 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Transferable Spatiotemporal Representations from Natural Script Knowledge
Sep 30, 2022
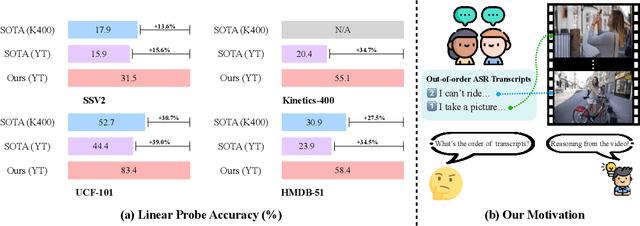
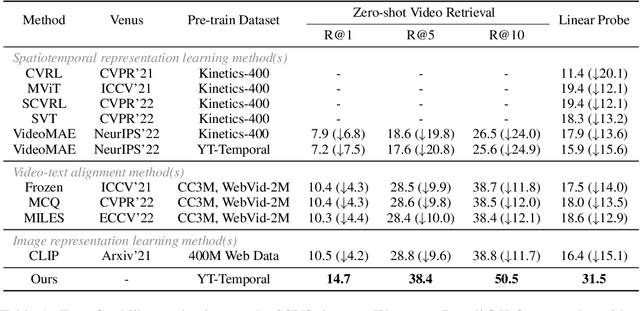
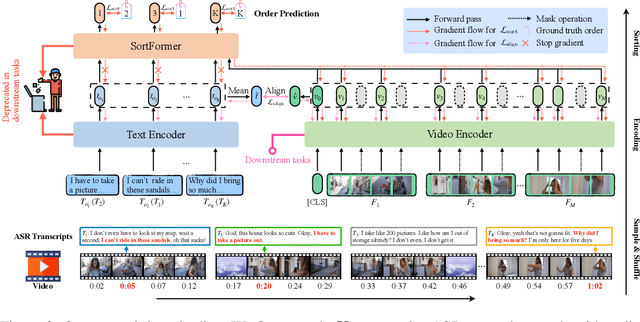
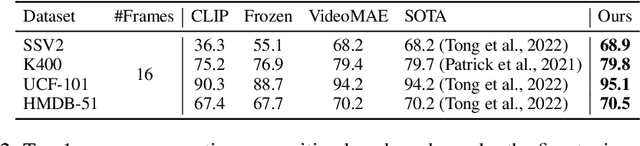
Pre-training on large-scale video data has become a common recipe for learning transferable spatiotemporal representations in recent years. Despite some progress, existing methods are mostly limited to highly curated datasets (e.g., K400) and exhibit unsatisfactory out-of-the-box representations. We argue that it is due to the fact that they only capture pixel-level knowledge rather than spatiotemporal commonsense, which is far away from cognition-level video understanding. Inspired by the great success of image-text pre-training (e.g., CLIP), we take the first step to exploit language semantics to boost transferable spatiotemporal representation learning. We introduce a new pretext task, Turning to Video for Transcript Sorting (TVTS), which sorts shuffled ASR scripts by attending to learned video representations. We do not rely on descriptive captions and learn purely from video, i.e., leveraging the natural transcribed speech knowledge to provide noisy but useful semantics over time. Furthermore, rather than the simple concept learning in vision-caption contrast, we encourage cognition-level temporal commonsense reasoning via narrative reorganization. The advantages enable our model to contextualize what is happening like human beings and seamlessly apply to large-scale uncurated video data in the real world. Note that our method differs from ones designed for video-text alignment (e.g., Frozen) and multimodal representation learning (e.g., Merlot). Our method demonstrates strong out-of-the-box spatiotemporal representations on diverse video benchmarks, e.g., +13.6% gains over VideoMAE on SSV2 via linear probing.
Exploring CTC Based End-to-End Techniques for Myanmar Speech Recognition
May 14, 2021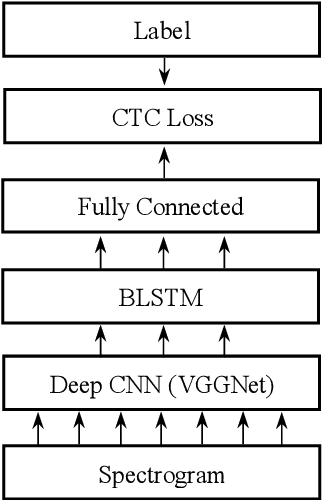
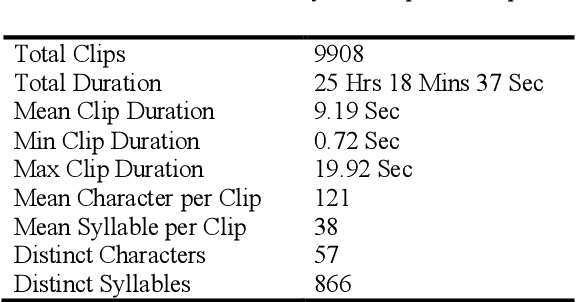
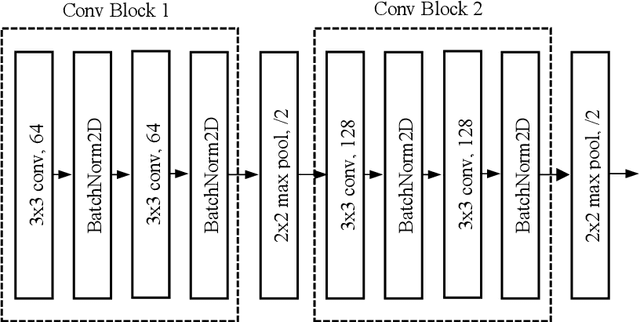
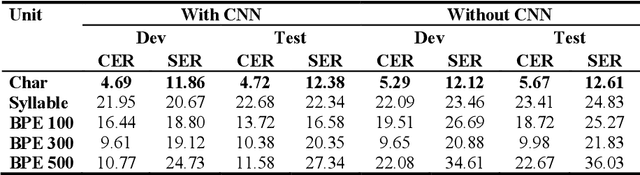
In this work, we explore a Connectionist Temporal Classification (CTC) based end-to-end Automatic Speech Recognition (ASR) model for the Myanmar language. A series of experiments is presented on the topology of the model in which the convolutional layers are added and dropped, different depths of bidirectional long short-term memory (BLSTM) layers are used and different label encoding methods are investigated. The experiments are carried out in low-resource scenarios using our recorded Myanmar speech corpus of nearly 26 hours. The best model achieves character error rate (CER) of 4.72% and syllable error rate (SER) of 12.38% on the test set.
* This is a preprint of the chapter: Chit K.M.M., Lin L.L., Exploring CTC Based End-To-End Techniques for Myanmar Speech Recognition, published in Advances in Intelligent Systems and Computing, vol 1324, edited by Vasant P., Zelinka I., Weber GW., 2021, Springer, Cham reproduced with permission of Springer. The final authenticated version is available at https://doi.org/10.1007/978-3-030-68154-8_87
Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement
Jun 05, 2021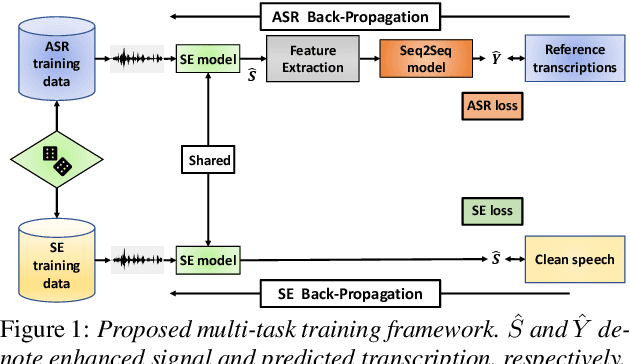
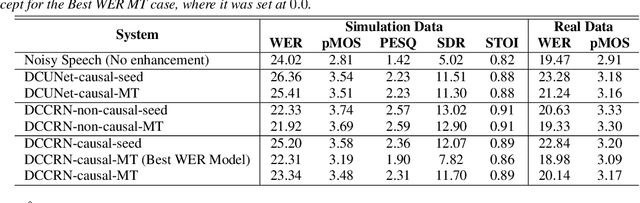
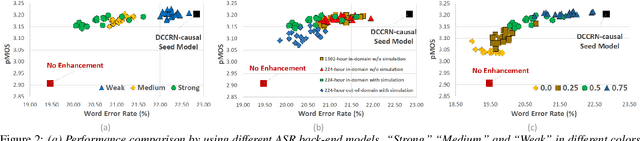
With the surge of online meetings, it has become more critical than ever to provide high-quality speech audio and live captioning under various noise conditions. However, most monaural speech enhancement (SE) models introduce processing artifacts and thus degrade the performance of downstream tasks, including automatic speech recognition (ASR). This paper proposes a multi-task training framework to make the SE models unharmful to ASR. Because most ASR training samples do not have corresponding clean signal references, we alternately perform two model update steps called SE-step and ASR-step. The SE-step uses clean and noisy signal pairs and a signal-based loss function. The ASR-step applies a pre-trained ASR model to training signals enhanced with the SE model. A cross-entropy loss between the ASR output and reference transcriptions is calculated to update the SE model parameters. Experimental results with realistic large-scale settings using ASR models trained on 75,000-hour data show that the proposed framework improves the word error rate for the SE output by 11.82% with little compromise in the SE quality. Performance analysis is also carried out by changing the ASR model, the data used for the ASR-step, and the schedule of the two update steps.
ILASR: Privacy-Preserving Incremental Learning for AutomaticSpeech Recognition at Production Scale
Jul 19, 2022
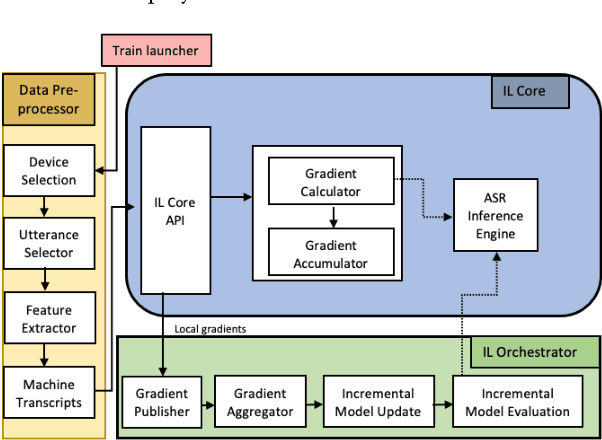
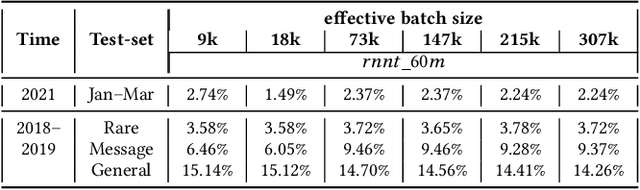
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
Acoustic-Linguistic Features for Modeling Neurological Task Score in Alzheimer's
Sep 13, 2022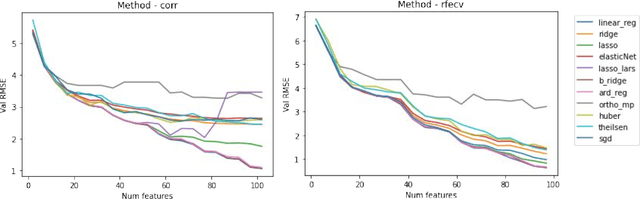
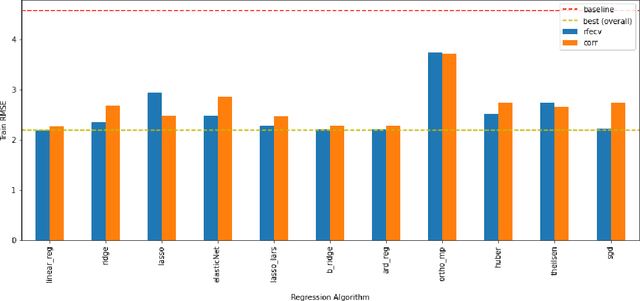
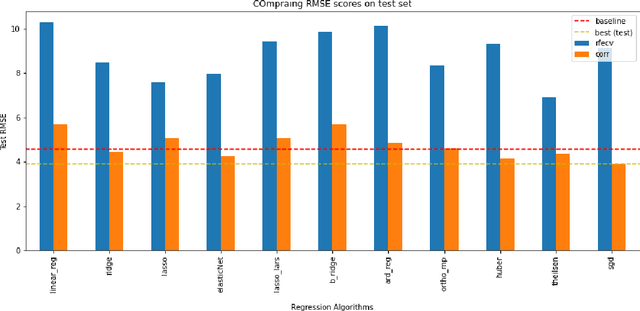
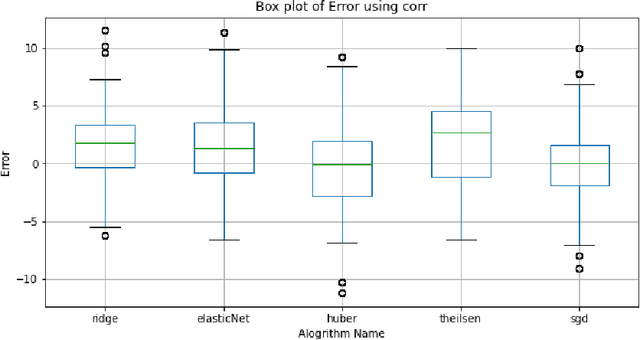
The average life expectancy is increasing globally due to advancements in medical technology, preventive health care, and a growing emphasis on gerontological health. Therefore, developing technologies that detect and track aging-associated disease in cognitive function among older adult populations is imperative. In particular, research related to automatic detection and evaluation of Alzheimer's disease (AD) is critical given the disease's prevalence and the cost of current methods. As AD impacts the acoustics of speech and vocabulary, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of ten linear regression models for predicting Mini-Mental Status Exam scores on the ADReSS challenge dataset. We extracted 13000+ handcrafted and learned features that capture linguistic and acoustic phenomena. Using a subset of 54 top features selected by two methods: (1) recursive elimination and (2) correlation scores, we outperform a state-of-the-art baseline for the same task. Upon scoring and evaluating the statistical significance of each of the selected subset of features for each model, we find that, for the given task, handcrafted linguistic features are more significant than acoustic and learned features.
Semi-supervised Learning for Multi-speaker Text-to-speech Synthesis Using Discrete Speech Representation
May 16, 2020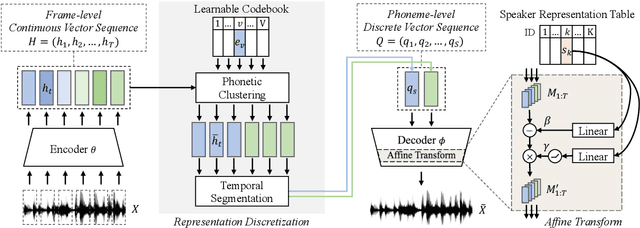

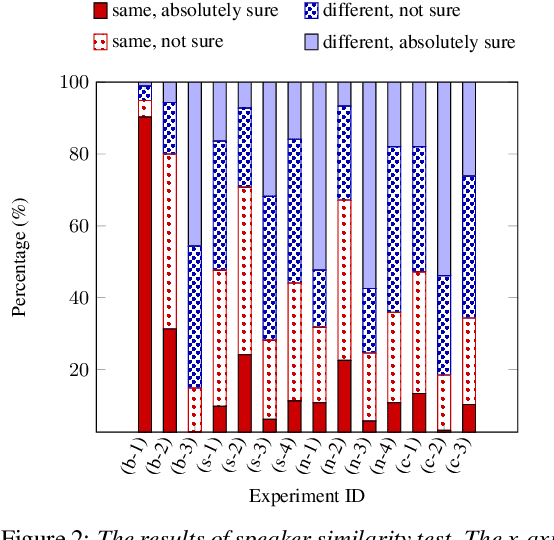
Recently, end-to-end multi-speaker text-to-speech (TTS) systems gain success in the situation where a lot of high-quality speech plus their corresponding transcriptions are available. However, laborious paired data collection processes prevent many institutes from building multi-speaker TTS systems of great performance. In this work, we propose a semi-supervised learning approach for multi-speaker TTS. A multi-speaker TTS model can learn from the untranscribed audio via the proposed encoder-decoder framework with discrete speech representation. The experiment results demonstrate that with only an hour of paired speech data, no matter the paired data is from multiple speakers or a single speaker, the proposed model can generate intelligible speech in different voices. We found the model can benefit from the proposed semi-supervised learning approach even when part of the unpaired speech data is noisy. In addition, our analysis reveals that different speaker characteristics of the paired data have an impact on the effectiveness of semi-supervised TTS.
The USTC-NELSLIP Systems for Simultaneous Speech Translation Task at IWSLT 2021
Jul 09, 2021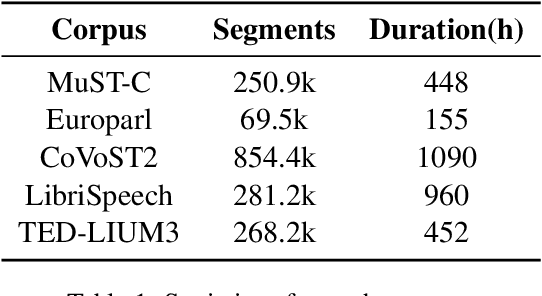
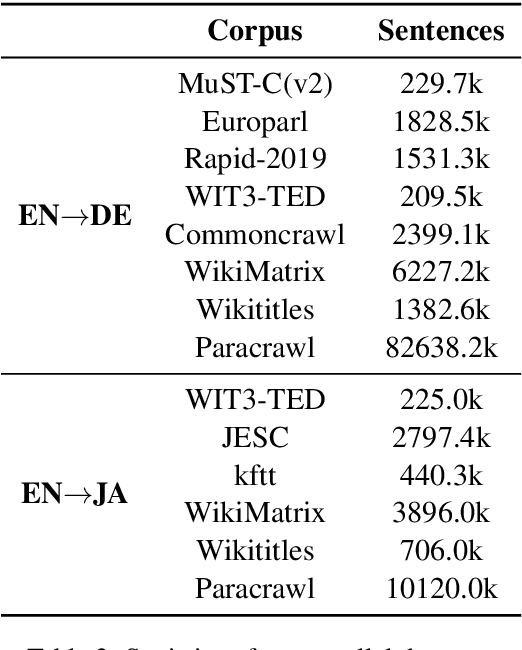
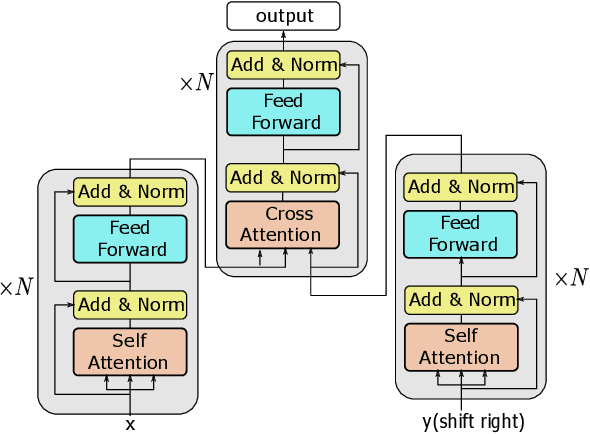
This paper describes USTC-NELSLIP's submissions to the IWSLT2021 Simultaneous Speech Translation task. We proposed a novel simultaneous translation model, Cross Attention Augmented Transducer (CAAT), which extends conventional RNN-T to sequence-to-sequence tasks without monotonic constraints, e.g., simultaneous translation. Experiments on speech-to-text (S2T) and text-to-text (T2T) simultaneous translation tasks shows CAAT achieves better quality-latency trade-offs compared to \textit{wait-k}, one of the previous state-of-the-art approaches. Based on CAAT architecture and data augmentation, we build S2T and T2T simultaneous translation systems in this evaluation campaign. Compared to last year's optimal systems, our S2T simultaneous translation system improves by an average of 11.3 BLEU for all latency regimes, and our T2T simultaneous translation system improves by an average of 4.6 BLEU.
Improving Punctuation Restoration for Speech Transcripts via External Data
Oct 01, 2021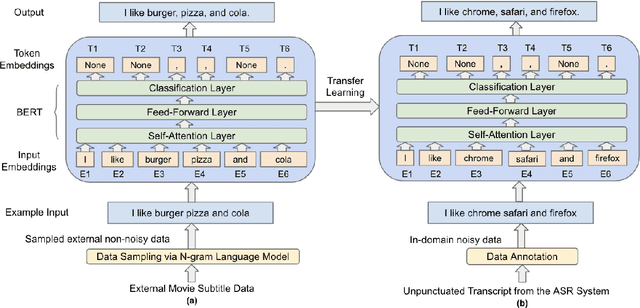

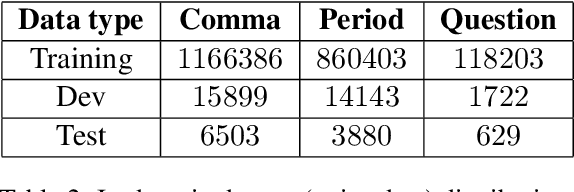

Automatic Speech Recognition (ASR) systems generally do not produce punctuated transcripts. To make transcripts more readable and follow the expected input format for downstream language models, it is necessary to add punctuation marks. In this paper, we tackle the punctuation restoration problem specifically for the noisy text (e.g., phone conversation scenarios). To leverage the available written text datasets, we introduce a data sampling technique based on an n-gram language model to sample more training data that are similar to our in-domain data. Moreover, we propose a two-stage fine-tuning approach that utilizes the sampled external data as well as our in-domain dataset for models based on BERT. Extensive experiments show that the proposed approach outperforms the baseline with an improvement of 1:12% F1 score.
Bridging the prosody GAP: Genetic Algorithm with People to efficiently sample emotional prosody
May 10, 2022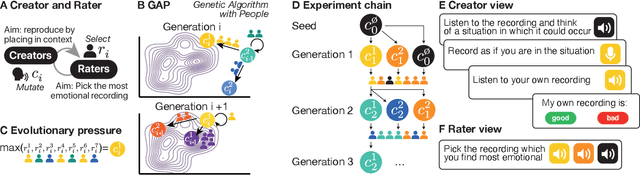
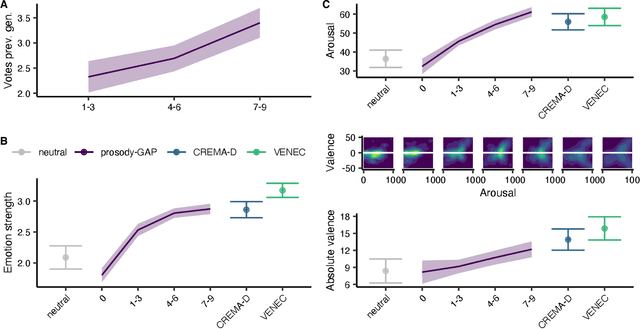
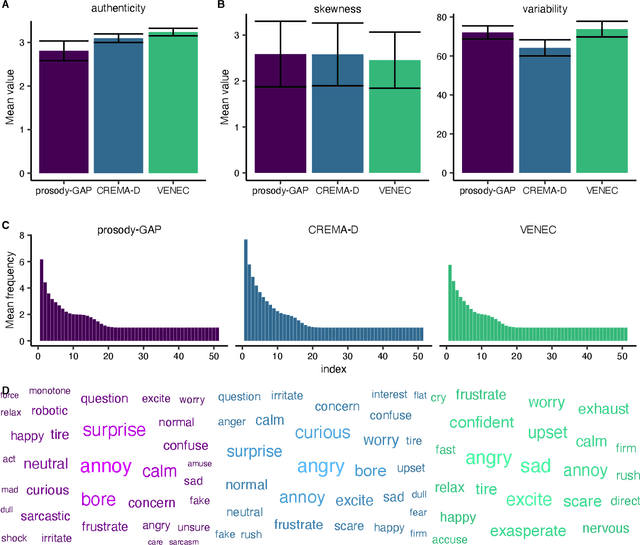
The human voice effectively communicates a range of emotions with nuanced variations in acoustics. Existing emotional speech corpora are limited in that they are either (a) highly curated to induce specific emotions with predefined categories that may not capture the full extent of emotional experiences, or (b) entangled in their semantic and prosodic cues, limiting the ability to study these cues separately. To overcome this challenge, we propose a new approach called 'Genetic Algorithm with People' (GAP), which integrates human decision and production into a genetic algorithm. In our design, we allow creators and raters to jointly optimize the emotional prosody over generations. We demonstrate that GAP can efficiently sample from the emotional speech space and capture a broad range of emotions, and show comparable results to state-of-the-art emotional speech corpora. GAP is language-independent and supports large crowd-sourcing, thus can support future large-scale cross-cultural research.