 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis Across Multiple African Languages: A Current Benchmark
Oct 21, 2023Sentiment analysis is a fundamental and valuable task in NLP. However, due to limitations in data and technological availability, research into sentiment analysis of African languages has been fragmented and lacking. With the recent release of the AfriSenti-SemEval Shared Task 12, hosted as a part of The 17th International Workshop on Semantic Evaluation, an annotated sentiment analysis of 14 African languages was made available. We benchmarked and compared current state-of-art transformer models across 12 languages and compared the performance of training one-model-per-language versus single-model-all-languages. We also evaluated the performance of standard multilingual models and their ability to learn and transfer cross-lingual representation from non-African to African languages. Our results show that despite work in low resource modeling, more data still produces better models on a per-language basis. Models explicitly developed for African languages outperform other models on all tasks. Additionally, no one-model-fits-all solution exists for a per-language evaluation of the models evaluated. Moreover, for some languages with a smaller sample size, a larger multilingual model may perform better than a dedicated per-language model for sentiment classification.
* Accepted to be published as part of SIAIA @ AAAI 2023
Evaluating Novel Mask-RCNN Architectures for Ear Mask Segmentation
Nov 05, 2022The human ear is generally universal, collectible, distinct, and permanent. Ear-based biometric recognition is a niche and recent approach that is being explored. For any ear-based biometric algorithm to perform well, ear detection and segmentation need to be accurately performed. While significant work has been done in existing literature for bounding boxes, a lack of approaches output a segmentation mask for ears. This paper trains and compares three newer models to the state-of-the-art MaskRCNN (ResNet 101 +FPN) model across four different datasets. The Average Precision (AP) scores reported show that the newer models outperform the state-of-the-art but no one model performs the best over multiple datasets.
Sentiment Classification of Code-Switched Text using Pre-trained Multilingual Embeddings and Segmentation
Oct 29, 2022


With increasing globalization and immigration, various studies have estimated that about half of the world population is bilingual. Consequently, individuals concurrently use two or more languages or dialects in casual conversational settings. However, most research is natural language processing is focused on monolingual text. To further the work in code-switched sentiment analysis, we propose a multi-step natural language processing algorithm utilizing points of code-switching in mixed text and conduct sentiment analysis around those identified points. The proposed sentiment analysis algorithm uses semantic similarity derived from large pre-trained multilingual models with a handcrafted set of positive and negative words to determine the polarity of code-switched text. The proposed approach outperforms a comparable baseline model by 11.2% for accuracy and 11.64% for F1-score on a Spanish-English dataset. Theoretically, the proposed algorithm can be expanded for sentiment analysis of multiple languages with limited human expertise.
Acoustic-Linguistic Features for Modeling Neurological Task Score in Alzheimer's
Sep 13, 2022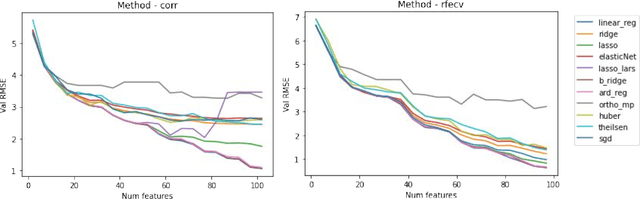
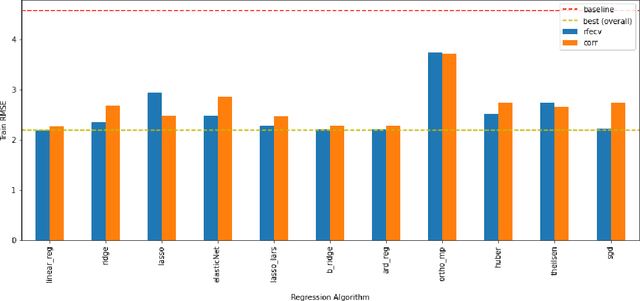
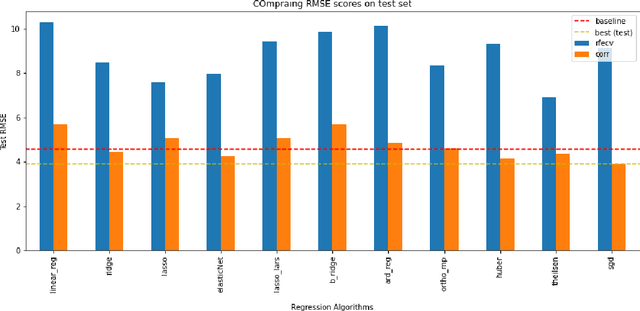
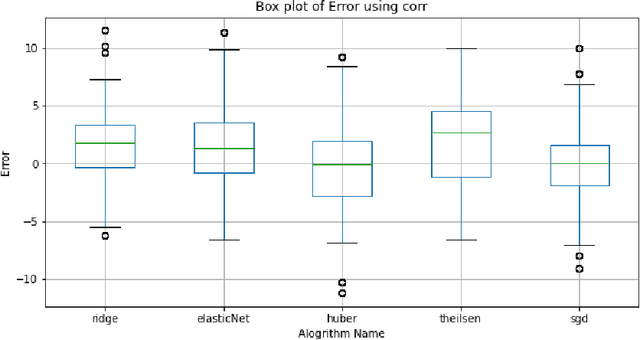
The average life expectancy is increasing globally due to advancements in medical technology, preventive health care, and a growing emphasis on gerontological health. Therefore, developing technologies that detect and track aging-associated disease in cognitive function among older adult populations is imperative. In particular, research related to automatic detection and evaluation of Alzheimer's disease (AD) is critical given the disease's prevalence and the cost of current methods. As AD impacts the acoustics of speech and vocabulary, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of ten linear regression models for predicting Mini-Mental Status Exam scores on the ADReSS challenge dataset. We extracted 13000+ handcrafted and learned features that capture linguistic and acoustic phenomena. Using a subset of 54 top features selected by two methods: (1) recursive elimination and (2) correlation scores, we outperform a state-of-the-art baseline for the same task. Upon scoring and evaluating the statistical significance of each of the selected subset of features for each model, we find that, for the given task, handcrafted linguistic features are more significant than acoustic and learned features.