 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-Supervised Attention Networks and Uncertainty Loss Weighting for Multi-Task Emotion Recognition on Vocal Bursts
Sep 15, 2022
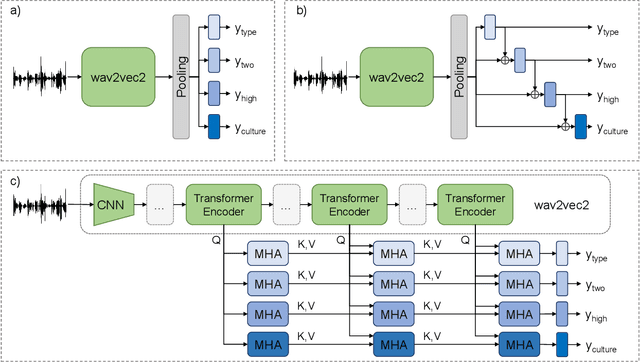
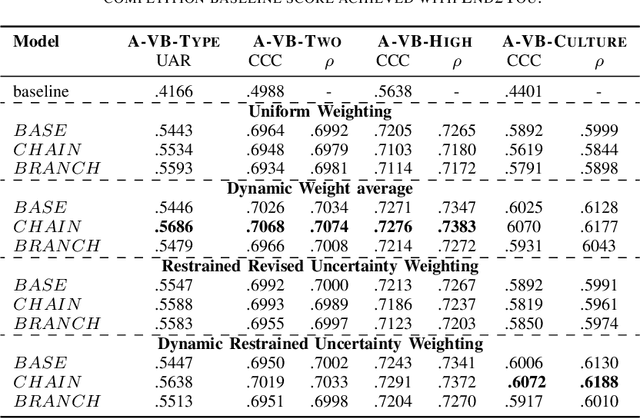

Vocal bursts play an important role in communicating affect, making them valuable for improving speech emotion recognition. Here, we present our approach for classifying vocal bursts and predicting their emotional significance in the ACII Affective Vocal Burst Workshop & Challenge 2022 (A-VB). We use a large self-supervised audio model as shared feature extractor and compare multiple architectures built on classifier chains and attention networks, combined with uncertainty loss weighting strategies. Our approach surpasses the challenge baseline by a wide margin on all four tasks.
Streaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
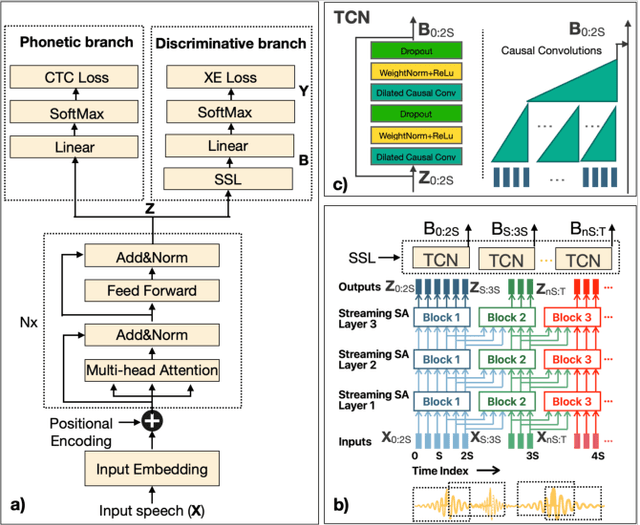
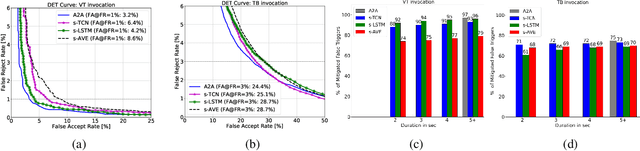
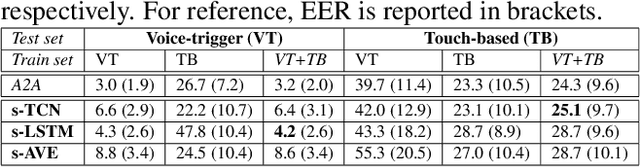
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Oct 12, 2021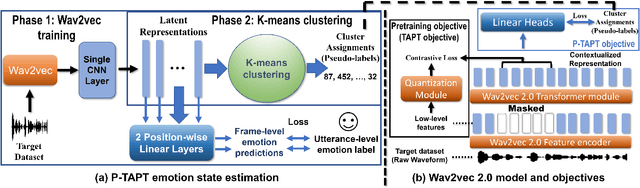
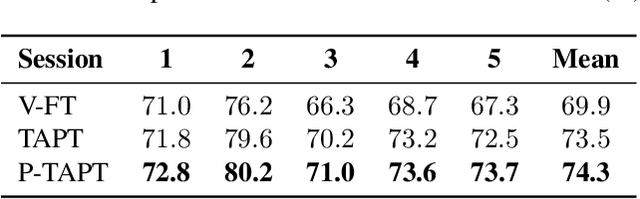
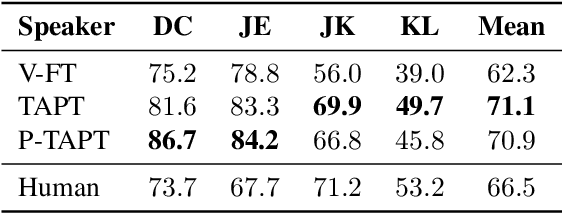

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021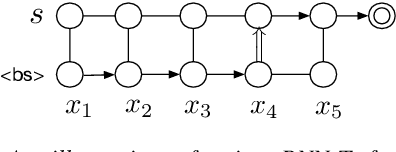
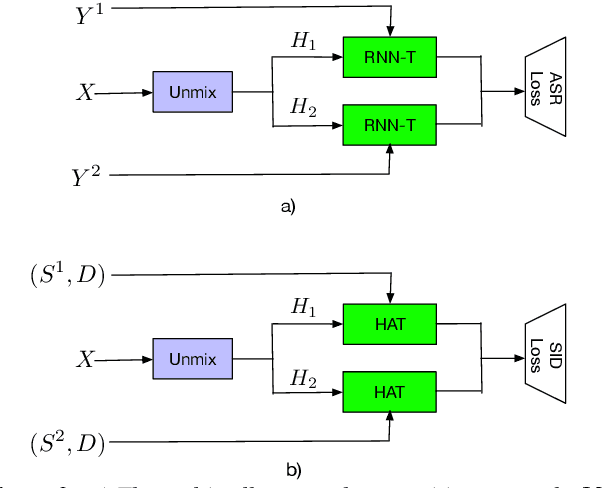
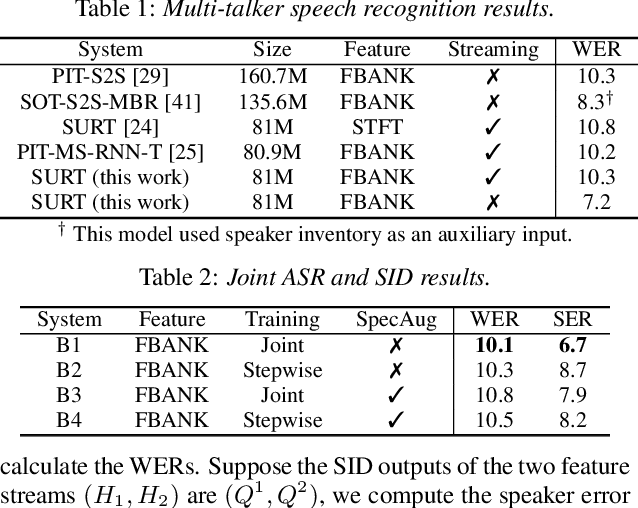
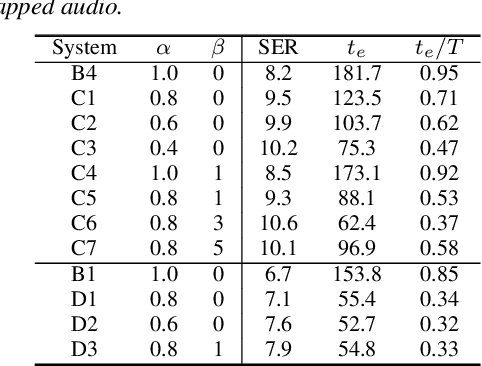
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Disentanglement Learning for Variational Autoencoders Applied to Audio-Visual Speech Enhancement
May 19, 2021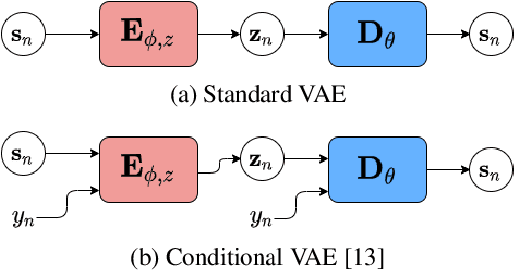

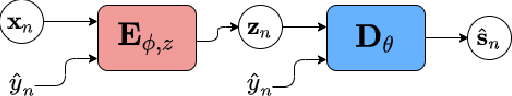
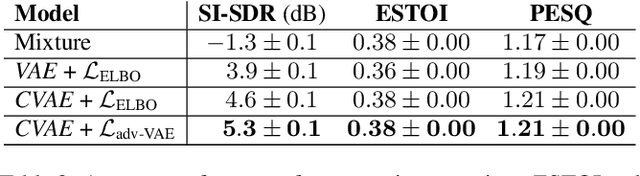
Recently, the standard variational autoencoder has been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. Variational autoencoders have then been conditioned on a label describing a high-level speech attribute (e.g. speech activity) that allows for a more explicit control of speech generation. However, the label is not guaranteed to be disentangled from the other latent variables, which results in limited performance improvements compared to the standard variational autoencoder. In this work, we propose to use an adversarial training scheme for variational autoencoders to disentangle the label from the other latent variables. At training, we use a discriminator that competes with the encoder of the variational autoencoder. Simultaneously, we also use an additional encoder that estimates the label for the decoder of the variational autoencoder, which proves to be crucial to learn disentanglement. We show the benefit of the proposed disentanglement learning when a voice activity label, estimated from visual data, is used for speech enhancement.
Improving non-autoregressive end-to-end speech recognition with pre-trained acoustic and language models
Jan 25, 2022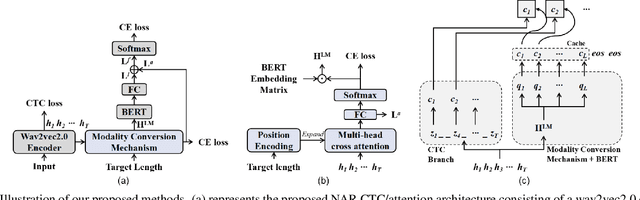
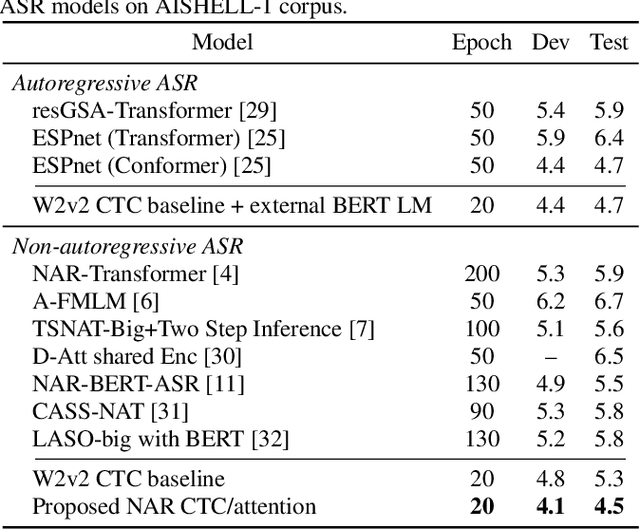
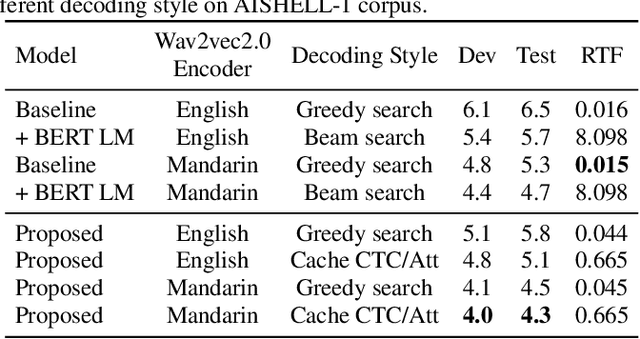
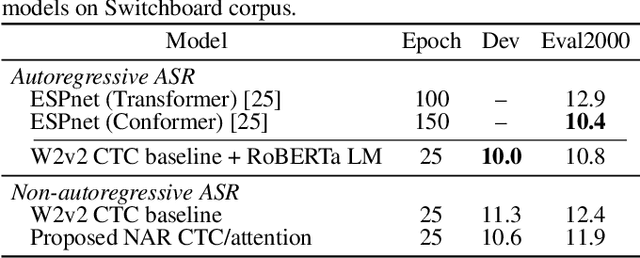
While Transformers have achieved promising results in end-to-end (E2E) automatic speech recognition (ASR), their autoregressive (AR) structure becomes a bottleneck for speeding up the decoding process. For real-world deployment, ASR systems are desired to be highly accurate while achieving fast inference. Non-autoregressive (NAR) models have become a popular alternative due to their fast inference speed, but they still fall behind AR systems in recognition accuracy. To fulfill the two demands, in this paper, we propose a NAR CTC/attention model utilizing both pre-trained acoustic and language models: wav2vec2.0 and BERT. To bridge the modality gap between speech and text representations obtained from the pre-trained models, we design a novel modality conversion mechanism, which is more suitable for logographic languages. During inference, we employ a CTC branch to generate a target length, which enables the BERT to predict tokens in parallel. We also design a cache-based CTC/attention joint decoding method to improve the recognition accuracy while keeping the decoding speed fast. Experimental results show that the proposed NAR model greatly outperforms our strong wav2vec2.0 CTC baseline (15.1% relative CER reduction on AISHELL-1). The proposed NAR model significantly surpasses previous NAR systems on the AISHELL-1 benchmark and shows a potential for English tasks.
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022

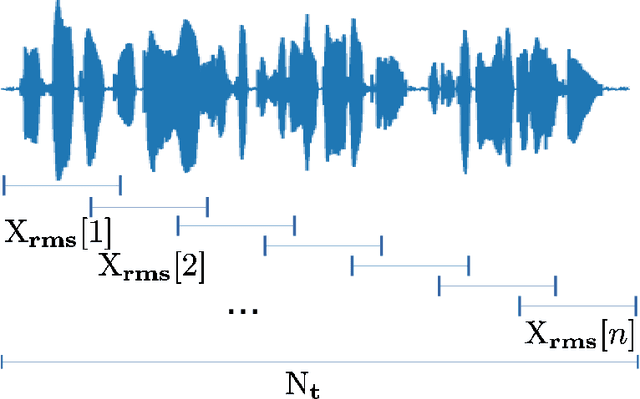
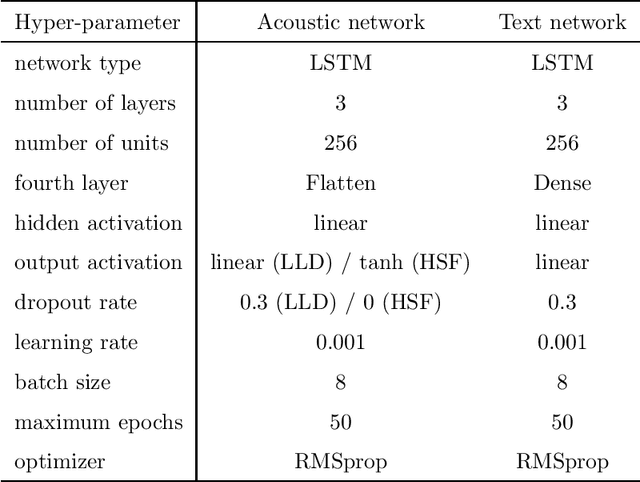
Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Searching for Discriminative Words in Multidimensional Continuous Feature Space
Nov 26, 2022
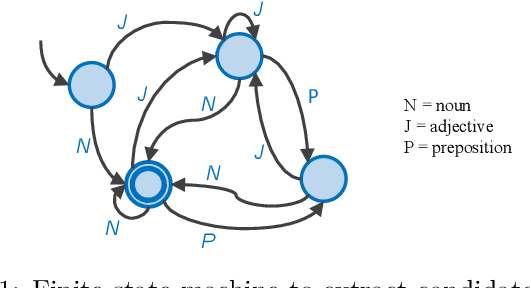
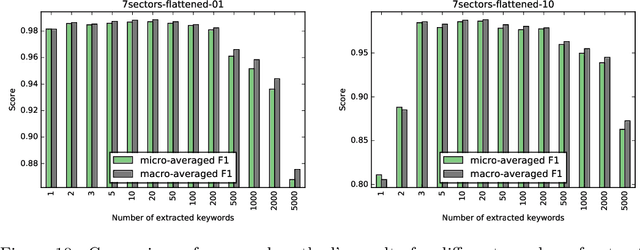
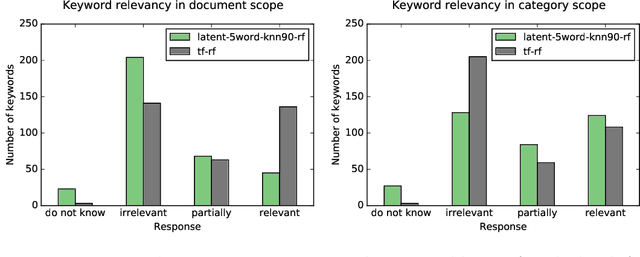
Word feature vectors have been proven to improve many NLP tasks. With recent advances in unsupervised learning of these feature vectors, it became possible to train it with much more data, which also resulted in better quality of learned features. Since it learns joint probability of latent features of words, it has the advantage that we can train it without any prior knowledge about the goal task we want to solve. We aim to evaluate the universal applicability property of feature vectors, which has been already proven to hold for many standard NLP tasks like part-of-speech tagging or syntactic parsing. In our case, we want to understand the topical focus of text documents and design an efficient representation suitable for discriminating different topics. The discriminativeness can be evaluated adequately on text categorisation task. We propose a novel method to extract discriminative keywords from documents. We utilise word feature vectors to understand the relations between words better and also understand the latent topics which are discussed in the text and not mentioned directly but inferred logically. We also present a simple way to calculate document feature vectors out of extracted discriminative words. We evaluate our method on the four most popular datasets for text categorisation. We show how different discriminative metrics influence the overall results. We demonstrate the effectiveness of our approach by achieving state-of-the-art results on text categorisation task using just a small number of extracted keywords. We prove that word feature vectors can substantially improve the topical inference of documents' meaning. We conclude that distributed representation of words can be used to build higher levels of abstraction as we demonstrate and build feature vectors of documents.
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
Mar 28, 2021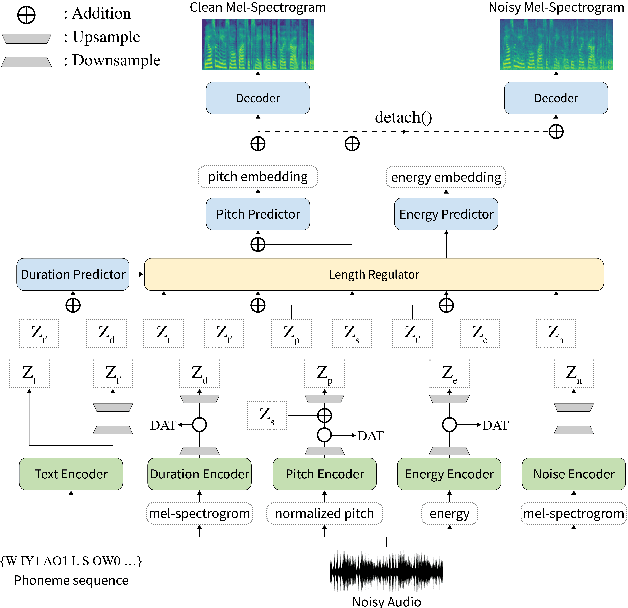
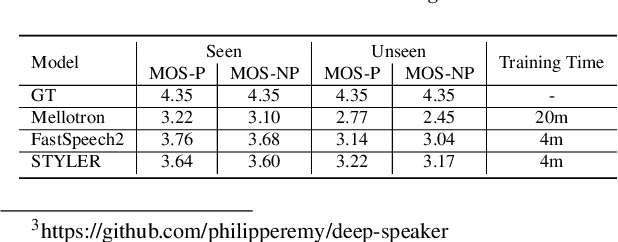
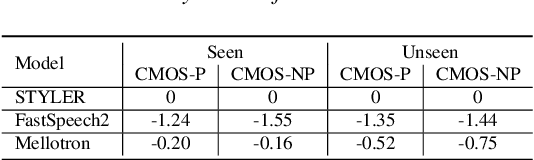
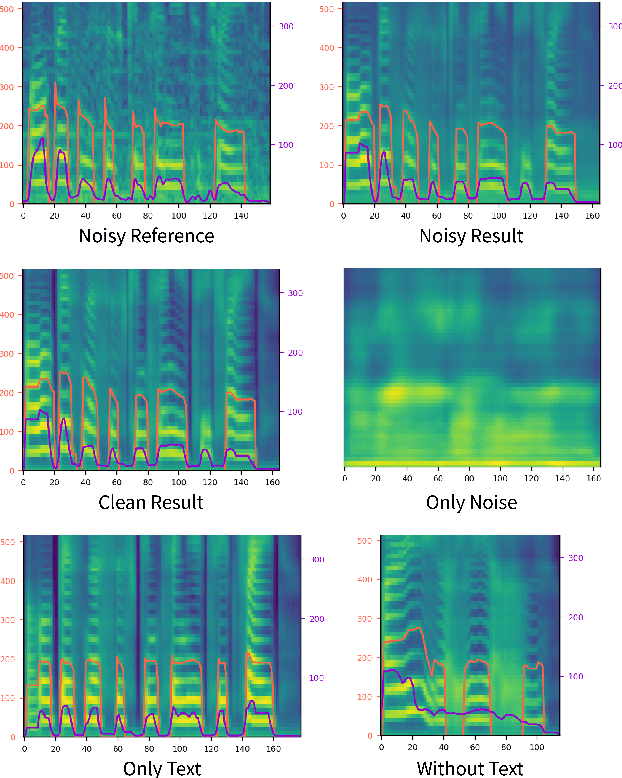
Previous works on neural text-to-speech (TTS) have been tackled on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, none of them has resolved all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable text-to-speech model with robust speech synthesis and high speed. Excluding autoregressive decoding and introducing a novel audio-text aligning method called Mel Calibrator leads speech synthesis more robust on long, unseen data. Disentangled style factor modeling under supervision enlarges the controllability of synthesizing speech with fruitful expressivity. Moreover, our novel noise modeling pipeline using domain adversarial training and Residual Decoding enables noise-robust style transfer, decomposing the noise without any additional label. Our extensive and various experiments demonstrate STYLER's effectiveness in the aspects of speed, robustness, expressiveness, and controllability by comparison with existing neural TTS models and ablation studies. Synthesis samples of our model and experiment results are provided via our demo page.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022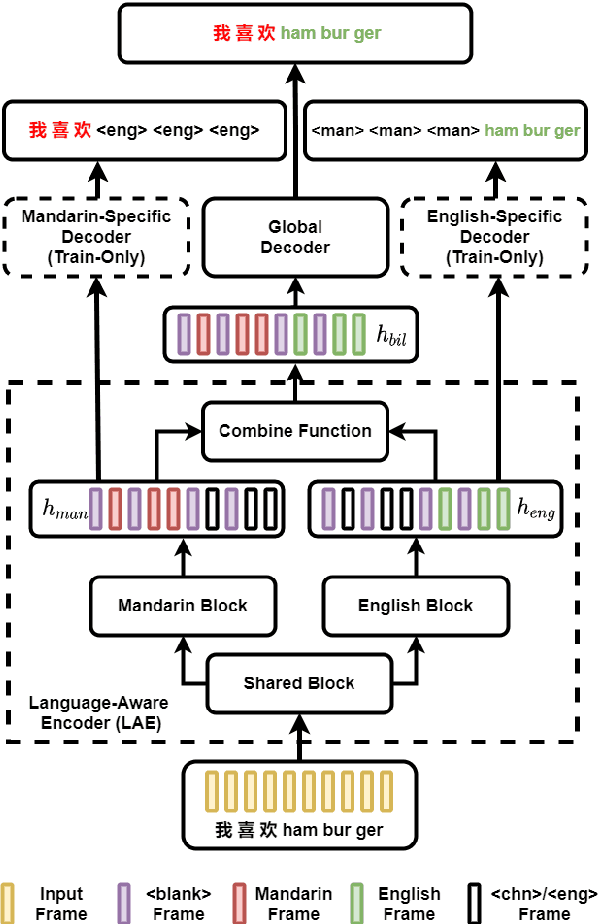
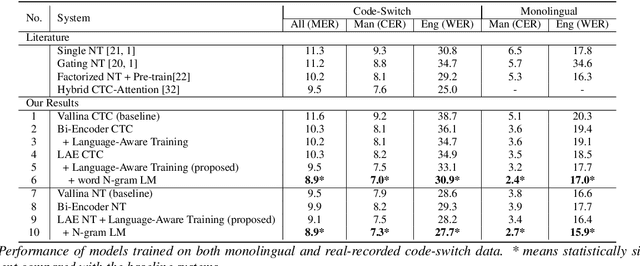
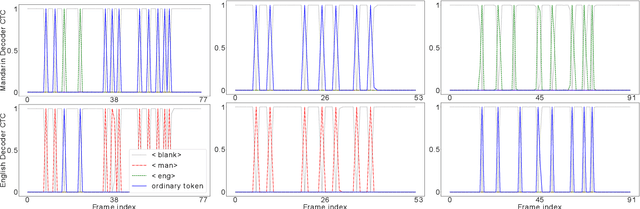
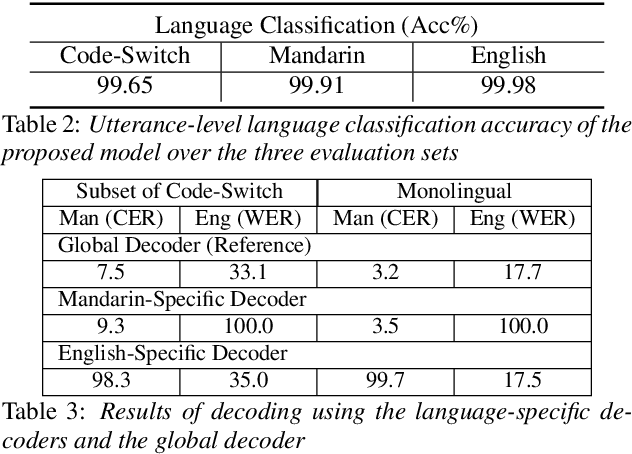
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released