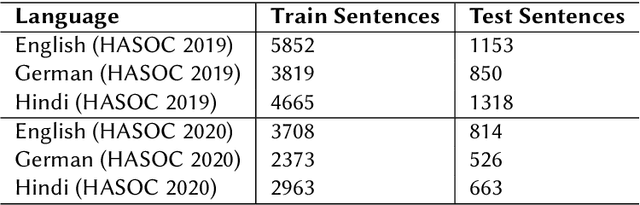
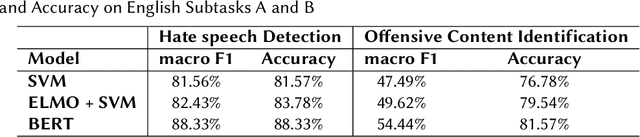
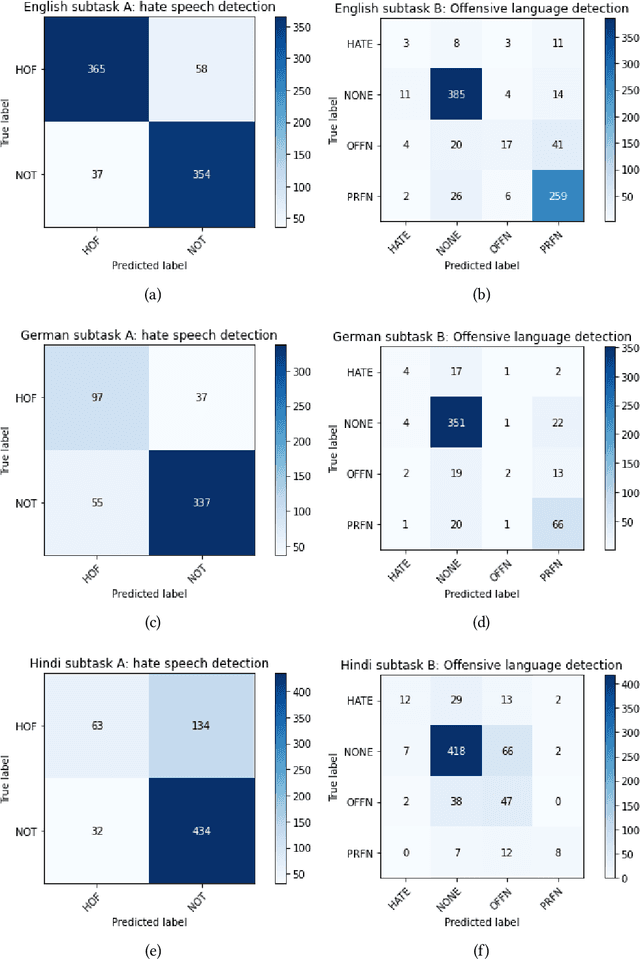
Hateful and Toxic content has become a significant concern in today's world due to an exponential rise in social media. The increase in hate speech and harmful content motivated researchers to dedicate substantial efforts to the challenging direction of hateful content identification. In this task, we propose an approach to automatically classify hate speech and offensive content. We have used the datasets obtained from FIRE 2019 and 2020 shared tasks. We perform experiments by taking advantage of transfer learning models. We observed that the pre-trained BERT model and the multilingual-BERT model gave the best results. The code is made publically available at https://github.com/suman101112/hasoc-fire-2020.
POSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling
Sep 07, 2021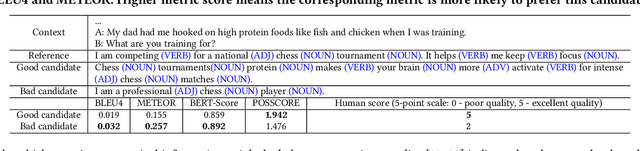
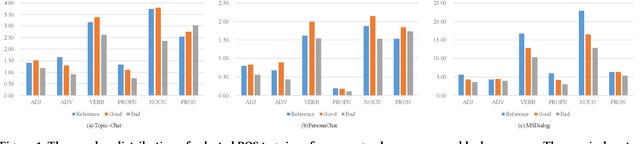
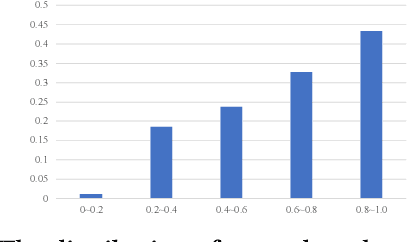
Conversational search systems, such as Google Assistant and Microsoft Cortana, provide a new search paradigm where users are allowed, via natural language dialogues, to communicate with search systems. Evaluating such systems is very challenging since search results are presented in the format of natural language sentences. Given the unlimited number of possible responses, collecting relevance assessments for all the possible responses is infeasible. In this paper, we propose POSSCORE, a simple yet effective automatic evaluation method for conversational search. The proposed embedding-based metric takes the influence of part of speech (POS) of the terms in the response into account. To the best knowledge, our work is the first to systematically demonstrate the importance of incorporating syntactic information, such as POS labels, for conversational search evaluation. Experimental results demonstrate that our metrics can correlate with human preference, achieving significant improvements over state-of-the-art baseline metrics.