 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Spoken Dialogue Models from User Interactions
Jun 26, 2025We propose a novel preference alignment framework for improving spoken dialogue models on real-time conversations from user interactions. Current preference learning methods primarily focus on text-based language models, and are not directly suited to the complexities of real-time speech interactions, with richer dynamics (e.g. interruption, interjection) and no explicit segmentation between speaker turns.We create a large-scale dataset of more than 150,000 preference pairs from raw multi-turn speech conversations, annotated with AI feedback, to cover preferences over both linguistic content and temporal context variations. We leverage offline alignment methods to finetune a full-duplex autoregressive speech-to-speech model. Extensive experiments demonstrate that feedback on generic conversations can be consistently effective in improving spoken dialogue models to produce more factual, safer and more contextually aligned interactions. We deploy the finetuned model and conduct holistic human evaluations to assess the impact beyond single-turn conversations. Our findings shed light on the importance of a well-calibrated balance among various dynamics, crucial for natural real-time speech dialogue systems.
Imitation Learning from a Single Temporally Misaligned Video
Feb 08, 2025



We examine the problem of learning sequential tasks from a single visual demonstration. A key challenge arises when demonstrations are temporally misaligned due to variations in timing, differences in embodiment, or inconsistencies in execution. Existing approaches treat imitation as a distribution-matching problem, aligning individual frames between the agent and the demonstration. However, we show that such frame-level matching fails to enforce temporal ordering or ensure consistent progress. Our key insight is that matching should instead be defined at the level of sequences. We propose that perfect matching occurs when one sequence successfully covers all the subgoals in the same order as the other sequence. We present ORCA (ORdered Coverage Alignment), a dense per-timestep reward function that measures the probability of the agent covering demonstration frames in the correct order. On temporally misaligned demonstrations, we show that agents trained with the ORCA reward achieve $4.5$x improvement ($0.11 \rightarrow 0.50$ average normalized returns) for Meta-world tasks and $6.6$x improvement ($6.55 \rightarrow 43.3$ average returns) for Humanoid-v4 tasks compared to the best frame-level matching algorithms. We also provide empirical analysis showing that ORCA is robust to varying levels of temporal misalignment. Our code is available at https://github.com/portal-cornell/orca/
Retrospective Learning from Interactions
Oct 17, 2024



Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.
A Surprising Failure? Multimodal LLMs and the NLVR Challenge
Feb 26, 2024This study evaluates three state-of-the-art MLLMs -- GPT-4V, Gemini Pro, and the open-source model IDEFICS -- on the compositional natural language vision reasoning task NLVR. Given a human-written sentence paired with a synthetic image, this task requires the model to determine the truth value of the sentence with respect to the image. Despite the strong performance demonstrated by these models, we observe they perform poorly on NLVR, which was constructed to require compositional and spatial reasoning, and to be robust for semantic and systematic biases.
lilGym: Natural Language Visual Reasoning with Reinforcement Learning
Nov 03, 2022We present lilGym, a new benchmark for language-conditioned reinforcement learning in visual environments. lilGym is based on 2,661 highly-compositional human-written natural language statements grounded in an interactive visual environment. We annotate all statements with executable Python programs representing their meaning to enable exact reward computation in every possible world state. Each statement is paired with multiple start states and reward functions to form thousands of distinct Markov Decision Processes of varying difficulty. We experiment with lilGym with different models and learning regimes. Our results and analysis show that while existing methods are able to achieve non-trivial performance, lilGym forms a challenging open problem. lilGym is available at https://lil.nlp.cornell.edu/lilgym/.
Large-Scale Self- and Semi-Supervised Learning for Speech Translation
Apr 14, 2021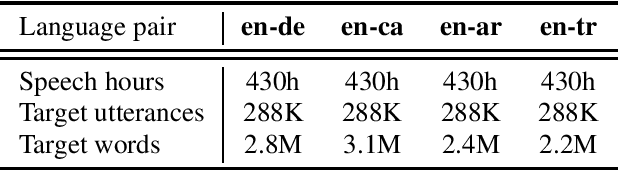
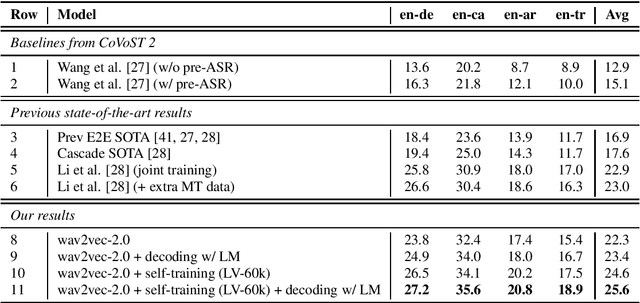

In this paper, we improve speech translation (ST) through effectively leveraging large quantities of unlabeled speech and text data in different and complementary ways. We explore both pretraining and self-training by using the large Libri-Light speech audio corpus and language modeling with CommonCrawl. Our experiments improve over the previous state of the art by 2.6 BLEU on average on all four considered CoVoST 2 language pairs via a simple recipe of combining wav2vec 2.0 pretraining, a single iteration of self-training and decoding with a language model. Different to existing work, our approach does not leverage any other supervision than ST data. Code and models will be publicly released.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021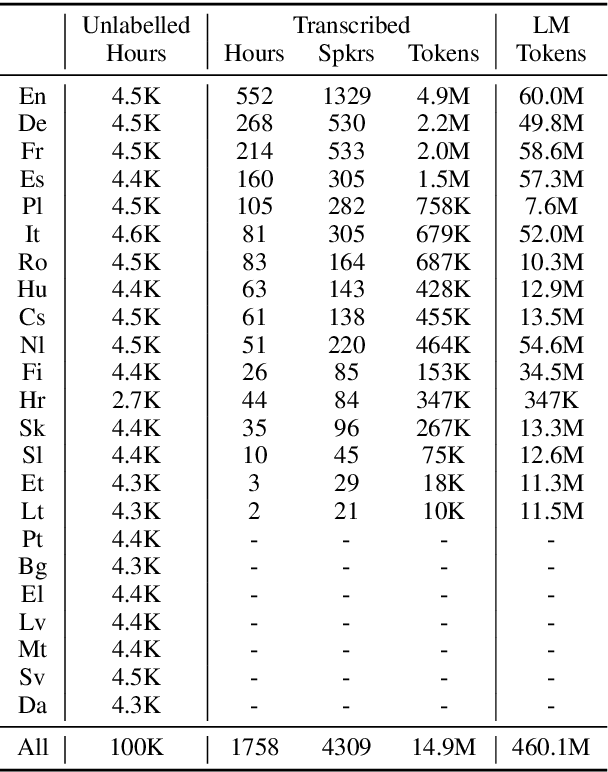
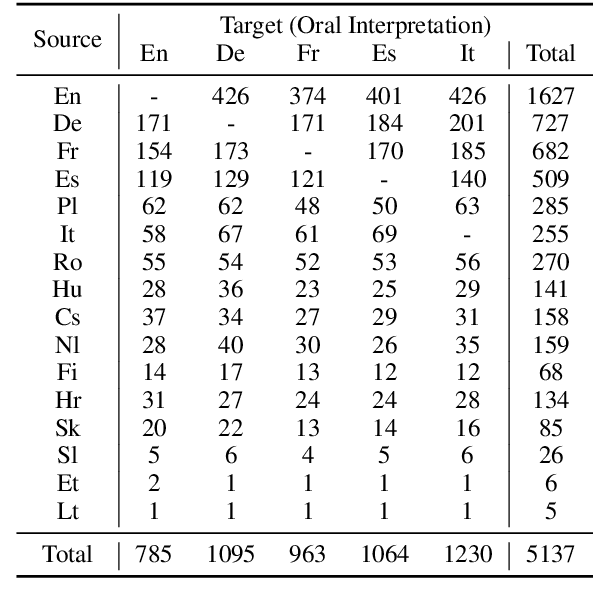

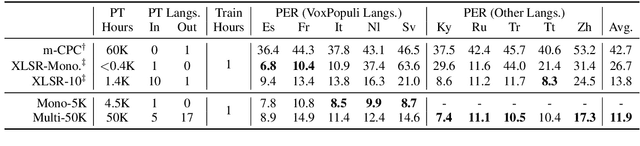
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
fairseq S2T: Fast Speech-to-Text Modeling with fairseq
Oct 11, 2020
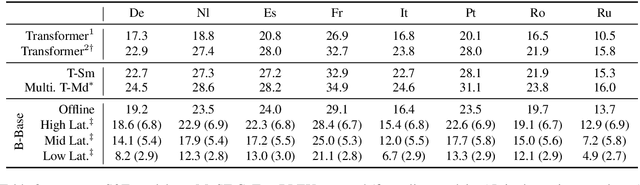

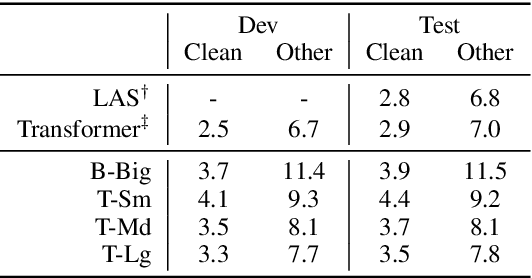
We introduce fairseq S2T, a fairseq extension for speech-to-text (S2T) modeling tasks such as end-to-end speech recognition and speech-to-text translation. It follows fairseq's careful design for scalability and extensibility. We provide end-to-end workflows from data pre-processing, model training to offline (online) inference. We implement state-of-the-art RNN-based as well as Transformer-based models and open-source detailed training recipes. Fairseq's machine translation models and language models can be seamlessly integrated into S2T workflows for multi-task learning or transfer learning. Fairseq S2T documentation and examples are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text.
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
Aug 20, 2020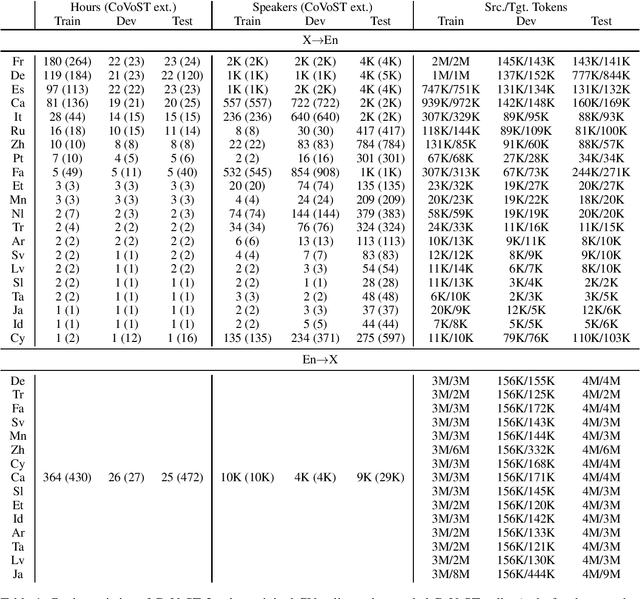
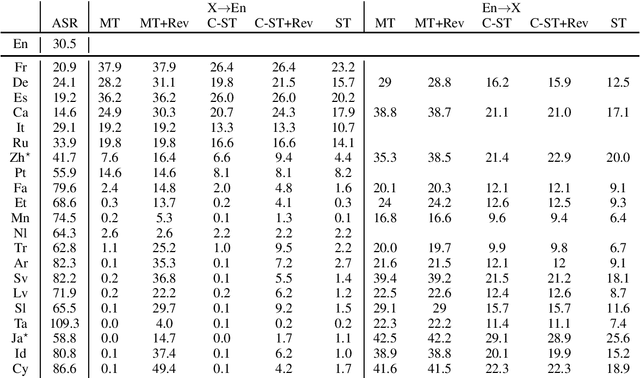
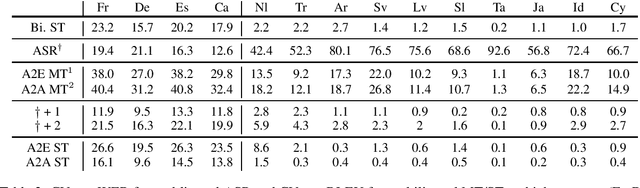
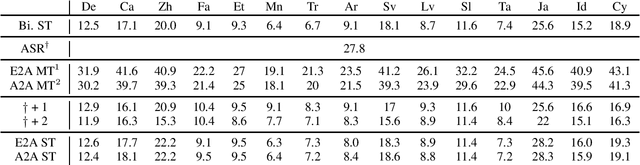
Speech translation has recently become an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research in massive multilingual speech translation and speech translation for low resource language pairs, we release CoVoST 2, a large-scale multilingual speech translation corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date from total volume and language coverage perspective. Data sanity checks provide evidence about the quality of the data, which is released under CC0 license. We also provide extensive speech recognition, bilingual and multilingual machine translation and speech translation baselines.
Self-Supervised Representations Improve End-to-End Speech Translation
Jun 22, 2020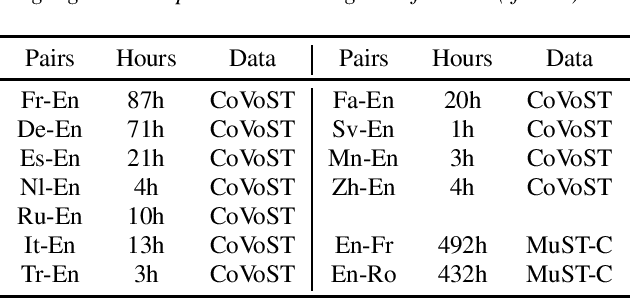
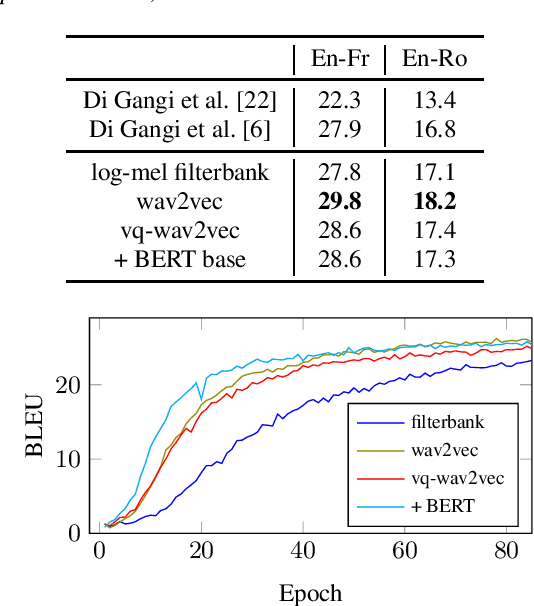
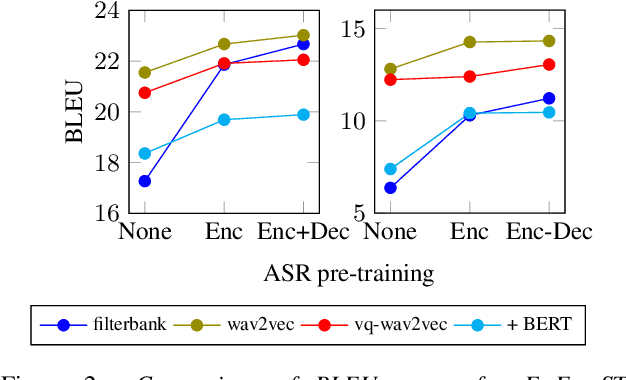
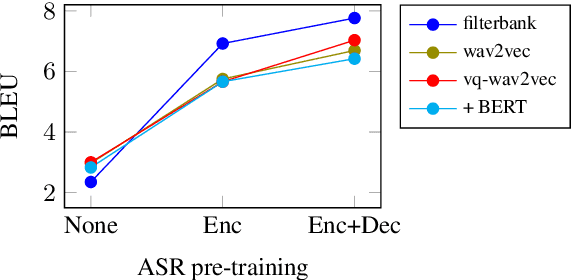
End-to-end speech-to-text translation can provide a simpler and smaller system but is facing the challenge of data scarcity. Pre-training methods can leverage unlabeled data and have been shown to be effective on data-scarce settings. In this work, we explore whether self-supervised pre-trained speech representations can benefit the speech translation task in both high- and low-resource settings, whether they can transfer well to other languages, and whether they can be effectively combined with other common methods that help improve low-resource end-to-end speech translation such as using a pre-trained high-resource speech recognition system. We demonstrate that self-supervised pre-trained features can consistently improve the translation performance, and cross-lingual transfer allows to extend to a variety of languages without or with little tuning.