 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming non-autoregressive model for any-to-many voice conversion
Paper and Code
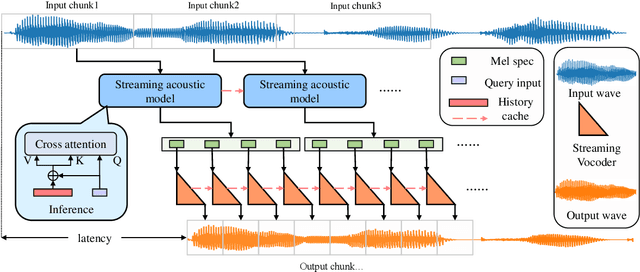
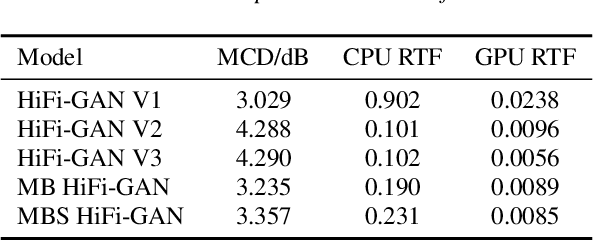
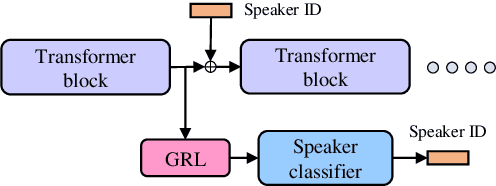
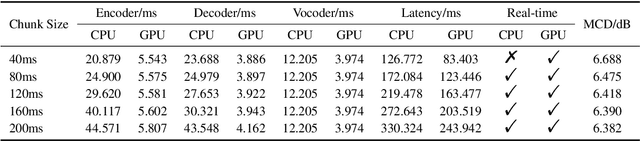
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.