 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic Information-based Hierarchical Speech Enhancement Method Using Factorized Codec and Diffusion Model
May 20, 2025Most current speech enhancement (SE) methods recover clean speech from noisy inputs by directly estimating time-frequency masks or spectrums. However, these approaches often neglect the distinct attributes, such as semantic content and acoustic details, inherent in speech signals, which can hinder performance in downstream tasks. Moreover, their effectiveness tends to degrade in complex acoustic environments. To overcome these challenges, we propose a novel, semantic information-based, step-by-step factorized SE method using factorized codec and diffusion model. Unlike traditional SE methods, our hierarchical modeling of semantic and acoustic attributes enables more robust clean speech recovery, particularly in challenging acoustic scenarios. Moreover, this method offers further advantages for downstream TTS tasks. Experimental results demonstrate that our algorithm not only outperforms SOTA baselines in terms of speech quality but also enhances TTS performance in noisy environments.
The NiuTrans Machine Translation Systems for WMT21
Sep 22, 2021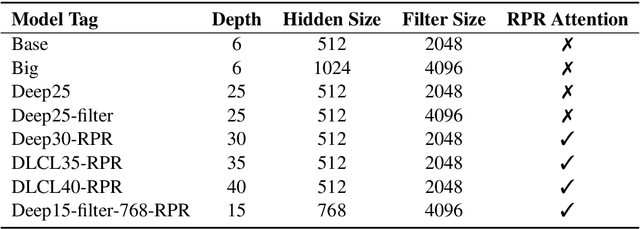
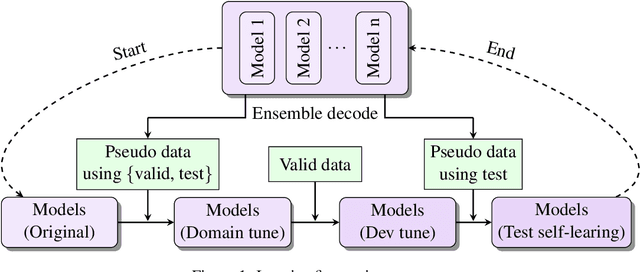
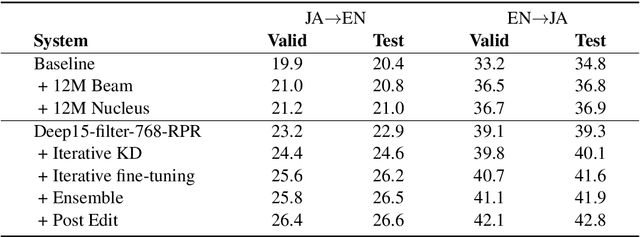
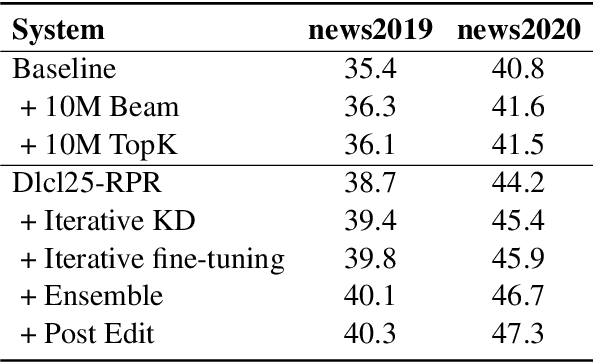
This paper describes NiuTrans neural machine translation systems of the WMT 2021 news translation tasks. We made submissions to 9 language directions, including English$\leftrightarrow$$\{$Chinese, Japanese, Russian, Icelandic$\}$ and English$\rightarrow$Hausa tasks. Our primary systems are built on several effective variants of Transformer, e.g., Transformer-DLCL, ODE-Transformer. We also utilize back-translation, knowledge distillation, post-ensemble, and iterative fine-tuning techniques to enhance the model performance further.
The NiuTrans End-to-End Speech Translation System for IWSLT 2021 Offline Task
Jul 08, 2021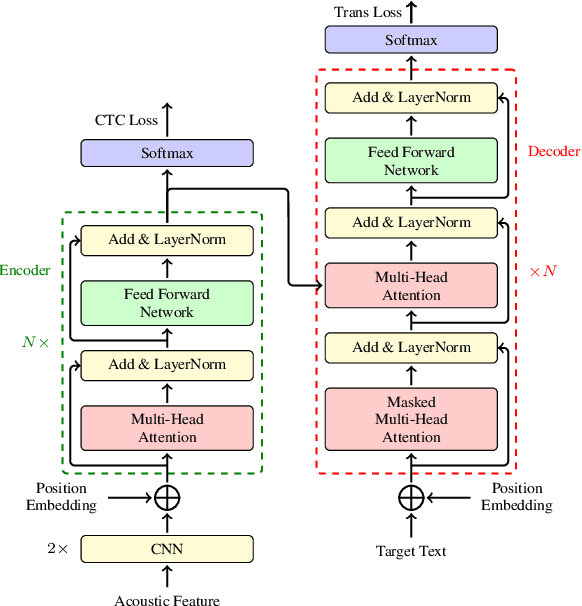
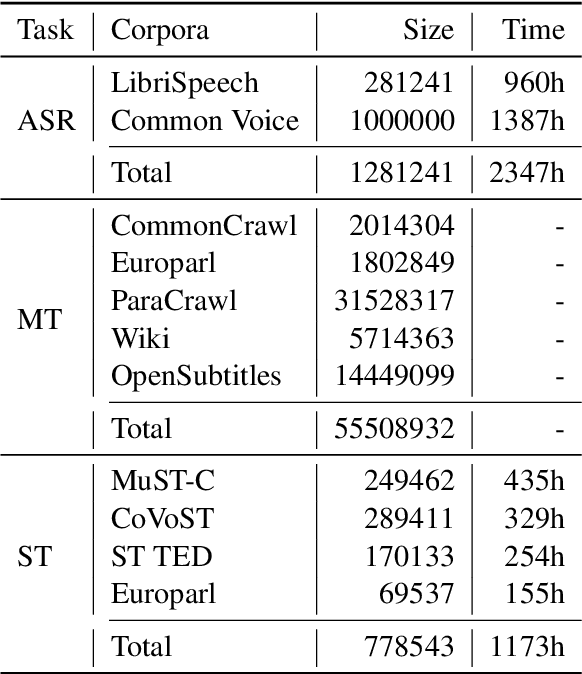
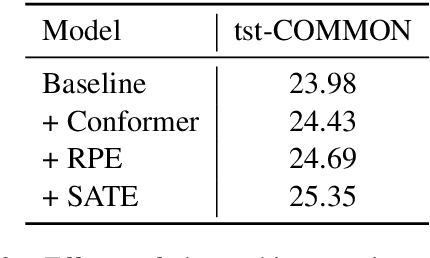
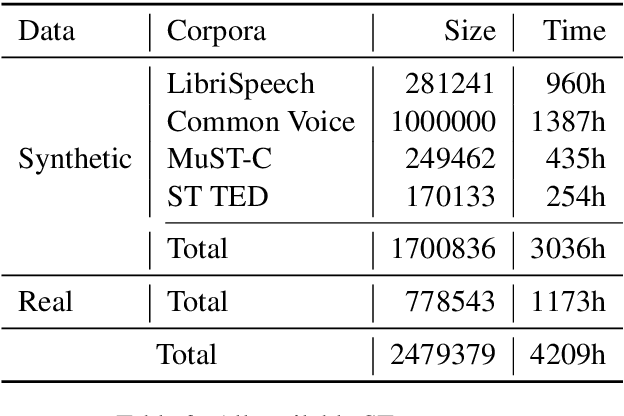
This paper describes the submission of the NiuTrans end-to-end speech translation system for the IWSLT 2021 offline task, which translates from the English audio to German text directly without intermediate transcription. We use the Transformer-based model architecture and enhance it by Conformer, relative position encoding, and stacked acoustic and textual encoding. To augment the training data, the English transcriptions are translated to German translations. Finally, we employ ensemble decoding to integrate the predictions from several models trained with the different datasets. Combining these techniques, we achieve 33.84 BLEU points on the MuST-C En-De test set, which shows the enormous potential of the end-to-end model.