 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Classification of Emotions and Evaluation of Customer Satisfaction from Speech in Real World Acoustic Environments
Aug 26, 2021
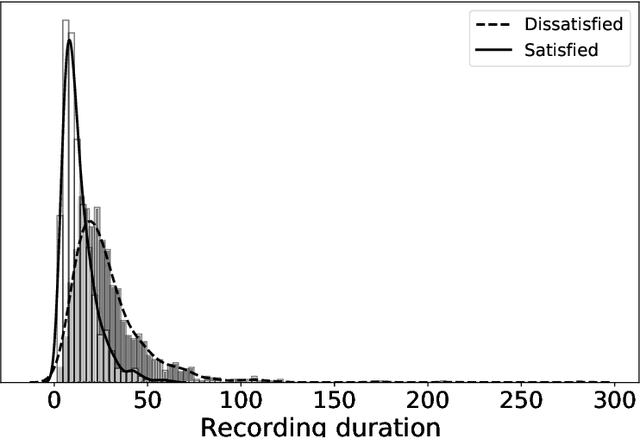
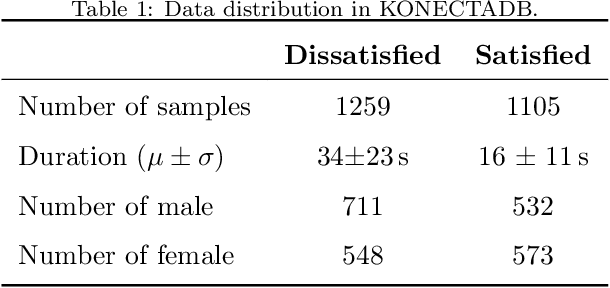

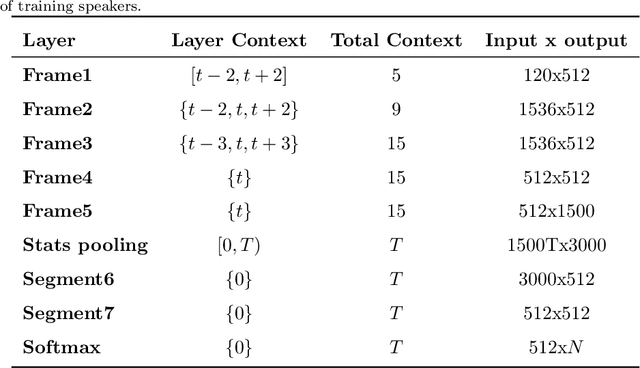
This paper focuses on finding suitable features to robustly recognize emotions and evaluate customer satisfaction from speech in real acoustic scenarios. The classification of emotions is based on standard and well-known corpora and the evaluation of customer satisfaction is based on recordings of real opinions given by customers about the received service during phone calls with call-center agents. The feature sets considered in this study include two speaker models, namely x-vectors and i-vectors, and also the well known feature set introduced in the Interspeech 2010 Paralinguistics Challenge (I2010PC). Additionally, we introduce the use of phonation, articulation and prosody features extracted with the DisVoice framework as alternative feature sets to robustly model emotions and customer satisfaction from speech. The results indicate that the I2010PC feature set is the best approach to classify emotions in the standard databases typically used in the literature. When considering the recordings collected in the call-center, without any control over the acoustic conditions, the best results are obtained with our articulation features. The I2010PC feature set includes 1584 measures while the articulation approach only includes 488 measures. We think that the proposed approach is more suitable for real-world applications where the acoustic conditions are not controlled and also it is potentially more convenient for industrial applications.
Grammar Detection for Sentiment Analysis through Improved Viterbi Algorithm
May 26, 2022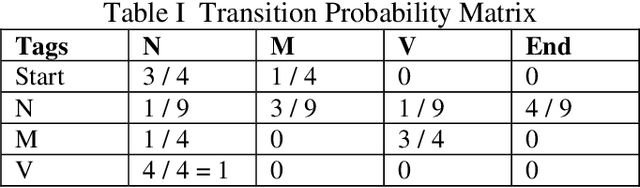
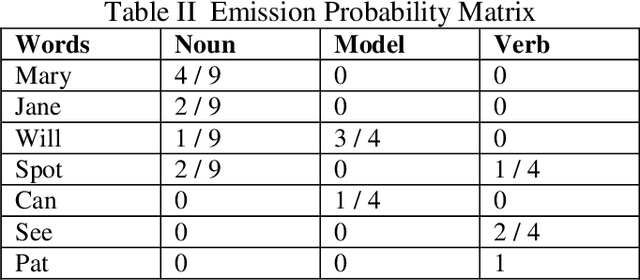
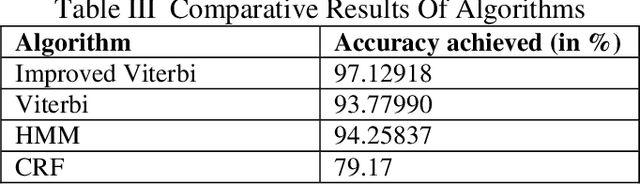
Grammar Detection, also referred to as Parts of Speech Tagging of raw text, is considered an underlying building block of the various Natural Language Processing pipelines like named entity recognition, question answering, and sentiment analysis. In short, forgiven a sentence, Parts of Speech tagging is the task of specifying and tagging each word of a sentence with nouns, verbs, adjectives, adverbs, and more. Sentiment Analysis may well be a procedure accustomed to determining if a given sentence's emotional tone is neutral, positive or negative. To assign polarity scores to the thesis or entities within phrase, in-text analysis and analytics, machine learning and natural language processing, approaches are incorporated. This Sentiment Analysis using POS tagger helps us urge a summary of the broader public over a specific topic. For this, we are using the Viterbi algorithm, Hidden Markov Model, Constraint based Viterbi algorithm for POS tagging. By comparing the accuracies, we select the foremost accurate result of the model for Sentiment Analysis for determining the character of the sentence.
Differentially Private Speaker Anonymization
Feb 23, 2022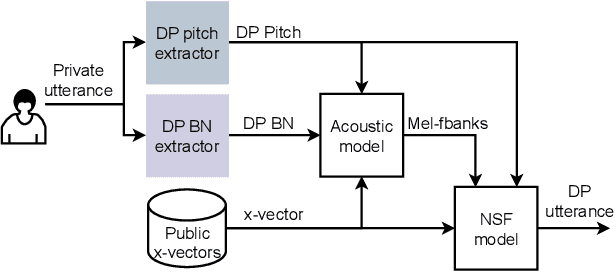
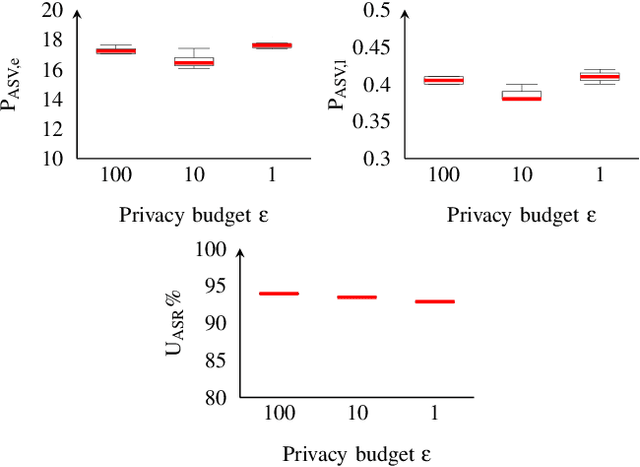
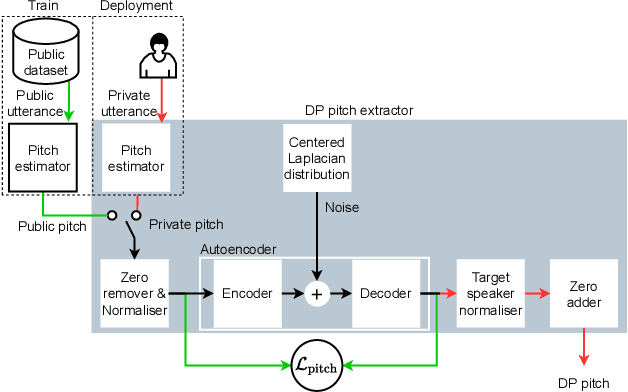
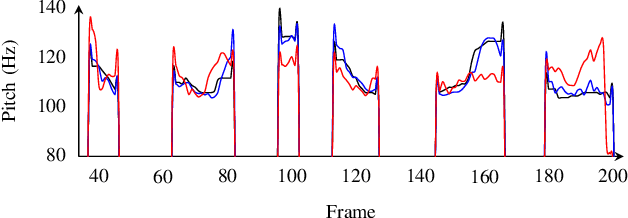
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
Applying wav2vec2.0 to Speech Recognition in various low-resource languages
Dec 22, 2020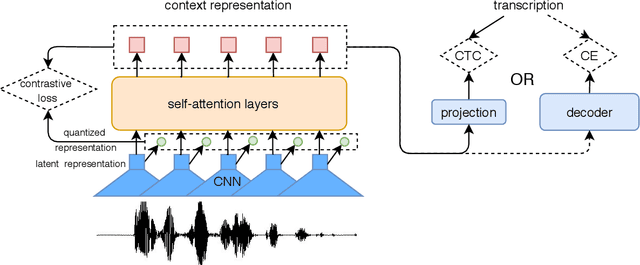
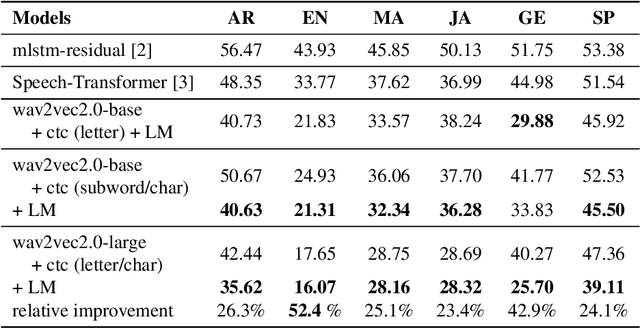
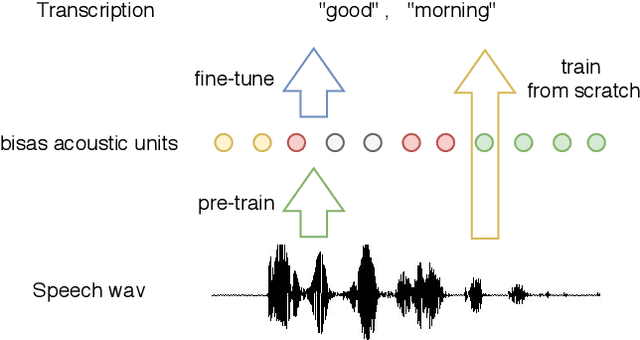
Several domains own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are pre-trained on large amounts of unlabelled data by self-supervision and can be effectively applied for downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on Librispeech corpus. However, this model has not been tested on real spoken scenarios and languages other than English. To verify its universality over languages, we apply the released pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20\% relative improvements in six languages compared with previous works. Among these languages, English improves up to 52.4\%. Moreover, using coarse-grained modeling units, such as subword and character, achieves better results than the letter.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
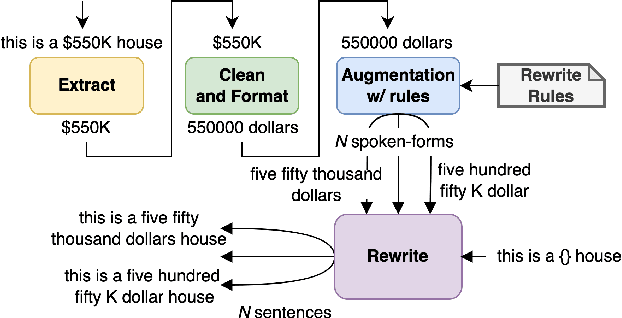

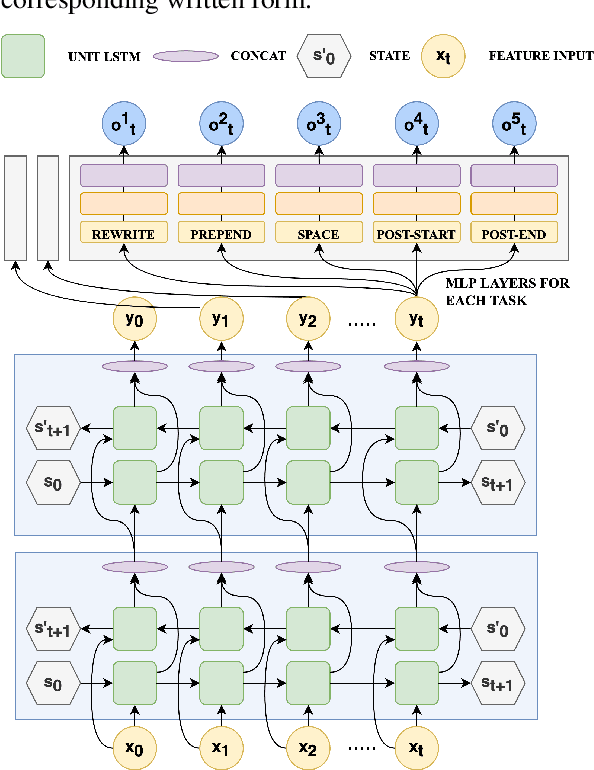
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
fairseq S2T: Fast Speech-to-Text Modeling with fairseq
Oct 11, 2020
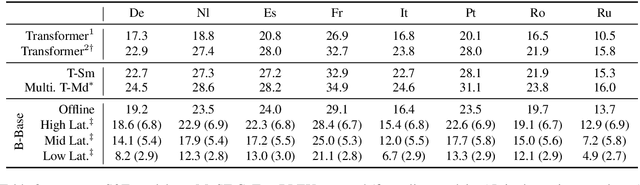

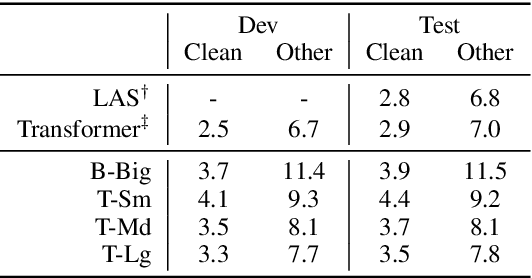
We introduce fairseq S2T, a fairseq extension for speech-to-text (S2T) modeling tasks such as end-to-end speech recognition and speech-to-text translation. It follows fairseq's careful design for scalability and extensibility. We provide end-to-end workflows from data pre-processing, model training to offline (online) inference. We implement state-of-the-art RNN-based as well as Transformer-based models and open-source detailed training recipes. Fairseq's machine translation models and language models can be seamlessly integrated into S2T workflows for multi-task learning or transfer learning. Fairseq S2T documentation and examples are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text.
End-to-End Spectro-Temporal Graph Attention Networks for Speaker Verification Anti-Spoofing and Speech Deepfake Detection
Aug 23, 2021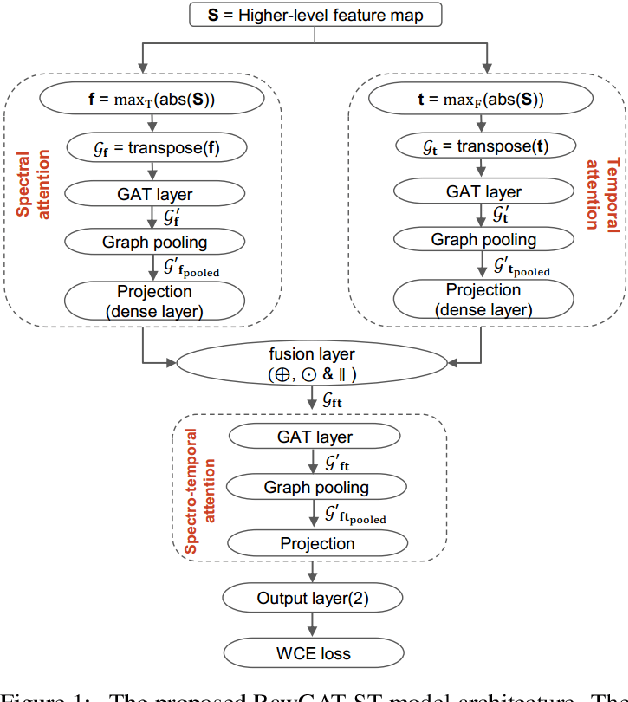
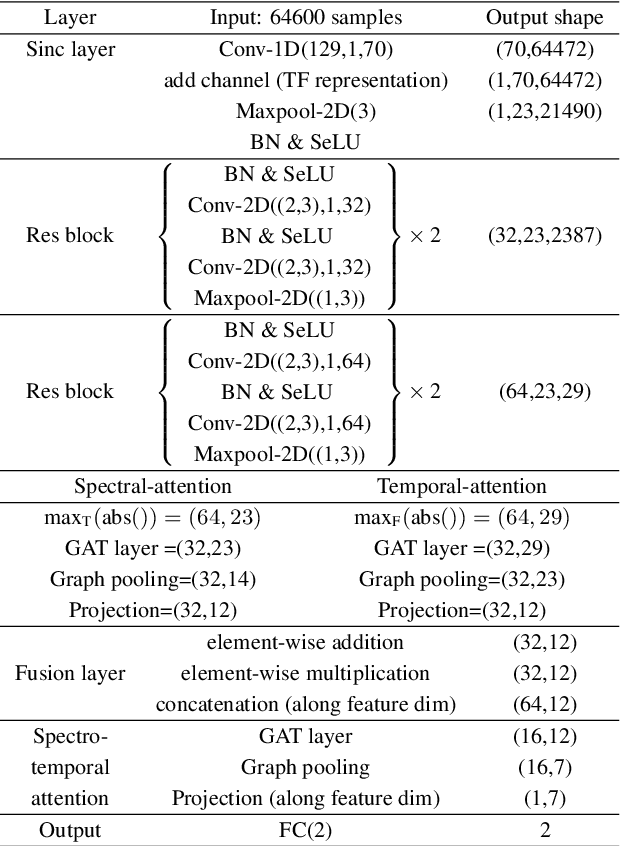
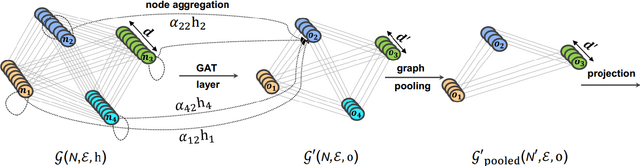

Artefacts that serve to distinguish bona fide speech from spoofed or deepfake speech are known to reside in specific subbands and temporal segments. Various approaches can be used to capture and model such artefacts, however, none works well across a spectrum of diverse spoofing attacks. Reliable detection then often depends upon the fusion of multiple detection systems, each tuned to detect different forms of attack. In this paper we show that better performance can be achieved when the fusion is performed within the model itself and when the representation is learned automatically from raw waveform inputs. The principal contribution is a spectro-temporal graph attention network (GAT) which learns the relationship between cues spanning different sub-bands and temporal intervals. Using a model-level graph fusion of spectral (S) and temporal (T) sub-graphs and a graph pooling strategy to improve discrimination, the proposed RawGAT-ST model achieves an equal error rate of 1.06 % for the ASVspoof 2019 logical access database. This is one of the best results reported to date and is reproducible using an open source implementation.
ASR Error Correction with Constrained Decoding on Operation Prediction
Aug 09, 2022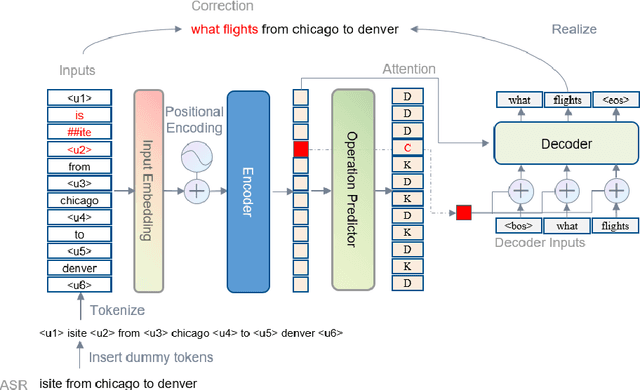
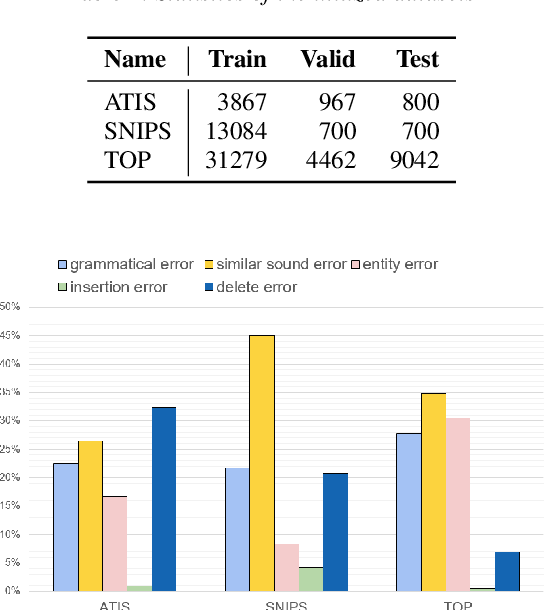
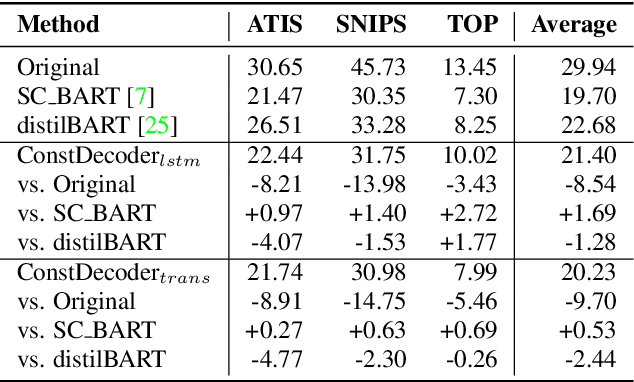
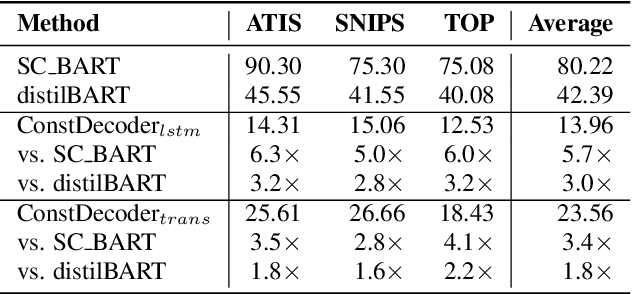
Error correction techniques remain effective to refine outputs from automatic speech recognition (ASR) models. Existing end-to-end error correction methods based on an encoder-decoder architecture process all tokens in the decoding phase, creating undesirable latency. In this paper, we propose an ASR error correction method utilizing the predictions of correction operations. More specifically, we construct a predictor between the encoder and the decoder to learn if a token should be kept ("K"), deleted ("D"), or changed ("C") to restrict decoding to only part of the input sequence embeddings (the "C" tokens) for fast inference. Experiments on three public datasets demonstrate the effectiveness of the proposed approach in reducing the latency of the decoding process in ASR correction. It enhances the inference speed by at least three times (3.4 and 5.7 times) while maintaining the same level of accuracy (with WER reductions of 0.53% and 1.69% respectively) for our two proposed models compared to a solid encoder-decoder baseline. In the meantime, we produce and release a benchmark dataset contributing to the ASR error correction community to foster research along this line.
Efficient conformer-based speech recognition with linear attention
Apr 14, 2021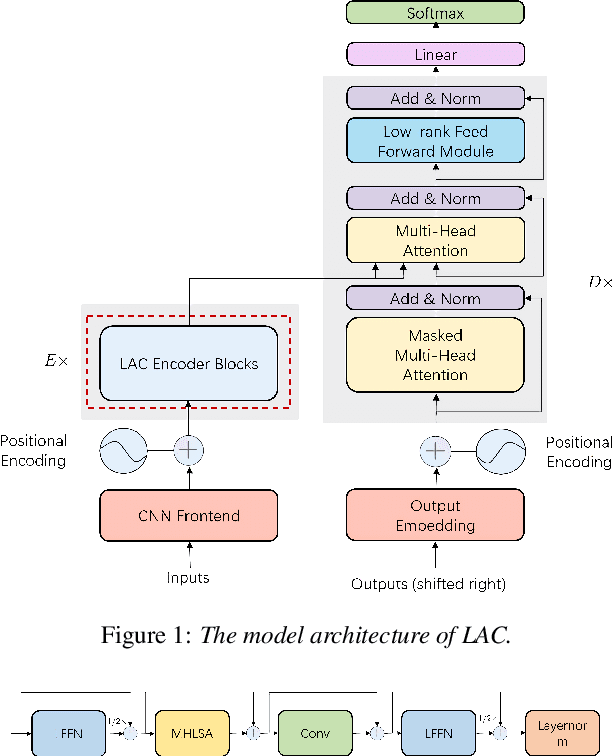
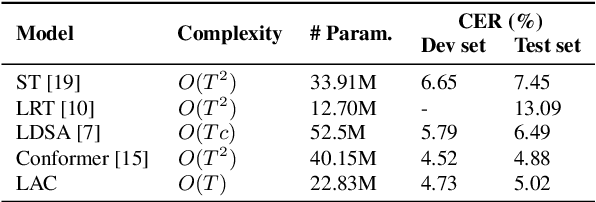
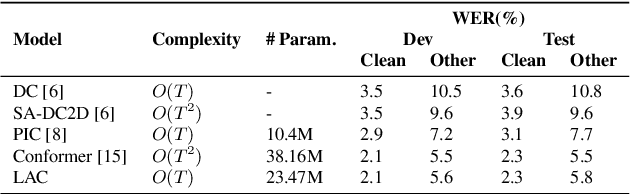
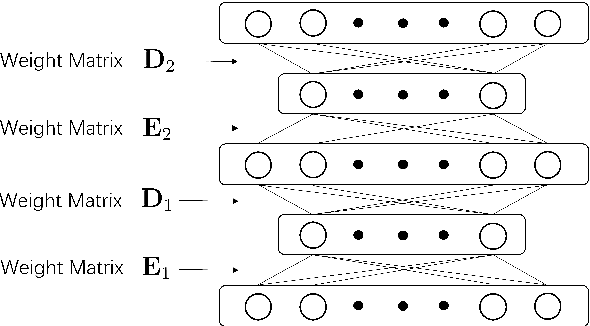
Recently, conformer-based end-to-end automatic speech recognition, which outperforms recurrent neural network based ones, has received much attention. Although the parallel computing of conformer is more efficient than recurrent neural networks, the computational complexity of its dot-product self-attention is quadratic with respect to the length of the input feature. To reduce the computational complexity of the self-attention layer, we propose multi-head linear self-attention for the self-attention layer, which reduces its computational complexity to linear order. In addition, we propose to factorize the feed forward module of the conformer by low-rank matrix factorization, which successfully reduces the number of the parameters by approximate 50% with little performance loss. The proposed model, named linear attention based conformer (LAC), can be trained and inferenced jointly with the connectionist temporal classification objective, which further improves the performance of LAC. To evaluate the effectiveness of LAC, we conduct experiments on the AISHELL-1 and LibriSpeech corpora. Results show that the proposed LAC achieves better performance than 7 recently proposed speech recognition models, and is competitive with the state-of-the-art conformer. Meanwhile, the proposed LAC has a number of parameters of only 50% over the conformer with faster training speed than the latter.
Similarity Analysis of Self-Supervised Speech Representations
Oct 22, 2020
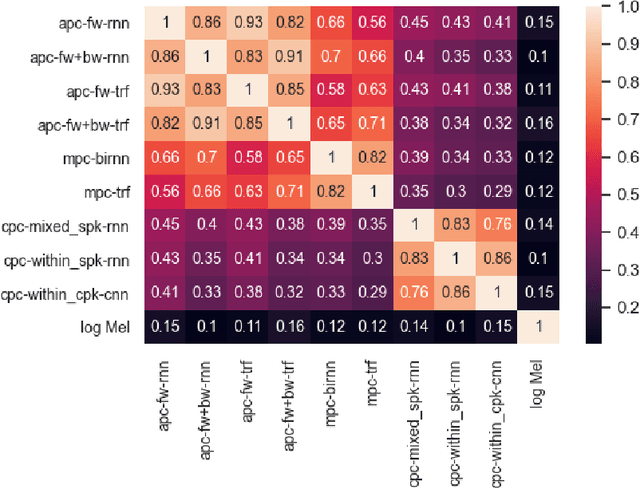
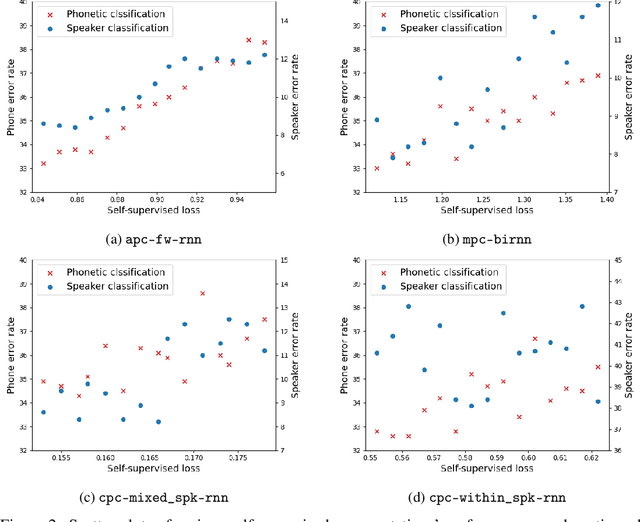
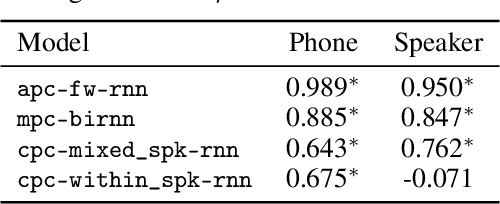
Self-supervised speech representation learning has recently been a prosperous research topic. Many algorithms have been proposed for learning useful representations from large-scale unlabeled data, and their applications to a wide range of speech tasks have also been investigated. However, there has been little research focusing on understanding the properties of existing approaches. In this work, we aim to provide a comparative study of some of the most representative self-supervised algorithms. Specifically, we quantify the similarities between different self-supervised representations using existing similarity measures. We also design probing tasks to study the correlation between the models' pre-training loss and the amount of specific speech information contained in their learned representations. In addition to showing how various self-supervised models behave differently given the same input, our study also finds that the training objective has a higher impact on representation similarity than architectural choices such as building blocks (RNN/Transformer/CNN) and directionality (uni/bidirectional). Our results also suggest that there exists a strong correlation between pre-training loss and downstream performance for some self-supervised algorithms.